Wizja platformy Azure AI
Odkryj szczegółowe informacje dotyczące przetwarzania obrazów na podstawie analizy obrazów i wideo za pomocą optycznego rozpoznawania znaków i sztucznej inteligencji.
Podnoszenie poziomu projektów przetwarzania obrazów
Wizja platformy Azure AI to ujednolicona usługa oferująca innowacyjne możliwości przetwarzania obrazów. Zapewnij aplikacjom możliwość analizowania obrazów, odczytywania tekstu i wykrywania twarzy za pomocą wstępnie utworzonego tagowania obrazów, wyodrębniania tekstu za pomocą optycznego rozpoznawania znaków (OCR) i odpowiedzialnego rozpoznawania twarzy. Uwzględnij funkcje przetwarzania obrazów w swoich projektach bez konieczności uczenia maszynowego.
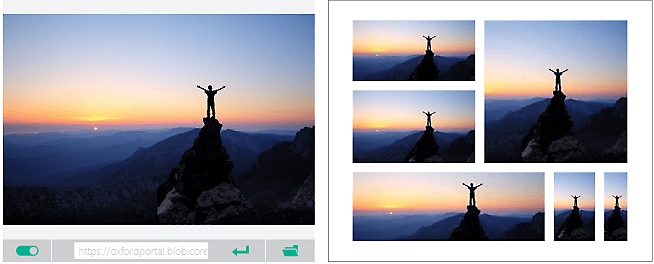
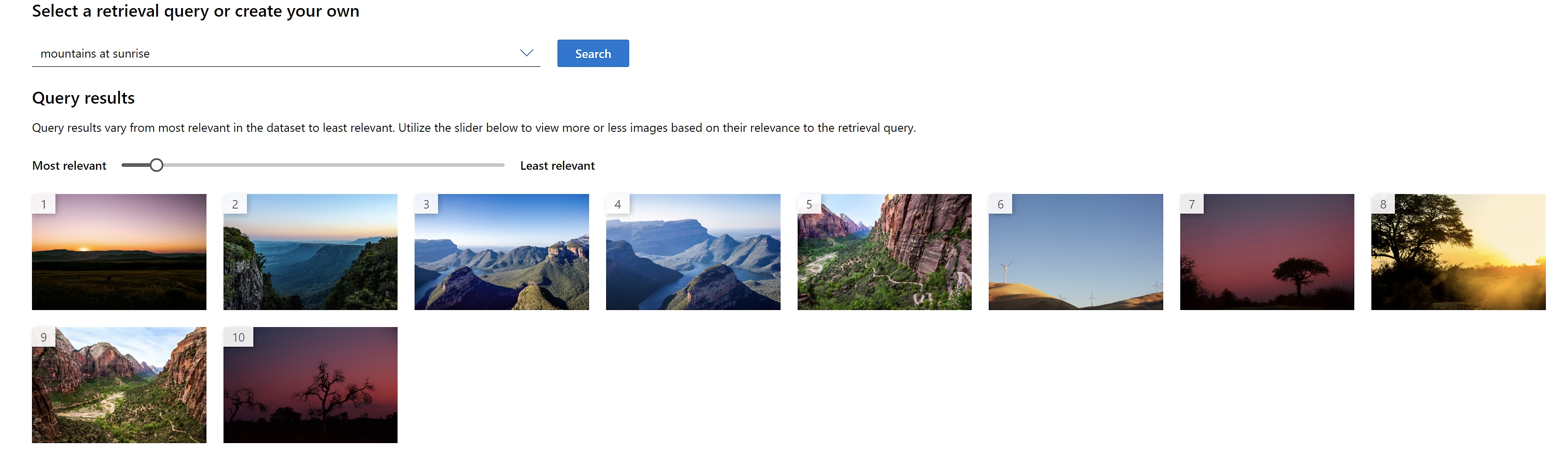
Zwiększ możliwości odnajdywania zawartości za pomocą analizy obrazów
Automatycznie podpisuj obrazy w języku naturalnym, używaj inteligentnych przycinań i klasyfikuj obrazy (w wersji zapoznawczej).


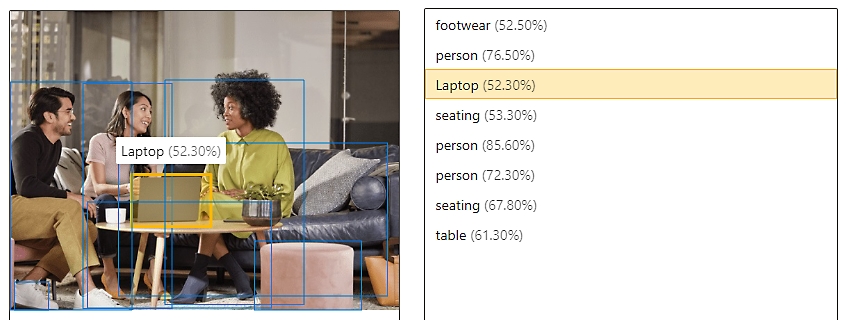


Przesyłanie strumieniowe wideo w czasie rzeczywistym za pomocą analizy przestrzennej
Śledź ruch i analizuj środowiska w czasie rzeczywistym przy użyciu przetwarzania obrazów z analizą obrazów i wykrywaniem obiektów.
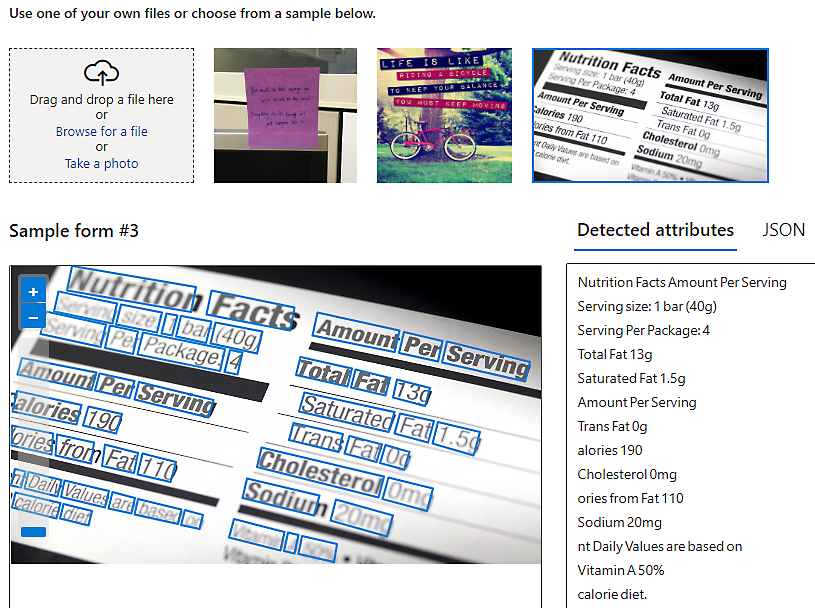
Odczytywanie tekstu z obrazów za pomocą optycznego rozpoznawania znaków (OCR)
Wyodrębnij tekst drukowany i pisany odręcznie z obrazów oraz dokumentów zawierających wiele języków i różne style pisania.
Weryfikowanie tożsamości za pomocą rozpoznawania twarzy
Twórz aplikacje z rozpoznawaniem twarzy, aby zapewnić bezproblemowe i wysoce bezpieczne środowisko użytkownika.
Trenowanie niestandardowych modeli przetwarzania obrazów
Dostosuj klasyfikację obrazów i wykrywanie obiektów, aby dopasować je do swoich potrzeb, korzystając z zaledwie kilku obrazów i bez obniżania dokładności (w wersji zapoznawczej).


Zastosuj sztuczną inteligencję w sposób odpowiedzialny
Uzyskaj jasne wskazówki dotyczące odpowiedzialnego przetwarzania obrazów przez sztuczną inteligencję, aby osiągać cele i uzyskiwać dokładne wyniki.
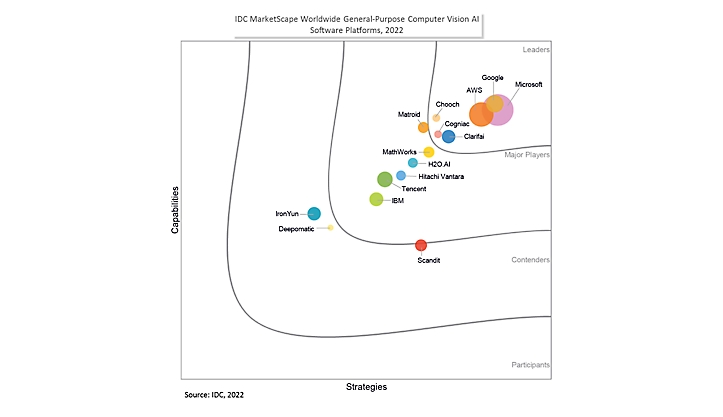
Firma Microsoft została uznana za lidera w raporcie IDC MarketScape: Ogólnoświatowa ocena dostawcy oprogramowania sztucznej inteligencji ogólnego przeznaczenia na platformie sztucznej inteligencji 2022
W raporcie IDC MarketScape oceniono strategie i możliwości firmy Microsoft oraz umieszczono firmę Microsoft w kategorii Liderzy. Uważamy, że to wyróżnienie podkreśla zaangażowanie firmy Microsoft w dostarczanie najnowocześniejszych, odpowiedzialnych i skoncentrowanych na klientach produktów sztucznej inteligencji dla organizacji każdej wielkości i we wszystkich sektorach.

Napędzanie innowacji w zakresie aplikacji za pomocą usług platformy Azure AI w chmurze
Przeczytaj to zlecone badanie z 2022 r. przeprowadzone przez firmę Forrester Consulting, aby dowiedzieć się, jak pomóc deweloperom o dowolnym poziomie umiejętności w Twojej organizacji szybko wdrażać rozwiązania sztucznej inteligencji za pomocą wstępnie utworzonych, gotowych do użycia w środowisku produkcyjnym usług sztucznej inteligencji w chmurze.
Kompleksowe Zabezpieczenia i zgodność, wbudowane
-
Firma Microsoft inwestuje ponad 1 mld USD rocznie w badania i rozwiązania z zakresu cyberbezpieczeństwa.

-
Zatrudniamy ponad 3500 ekspertów w dziedzinie zabezpieczeń, którzy są skoncentrowani na ochronie danych i prywatności.

-
Platforma Azure ma więcej certyfikatów niż jakikolwiek inny dostawca usług w chmurze. Wyświetl kompleksową listę.
-
ISO/IEC
-
CSA/CCM
-
ITAR
-
CJIS
-
HIPAA
-
IRS 1075






-
Cennik usługi Wizja platformy Azure AI
Płać wyłącznie za rzeczywiste użycie bez kosztów ponoszonych z góry. Usługa Wizja platformy Azure AI korzysta z modelu użycia z płatnością zgodnie z rzeczywistym użyciem na podstawie liczby transakcji. Dowiedz się więcej o cenach przetwarzania obrazów i interfejsu API rozpoznawania twarzy.

Rozpocznij pracę przy użyciu bezpłatnego konta platformy Azure
1

2

Po wykorzystaniu środków przejdź na płatność zgodnie z rzeczywistym użyciem, aby kontynuować pracę z użyciem tych samych bezpłatnych usług. Płacisz tylko wtedy, gdy Twoje użycie przekroczy bezpłatne miesięczne przydziały.
3

Cieszy się zaufaniem w różnych branżach według firm każdej wielkości




Firma USA Surfing dołącza do firmy AI Wave
„Trenerzy patrzą na te elementy. Sprawdzają kompresję ciała. Przyglądają się różnym czynnikom dynamicznym. Te modele uczenia maszynowego, mierząc kąty między stawami ciała podczas wykonywania manewrów surfowania, mogą rzeczywiście pomóc trenerom w przekazywaniu opinii” — Kevin Schulz, Aerial Phenom and Surfer, Team USA

Firma KPMG pomaga klientom sektora bankowego identyfikować ryzyko finansowe
Dzięki usłudze Wizja platformy Azure AI firma KPMG znajduje i analizuje obrazy i klipy wideo oraz używa interfejsów API optycznego rozpoznawania znaków (OCR) do identyfikowania ryzyka.

Firma H&R Block przekształca zwroty z podatków za pomocą sztucznej inteligencji platformy Azure
„Daj nam pudełko z dokumentami podatkowymi, a my użyjemy sztucznej inteligencji i uczenia maszynowego, aby umieścić dane w odpowiednich miejscach.”
Sameer Agarwal: Dyrektor IT, H&R Block

Reddit poprawia dostępność i SEO dzięki generowaniu obrazów i podpisów
"Nowo utworzone podpisy obrazów sprawiają, że witryna Reddit jest bardziej dostępna i daje jej uczestnikom więcej możliwości eksplorowania naszych obrazów, angażowania się w konwersacje i ostatecznie nawiązywania relacji i budowania społeczności."
Tiffany Ong: Kierownik produktu ds. środowiska SEO & gościa, Reddit

Często zadawane pytania dotyczące usługi Wizja platformy Azure AI
-
Wyświetl dostępność według regionów.
-
Usługa Wizja platformy Azure AI i inne oferty usług platformy Azure AI gwarantują dostępność na poziomie 99,9%. Dla warstwy cenowej Bezpłatna nie obowiązuje żadna umowa SLA. Zobacz szczegóły umowy SLA.
-
Nie. Firma Microsoft automatycznie usuwa obrazy i nagrania wideo po ich przetworzeniu. Twoje dane nie są używane do trenowania modeli bazowych w celu ich usprawnienia. Dane wideo nie opuszczają twojej lokalizacji, a dane wideo nie są przechowywane w obszarze brzegowym na którym działa kontener. Dowiedz się więcej o ochronie prywatności i warunkach użytkowania.
-
Nie, analiza przestrzenna wykrywa i lokalizuje obecność człowieka w materiałach wideo i generuje pole ograniczenia wokół każdej wykrytej osoby. Modele sztucznej inteligencji nie wykrywają twarzy ani nie określają tożsamości ani danych demograficznych poszczególnych osób.
-
Modele AI analizy przestrzennej wykrywają i śledzą ruchy w strumieniu wideo na podstawie algorytmów, które identyfikują obecność co najmniej jednej osoby przez pole ograniczenia ciała. Dla każdej osoby i pola ograniczenia wykrytego w strefie w polu widzenia kamery model sztucznej inteligencji generuje dane zdarzenia, w tym współrzędne pola ograniczenia ciała osoby’, typ zdarzenia (na przykład wpis strefy lub wyjście lub przekreślanie linii kierunkowej), pseudonimowe identyfikatory do śledzenia pola ograniczenia i wskaźnik ufności wykrywania. Te dane zdarzenia są wysyłane do Twojego własnego wystąpienia usługi Azure IoT Hub.
-
Tak. Ponieważ dostosowywanie modelu zostało zaprojektowane tak, aby było dostosowane do danego scenariusza, należy podać dane oznaczone etykietami, aby wytrenować model.
-
Funkcja dostosowywania modelu usługi jest zoptymalizowana pod kątem szybkiego rozpoznawania istotnych różnic między obrazami, dzięki czemu można rozpocząć tworzenie prototypów modelu przy użyciu niewielkiej ilości danych. Możesz zacząć od zaledwie jednego obrazu na etykietę. Jeśli masz więcej obrazów oznaczonych etykietami, możesz dodać więcej. W zależności od złożoności wymaganego problemu i stopnia dokładności można nadal dodawać dodatkowe obrazy na etykietę, aby ulepszyć model.
-
Jest zarówno witryną, jak i usługą. Witryna służy do uzyskiwania dostępu do interfejsu graficznego do zarządzania zestawami danych, trenowania i oceniania modeli na potrzeby środowiska bez użycia kodu lub alternatywnie do korzystania z interfejsów API przetwarzania obrazów.
-
Obrazy można oznaczać etykietami w usłudze Azure Machine Learning Studio, która jest zintegrowana z programem Vision Studio w celu łatwego eksportowania danych oznaczonych etykietami. Możesz również oznaczyć dane etykietami w formacie pliku COCO i zaimportować plik COCO bezpośrednio w programie Vision Studio. Zapoznaj się z dokumentacją, aby uzyskać szczegółowe informacje.
-
Funkcja dostosowywania modelu dla usługi Wizja platformy Azure AI to następna generacja usługi Custom Vision z ulepszoną dokładnością i możliwościami uczenia się z kilku ujęć. Możesz nadal korzystać z usługi Custom Vision lub przeprowadzić migrację danych szkoleniowych, aby ponownie wytrenować model za pomocą funkcji dostosowywania modelu usługi Wizja platformy Azure AI. Zapoznaj się z dokumentacją, aby uzyskać szczegółowe informacje.
-
Po użyciu usługi Wizja platformy Azure AI do wyodrębniania szczegółowych informacji i tekstu z obrazów i klipów wideo możesz użyć analizy tekstu do analizowania tonacji, usługi Translator do tłumaczenia tekstu na żądany język lub Czytnika immersyjnego do czytania tekstu na głos, dzięki czemu staje się on bardziej dostępny. Powiązane usługi i możliwości obejmują usługę Azure Form Recognizer do wyodrębniania par klucz-wartość i tabel z dokumentów, usługę Azure AI Video Indexer do wyodrębniania zaawansowanych metadanych z plików audio i wideo oraz usługę Content Moderator do wykrywania niechcianego tekstu lub obrazów.