
Azure AI Services
Skapa avancerade, marknadsklara AI-program med färdiga och anpassningsbara API:er och modeller
Distribuera betrodd AI snabbt med en portfölj med AI-tjänster
Vi presenterar Phi-3, de mest kompatibla och kostnadseffektiva serviceavtalen som är tillgängliga och som utvecklats av Microsoft.

Översikt
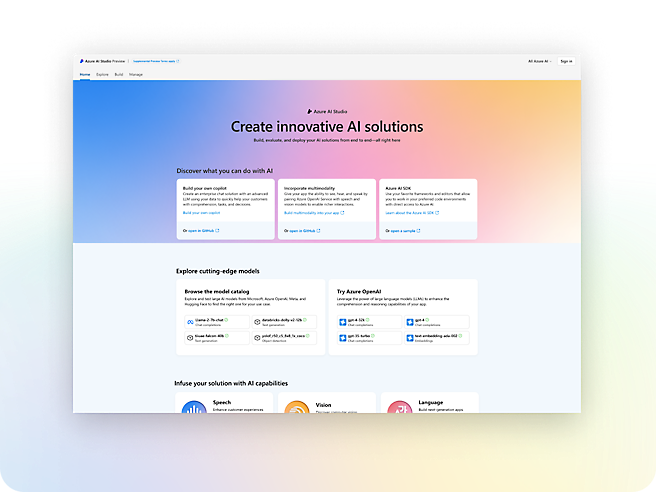
Skapa intelligenta appar med branschledande AI
- Använd snabbt generativ AI i produktionsarbetsbelastningar med studior, SDK:er och API:er.Få en konkurrensfördel genom att skapa AI-appar som drivs av grundmodeller, inklusive de från OpenAI, Meta och Microsoft.Identifiera och minimera skadlig användning med inbyggd ansvarsfull AI, Azure-säkerhet i företagsklass och ansvarsfull AI-verktyg.

Services
Skapa med anpassningsbara API:er och modeller
Azure OpenAI Service
Skapa egna copilot- och generativa AI-program med avancerade språk- och visionsmodeller.
Azure AI-sökning
Hämta de mest relevanta data med nyckelord, vektor och hybridsökning.
Azure AI Innehållsäkerhet
Övervaka text och bilder för att identifiera stötande eller olämpligt innehåll.
Azure AI Translator
Översätt dokument och text i realtid över fler än 100 språk.
Azure AI Speech
Använd branschledande AI-tjänster som tal till text, text till tal, talöversättning och talarigenkänning.
Azure AI-visuellt innehåll
Läs text, analysera bilder och identifiera ansikten med optisk teckenläsning (OCR) och maskininlärning.
Azure AI-språk
Skapa konversationsgränssnitt, sammanfatta dokument och analysera text med hjälp av fördefinierade AI-baserade funktioner.
Azure AI Document Intelligence
Använd avancerad maskininlärning för att extrahera text, nyckel/värde-par, tabeller och strukturer från dokument.
Inbyggd säkerhet och efterlevnad
Microsoft har valt att investera 20 miljarder USD i cybersäkerhet under fem år.
Vi sysselsätter fler än 8 500 experter på säkerhets- och hotinformation i 77 länder.
Azure har en av de största portföljerna för efterlevnadscertifiering i branschen.

Prissättning
Prissättning för Azure AI Services
Utforska flexibla, förbrukningsbaserade priser för AI-tjänsternas familj. Varje tjänst har stöd för olika prisalternativ som passar dina behov.

Hitta din AI-lösning
Upptäck Azure AI – en portfölj med AI-tjänster som utformats för utvecklare och dataforskare.
Kundberättelser
Läs mer om hur användare utnyttjar Azure












KONTOREGISTRERING
Kom igång med ett kostnadsfritt konto
Börja med 200 USD i Azure-kredit.

KONTOREGISTRERING
Kom igång med betalning per användning
Det finns inget förhandsåtagande – avsluta när du vill.