
“In the era of big data, insights collected from cloud services running at the scale of Azure quickly exceed the attention span of humans. It’s critical to identify the right steps to maintain the highest possible quality of service based on the large volume of data collected. In applying this to Azure, we envision infusing AI into our cloud platform and DevOps process, becoming AIOps, to enable the Azure platform to become more self-adaptive, resilient, and efficient. AIOps will also support our engineers to take the right actions more effectively and in a timely manner to continue improving service quality and delighting our customers and partners. This post continues our Advancing Reliability series highlighting initiatives underway to keep improving the reliability of the Azure platform. The post that follows was written by Jian Zhang, our Program Manager overseeing these efforts, as she shares our vision for AIOps, and highlights areas of this AI infusion that are already a reality as part of our end-to-end cloud service management.”—Mark Russinovich, CTO, Azure
This post includes contributions from Principal Data Scientist Manager Yingnong Dang and Partner Group Software Engineering Manager Murali Chintalapati.
As Mark mentioned when he launched this Advancing Reliability blog series, building and operating a global cloud infrastructure at the scale of Azure is a complex task with hundreds of ever-evolving service components, spanning more than 160 datacenters and across more than 60 regions. To rise to this challenge, we have created an AIOps team to collaborate broadly across Azure engineering teams and partnered with Microsoft Research to develop AI solutions to make cloud service management more efficient and more reliable than ever before. We are going to share our vision on the importance of infusing AI into our cloud platform and DevOps process. Gartner referred to something similar as AIOps (pronounced “AI Ops”) and this has become the common term that we use internally, albeit with a larger scope. Today’s post is just the start, as we intend to provide regular updates to share our adoption stories of using AI technologies to support how we build and operate Azure at scale.
Why AIOps?
There are two unique characteristics of cloud services:
- The ever-increasing scale and complexity of the cloud platform and systems
- The ever-changing needs of customers, partners, and their workloads
To build and operate reliable cloud services during this constant state of flux, and to do so as efficiently and effectively as possible, our cloud engineers (including thousands of Azure developers, operations engineers, customer support engineers, and program managers) heavily rely on data to make decisions and take actions. Furthermore, many of these decisions and actions need to be executed automatically as an integral part of our cloud services or our DevOps processes. Streamlining the path from data to decisions to actions involves identifying patterns in the data, reasoning, and making predictions based on historical data, then recommending or even taking actions based on the insights derived from all that underlying data.

Figure 1. Infusing AI into cloud platform and DevOps.
The AIOps vision
AIOps has started to transform the cloud business by improving service quality and customer experience at scale while boosting engineers’ productivity with intelligent tools, driving continuous cost optimization, and ultimately improving the reliability, performance, and efficiency of the platform itself. When we invest in advancing AIOps and related technologies, we see this ultimately provides value in several ways:
- Higher service quality and efficiency: Cloud services will have built-in capabilities of self-monitoring, self-adapting, and self-healing, all with minimal human intervention. Platform-level automation powered by such intelligence will improve service quality (including reliability, and availability, and performance), and service efficiency to deliver the best possible customer experience.
- Higher DevOps productivity: With the automation power of AI and ML, engineers are released from the toil of investigating repeated issues, manually operating and supporting their services, and can instead focus on solving new problems, building new functionality, and work that more directly impacts the customer and partner experience. In practice, AIOps empowers developers and engineers with insights to avoid looking at raw data, thereby improving engineer productivity.
- Higher customer satisfaction: AIOps solutions play a critical role in enabling customers to use, maintain, and troubleshoot their workloads on top of our cloud services as easily as possible. We endeavor to use AIOps to understand customer needs better, in some cases to identify potential pain points and proactively reach out as needed. Data-driven insights into customer workload behavior could flag when Microsoft or the customer needs to take action to prevent issues or apply workarounds. Ultimately, the goal is to improve satisfaction by quickly identifying, mitigating, and fixing issues.
My colleagues Marcus Fontoura, Murali Chintalapati, and Yingnong Dang shared Microsoft’s vision, investments, and sample achievements in this space during the keynote AI for Cloud–Toward Intelligent Cloud Platforms and AIOps at the AAAI-20 Workshop on Cloud Intelligence in conjunction with the 34th AAAI Conference on Artificial Intelligence. The vision was created by a Microsoft AIOps committee across cloud service product groups including Azure, Microsoft 365, Bing, and LinkedIn, as well as Microsoft Research (MSR). In the keynote, we shared a few key areas in which AIOps can be transformative for building and operating cloud systems, as shown in the chart below.
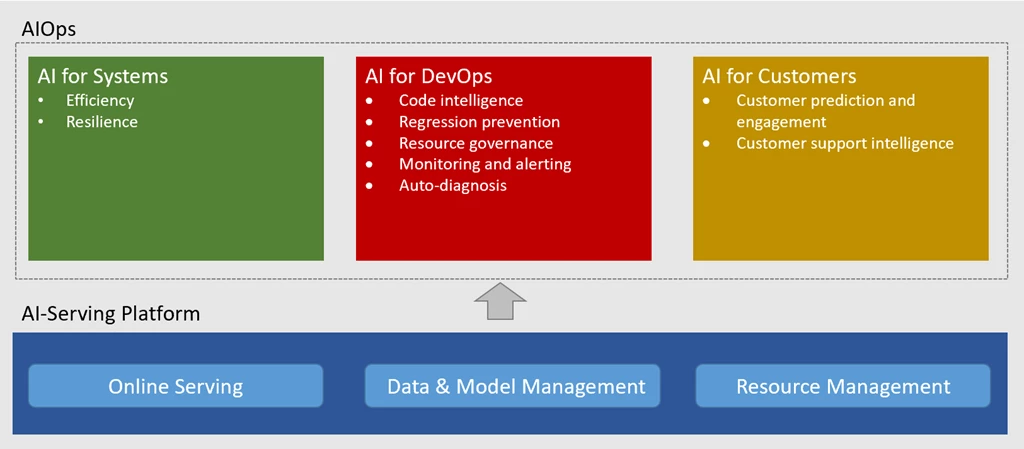
Figure 2. AI for Cloud: AIOps and AI-Serving Platform.
AIOps
Moving beyond our vision, we wanted to start by briefly summarizing our general methodology for building AIOps solutions. A solution in this space always starts with data—measurements of systems, customers, and processes—as the key of any AIOps solution is distilling insights about system behavior, customer behaviors, and DevOps artifacts and processes. The insights could include identifying a problem that is happening now (detect), why it’s happening (diagnose), what will happen in the future (predict), and how to improve (optimize, adjust, and mitigate). Such insights should always be associated with business metrics—customer satisfaction, system quality, and DevOps productivity—and drive actions in line with prioritization determined by the business impact. The actions will also be fed back into the system and process. This feedback could be fully automated (infused into the system) or with humans in the loop (infused into the DevOps process). This overall methodology guided us to build AIOps solutions in three pillars.
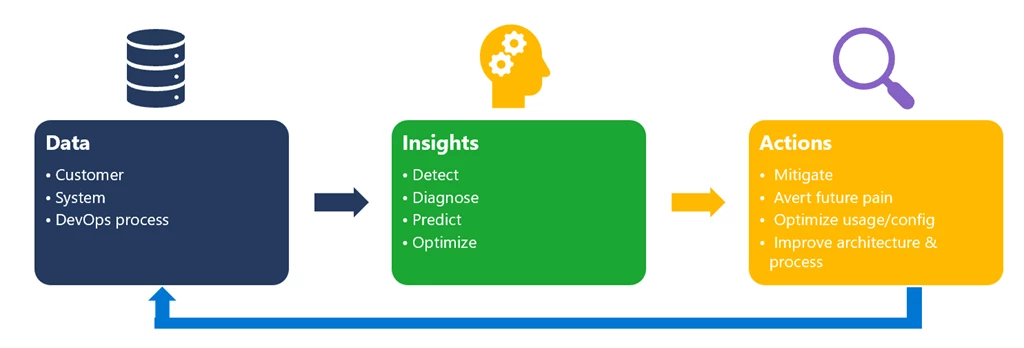
Figure 3. AIOps methodologies: Data, insights, and actions.
AI for systems
Today, we’re introducing several AIOps solutions that are already in use and supporting Azure behind the scenes. The goal is to automate system management to reduce human intervention. As a result, this helps to reduce operational costs, improve system efficiency, and increase customer satisfaction. These solutions have already contributed significantly to the Azure platform availability improvements, especially for Azure IaaS virtual machines (VMs). AIOps solutions contributed in several ways including protecting customers’ workload from host failures through hardware failure prediction and proactive actions like live migration and Project Tardigrade and pre-provisioning VMs to shorten VM creation time.
Of course, engineering improvements and ongoing system innovation also play important roles in the continuous improvement of platform reliability.
- Hardware Failure Prediction is to protect cloud customers from interruptions caused by hardware failures. We shared our story of Improving Azure Virtual Machine resiliency with predictive ML and live migration back in 2018. Microsoft Research and Azure have built a disk failure prediction solution for Azure Compute, triggering the live migration of customer VMs from predicted-to-fail nodes to healthy nodes. We also expanded the prediction to other types of hardware issues including memory and networking router failures. This enables us to perform predictive maintenance for better availability.
- Pre-Provisioning Service in Azure brings VM deployment reliability and latency benefits by creating pre-provisioned VMs. Pre-provisioned VMs are pre-created and partially configured VMs ahead of customer requests for VMs. As we described in the AAAI-20 keynote mentioned above, the Pre-Provisioning Service leverages a prediction engine to predict VM configurations and the number of VMs per configuration to pre-create. This prediction engine applies dynamic models that are trained based on historical and current deployment behaviors and predicts future deployments. Pre-Provisioning Service uses this prediction to create and manage VM pools per VM configuration. Pre-Provisioning Service resizes the pool of VMs by destroying or adding VMs as prescribed by the latest predictions. Once a VM matching the customer’s request is identified, the VM is assigned from the pre-created pool to the customer’s subscription.
AI for DevOps
AI can boost engineering productivity and help in shipping high-quality services with speed. Below are a few examples of AI for DevOps solutions.
- Incident management is an important aspect of cloud service management—identifying and mitigating rare but inevitable platform outages. A typical incident management procedure consists of multiple stages including detection, engagement, and mitigation stages. Time spent in each stage is used as a Key Performance Indicator (KPI) to measure and drive rapid issue resolution. KPIs include time to detect (TTD), time to engage (TTE), and time to mitigate (TTM).
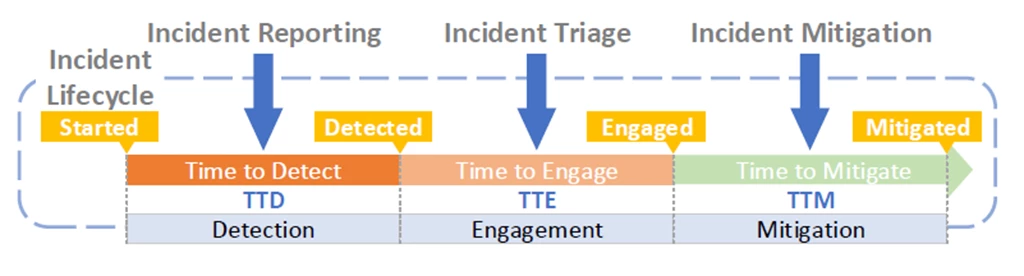
Figure 4. Incident management procedures.
As shared in AIOps Innovations in Incident Management for Cloud Services at the AAAI-20 conference, we have developed AI-based solutions that enable engineers not only to detect issues early but also to identify the right team(s) to engage and therefore mitigate as quickly as possible. Tight integration into the platform enables end-to-end touchless mitigation for some scenarios, which considerably reduces customer impact and therefore improves the overall customer experience.
- Anomaly Detection provides an end-to-end monitoring and anomaly detection solution for Azure IaaS. The detection solution targets a broad spectrum of anomaly patterns that includes not only generic patterns defined by thresholds, but also patterns which are typically more difficult to detect such as leaking patterns (for example, memory leaks) and emerging patterns (not a spike, but increasing with fluctuations over a longer term). Insights generated by the anomaly detection solutions are injected into the existing Azure DevOps platform and processes, for example, alerting through the telemetry platform, incident management platform, and, in some cases, triggering automated communications to impacted customers. This helps us detect issues as early as possible.
For an example that has already made its way into a customer-facing feature, Dynamic Threshold is an ML-based anomaly detection model. It is a feature of Azure Monitor used through the Azure portal or through the ARM API. Dynamic Threshold allows users to tune their detection sensitivity, including specifying how many violation points will trigger a monitoring alert.
- Safe Deployment serves as an intelligent global “watchdog” for the safe rollout of Azure infrastructure components. We built a system, code name Gandalf, that analyzes temporal and spatial correlation to capture latent issues that happened hours or even days after the rollout. This helps to identify suspicious rollouts (during a sea of ongoing rollouts), which is common for Azure scenarios, and helps prevent the issue propagating and therefore prevents impact to additional customers. We provided details on our safe deployment practices in this earlier blog post and went into more detail about how Gandalf works in our USENIX NSDI 2020 paper and slide deck.
AI for customers
To improve the Azure customer experience, we have been developing AI solutions to power the full lifecycle of customer management. For example, a decision support system has been developed to guide customers towards the best selection of support resources by leveraging the customer’s service selection and verbatim summary of the problem experienced. This helps shorten the time it takes to get customers and partners the right guidance and support that they need.
AI-serving platform
To achieve greater efficiencies in managing a global-scale cloud, we have been investing in building systems that support using AI to optimize cloud resource usage and therefore the customer experience. One example is Resource Central (RC), an AI-serving platform for Azure that we described in Communications of the ACM. It collects telemetry from Azure containers and servers, learns from their prior behaviors, and, when requested, produces predictions of their future behaviors. We are already using RC to predict many characteristics of Azure Compute workloads accurately, including resource procurement and allocation, all of which helps to improve system performance and efficiency.
Looking towards the future
We have shared our vision of AI infusion into the Azure platform and our DevOps processes and highlighted several solutions that are already in use to improve service quality across a range of areas. Look to us to share more details of our internal AI and ML solutions for even more intelligent cloud management in the future. We’re confident that these are the right investment solutions to improve our effectiveness and efficiency as a cloud provider, including improving the reliability and performance of the Azure platform itself.





