
Introduction
Internet video is growing at an extraordinary pace – The Cisco VNI Forecast expects that 70% of all consumer Internet traffic will be video content in 2014, rising to 79% by 2018. Already comprising a majority of the Internet traffic seen across the globe, video content is taking over the World Wide Web, and out of this growth arises the problem of discovering content. The Internet was designed around text-based documents, and as such, has mature infrastructure to encourage and enable the search and discovery of text across the entire web. Video files, on the other hand, are not natively “searchable”, and usually require complex classification systems primarily powered by massive amounts of manually-tagged metadata. But what if there was a way to extract this kind of meaningful metadata automatically? Azure Media Indexer is a media processor that leverages natural language processing (NLP) technology from Microsoft Research to make media files and content searchable by exposing this meaningful metadata to the end-user automatically in the form of a keyword file (XML), a set of closed caption files (SAMI/TTML), and a powerful binary index file (AIB). With the growth of multimedia comes an increased focus on the accessibility of video content to users with hearing impairment. The status quo is for all videos to be manually transcribed at high costs in order to create closed caption tracks. Azure Media Indexer’s speech recognition engine automatically creates a time-aligned subtitle track for any English spoken words in the input media file. This transforms an arduous, manual process requiring numerous man hours into an automated job. By utilizing the output files of Azure Media Indexer in conjunction with a search engine like SQL Server or Apache Lucene/Solr, developers can create a full-text search experience. Users will then be able to simply search content libraries with a text query, and get back a page of results which can seek to the timestamp in which the word is uttered. This deep integration of metadata and videos enables high-quality scenarios that reduce the friction between search of vast content libraries and the desired results. The implementation of this search layer is out-of-scope for this blog post, but look for upcoming posts on the Azure blog detailing how to create a search portal for your media files using Azure Media Indexer.
Indexing Your First Asset
With Azure Media Indexer, users can run indexing jobs on a variety of file types either from their local file system or from Azure Media Services. For your first Azure Media Indexer job, you will start with a file from your local disk, upload it to Azure Media Services, and process it in the Azure cloud. For this tutorial, let’s use this sample Channel9 video. Save the MP4 file to your computer and rename it to Index.mp4. Let’s assume for the purpose of this tutorial that your target video file can be found at the following path: “C:Users<>VideosIndex.mp4”. The completed sample project can be downloaded here.
Note: This tutorial assumes you already have an Azure Media Services account
Setting up your Project
Begin by creating a new C# Console Application Project in Visual Studio 2013 (File > New > Project or Ctrl+Shift+N):
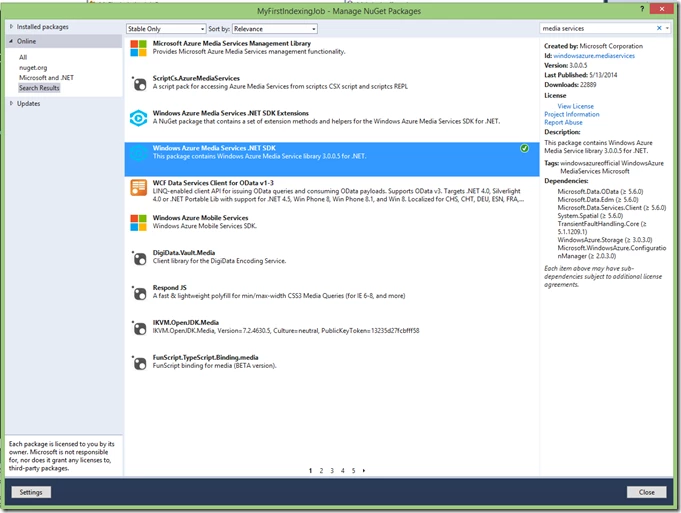
Next, install the Azure Media Services SDK using NuGet by right-clicking the projects References folder in the Solution Explorer and clicking “Manage NuGet Packages”. Enter “media services” into the search box and install “Windows Azure Media Services .NET SDK”.
Finally, open the App.config file and add an appSettings section as shown below. Be sure to enter your Azure Media Services credentials in the appropriate key-value pairs.
Note: The Task Configuration schema has changed since this initial release. To learn more, read the release notes for Azure Media Indexer v1.2
-->
Creating an Asset
An asset is the Azure Media Services container for media files. An asset contains the media file itself, along with any other required files such as manifest files for streaming or thumbnail files for previewing. In this case, you are going to create an asset file that holds your video file using the .NET SDK. You can also upload assets using the Azure Management Portal. Media processing jobs take an input asset and save the results into a specified output asset. First you need to import some dependencies and declare some constants that will come in handy inProgram.cs:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.WindowsAzure.MediaServices.Client;
using System.Configuration;
using System.IO;
using System.Threading;
namespace MyFirstIndexingJob
{
class Program
{
private static CloudMediaContext _context = null;
private const string _mediaProcessorName = "Azure Media Indexer";
private const string _configurationFile = "<>";
private static readonly string _accountName =
ConfigurationManager.AppSettings["accountName"];
private static readonly string _accountKey =
ConfigurationManager.AppSettings["accountKey"];
You will need to instantiate a CloudMediaContext object to establish a programmatic connection to the Media Services cloud. This will allow you to upload the file by first creating a new Asset and then uploading the file as an AssetFile within the Asset. First, add the following lines to your Main function, specifying where to find the video, and where to put the output files:
Note: if you want to use the same paths as this example project, replace <<USERNAME>> with your local Windows username
static void Main(string[] args)
{
_context = new CloudMediaContext(_accountName, _accountKey);
var inputFile = @“C:\Users\<>\Videos\Index.mp4”;
var outputFolder = @“C:\Users\<>\Desktop”;
RunIndexingJob(inputFile, outputFolder, _configurationFile);
}
Then, you can begin your RunIndexingJob function, and add the first few lines:
static bool RunIndexingJob(string inputFilePath, string outputFolder, string configurationFile = “”)
{
IAsset asset = _context.Assets.Create(“Indexer_Asset”, AssetCreationOptions.None);
var assetFile = asset.AssetFiles.Create(Path.GetFileName(inputFilePath));
assetFile.Upload(inputFilePath);
}
Submitting an Indexing Job
With your file now in the Azure Media Services cloud as an Asset, the next step is obtain a reference to the Azure Content Indexer media processor and create the Job itself. Jobs on Media Services are made up of one or more tasks that specify the details of a processing operation (encoding, packaging, etc.). Tasks optionally take a task configuration file specifying details about the task itself. In this instance, you will create an Indexing task on your new Asset using an optional configuration file called “default.config” containing some useful metadata, explained below.
Task Configuration
Note: The Task Configuration schema has changed since this initial release. To learn more, read the release notes for Azure Media Indexer v1.2
A task configuration file for Azure Content Indexer is an XML file containing key-value pairs which improve the speech recognition accuracy. In this release of Azure Media Indexer, the configuration details are able to describe the title and description of the input media file, allowing the adaptive natural language processing engine to augment its vocabulary based on the specific subject matter at hand. For example, if you have a video about Geico, it may be useful to include this term in your task configuration file. This will reduce the likelihood of a transcription of “guy co” in place of the desired proper noun “Geico”. Furthermore, if you have a title including the term “hypertension”, for example, the engine searches the Internet for related documents with which the language model can be further augmented. This will reduce the likelihood that the spoken term “aortic aneurism” will be misinterpreted as something unintelligible like “A or tick canner is um,” greatly increasing the accuracy of your output files.
Note: Best results are achieved using 4-5 sentences spanning the title and description keys.
Create a new config file by right-clicking the Project, clicking Add > New Item, and choosing XML file. Paste the following text into the new file, and save it as “default.config”. In this case, use the information from the Channel9 website to add the optional “title” and “description” keys in the configuration file to increase your accuracy:
Be sure to go back to the top of your Program.cs file and change the “<>” _configurationFile string to the path of your new default.config file.
Tip: you can drag-and-drop the file onto your editor to easily paste the absolute path of the rile from the Solution Explorer.
Creating a Job
With the configuration file in place, continue working on your RunIndexingJob method, now start creating the Job itself, along with its component tasks:
IMediaProcessor indexer = GetLatestMediaProcessorByName(_mediaProcessorName);
IJob job = _context.Jobs.Create("My Indexing Job");
string configuration = "";
if (!String.IsNullOrEmpty(configurationFile))
{
configuration = File.ReadAllText(configurationFile);
}
ITask task = job.Tasks.AddNew("Indexing task",
indexer,
configuration,
TaskOptions.None);
// Specify the input asset to be indexed.
task.InputAssets.Add(asset);
// Add an output asset to contain the results of the job.
task.OutputAssets.AddNew("Indexed video", AssetCreationOptions.None);
Next, define this useful helper method at the bottom of the file to retrieve the latest version of a given Media Processor:
private static IMediaProcessor GetLatestMediaProcessorByName(string mediaProcessorName)
{
var processor = _context.MediaProcessors
.Where(p => p.Name == mediaProcessorName)
.ToList()
.OrderBy(p => new Version(p.Version))
.LastOrDefault();
if (processor == null)
throw new ArgumentException(string.Format("Unknown media processor", mediaProcessorName));
return processor;
}
You are just about ready to submit() this job, but first, it will be helpful to attach an instance of EventHandler to your job so you can track its progress in real-time.
job.StateChanged += new EventHandler(StateChanged);
job.Submit();
// Check job execution and wait for job to finish.
Task progressPrintTask = new Task(() =>
{
IJob jobQuery = null;
do
{
var progressContext = new CloudMediaContext(_accountName,
_accountKey);
jobQuery = progressContext.Jobs.Where(j => j.Id == job.Id).First();
Console.WriteLine(string.Format("{0}\t{1}\t{2}",
DateTime.Now,
jobQuery.State,
jobQuery.Tasks[0].Progress));
Thread.Sleep(10000);
}
while (jobQuery.State != JobState.Finished &&
jobQuery.State != JobState.Error &&
jobQuery.State != JobState.Canceled);
});
progressPrintTask.Start();
// Check job execution and wait for job to finish.
Task progressJobTask = job.GetExecutionProgressTask(CancellationToken.None);
progressJobTask.Wait();
// If job state is Error, the event handling
// method for job progress should log errors. Here you check
// for error state and exit if needed.
if (job.State == JobState.Error)
{
Console.WriteLine("Exiting method due to job error.");
return false;
}
// Download the job outputs.
DownloadAsset(job.OutputMediaAssets.First(), outputFolder);
return true;
}
// helper function: event handler for Job State
static void StateChanged(object sender, JobStateChangedEventArgs e)
{
Console.WriteLine("Job state changed event:");
Console.WriteLine(" Previous state: " + e.PreviousState);
Console.WriteLine(" Current state: " + e.CurrentState);
switch (e.CurrentState)
{
case JobState.Finished:
Console.WriteLine();
Console.WriteLine("Job finished. Please wait for local tasks/downloads");
break;
case JobState.Canceling:
case JobState.Queued:
case JobState.Scheduled:
case JobState.Processing:
Console.WriteLine("Please wait...\n");
break;
case JobState.Canceled:
Console.WriteLine("Job is canceled.\n");
break;
case JobState.Error:
Console.WriteLine("Job failed.\n");
break;
default:
break;
}
}
// helper method to download the output assets
static void DownloadAsset(IAsset asset, string outputDirectory)
{
foreach (IAssetFile file in asset.AssetFiles)
{
file.Download(Path.Combine(outputDirectory, file.Name));
}
}
Outputs
There are four outputs to every indexing file:
- Closed caption file in SAMI format
- Closed caption file in Timed Text Markup Language (TTML) format
- Keyword file (XML)
- Audio indexing blob file (AIB) for use with SQL server
In this post, you simply downloaded all of these files to a local folder. In future blog posts, you will explore the specific usage scenarios of these various outputs. At a high level, the SAMI and TTML files contain structured data about the words spoken along with their timestamps in the video, and can be used as rough-draft captioning of the video. The keyword file contains algorithmically-determined keywords form the input video along with their confidence level. The AIB file contains a binary data structure which describes the same data as the SAMI and TTML files, along with extensive word alternatives for words whose transcription was not 100% confident. This enables rich search functionality, and can greatly increase the accuracy of your output. In order to use the AIB file, you will need a SQL Server instance with the Azure Media Indexer SQL Add-on. Feel free to reach out to us with any questions or comments at indexer@microsoft.com. Read Part 2 of this blog series on Azure Media Indexer to learn more about this scenario.
Other Information
- While this blog post was designed to introduce Azure Media Indexer, it does not cover all of the usage scenarios. For example, you can submit jobs with a manifest file to support the indexing of multiple files.
- Indexer is best utilized for scenarios optimizing for accuracy rather than speed, taking approximately 3 x (input duration). This is suboptimal for scenarios that require near real-time results.
- The completed sample project can be downloaded here.
- The minimum job duration is 5 minutes, any shorter jobs will be rounded up and billed accordingly
- Photo courtesy Miguel Angel Riaño Trujillo (original photo in full color)





