
Azure Databricks
KI mit Apache Spark™-basierten Analysen entwickeln.

Big Data-Analysen und KI mit optimierter Apache Spark-Umgebung
Gewinnen Sie Erkenntnisse aus Ihren Daten, erstellen Sie KI-Lösungen mit Azure Databricks, richten Sie Ihre Apache Spark™-Umgebung in wenigen Minuten ein, skalieren Sie automatisch, und arbeiten Sie in einem interaktiven Arbeitsbereich gemeinsam mit anderen an Projekten. Azure Databricks unterstützt Python, Scala, R, Java und SQL sowie Data Science-Frameworks und -Bibliotheken, z. B. TensorFlow, PyTorch und scikit-learn.
Apache Spark™ ist ein eingetragenes Markenzeichen der Apache Software Foundation.
Zuverlässige Datentechnik
Umfangreiche Datenverarbeitung für Batch- und Streamingworkloads.
Analyse für alle Daten
Vollständige und aktuelle Daten durch Analysen.
Kollaborative Data Science
Einfachere und schnellere Data Science für große Datasets.
Open-Source-basiert
Schnelle, optimierte Apache Spark-Umgebung.
Schneller Einstieg mit einer optimierten Apache Spark-Umgebung
Azure Databricks umfasst die aktuellste Version von Apache Spark, sodass Sie nahtlose Integrationen mit Open-Source-Bibliotheken durchführen können. Erstellen Sie Cluster per Spinup, und führen Sie schnelle Erstellungen in einer vollständig verwalteten Apache Spark-Umgebung mit dem globalen Umfang und der weltweiten Verfügbarkeit von Azure durch. Cluster werden eingerichtet, konfiguriert und anschließend optimiert, um eine hohe Zuverlässigkeit und Leistung zu gewährleisten, ohne dass Überwachung erforderlich ist. Nutzen sie die automatische Skalierung und das automatische Beenden, um die Gesamtkosten zu senken.
Erhöhte Produktivität mit einem gemeinsamen Arbeitsbereich und beliebten Sprachen
Arbeiten Sie auf einer offenen, einheitlichen Plattform effektiv zusammen. Sie können sämtliche Analyseworkloads ausführen – ganz gleich, ob Sie wissenschaftliche Fachkraft für Daten, technische Fachkraft für Daten oder Business Analyst sind. Verwenden Sie Ihre bevorzugte Sprache – egal ob Python, Scala, R oder SQL. Einfache Versionskontrolle von Notebooks mit GitHub und Azure DevOps.
Leistungsstarke Machine-Learning-Funktionen für Big Data
Nutzen Sie komplexe automatisierte Machine Learning-Funktionen dank des integrierten Diensts Azure Machine Learning, um schnell geeignete Algorithmen und Hyperparameter zu bestimmen. Vereinfachen Sie die Verwaltung, Überwachung und das Aktualisieren von Machine Learning-Modellen, die von der Cloud bis zum Edge bereitgestellt werden. Azure Machine Learning bietet zudem eine zentrale Registrierung für Ihre Experimente, Machine-Learning-Pipelines und -Modelle.
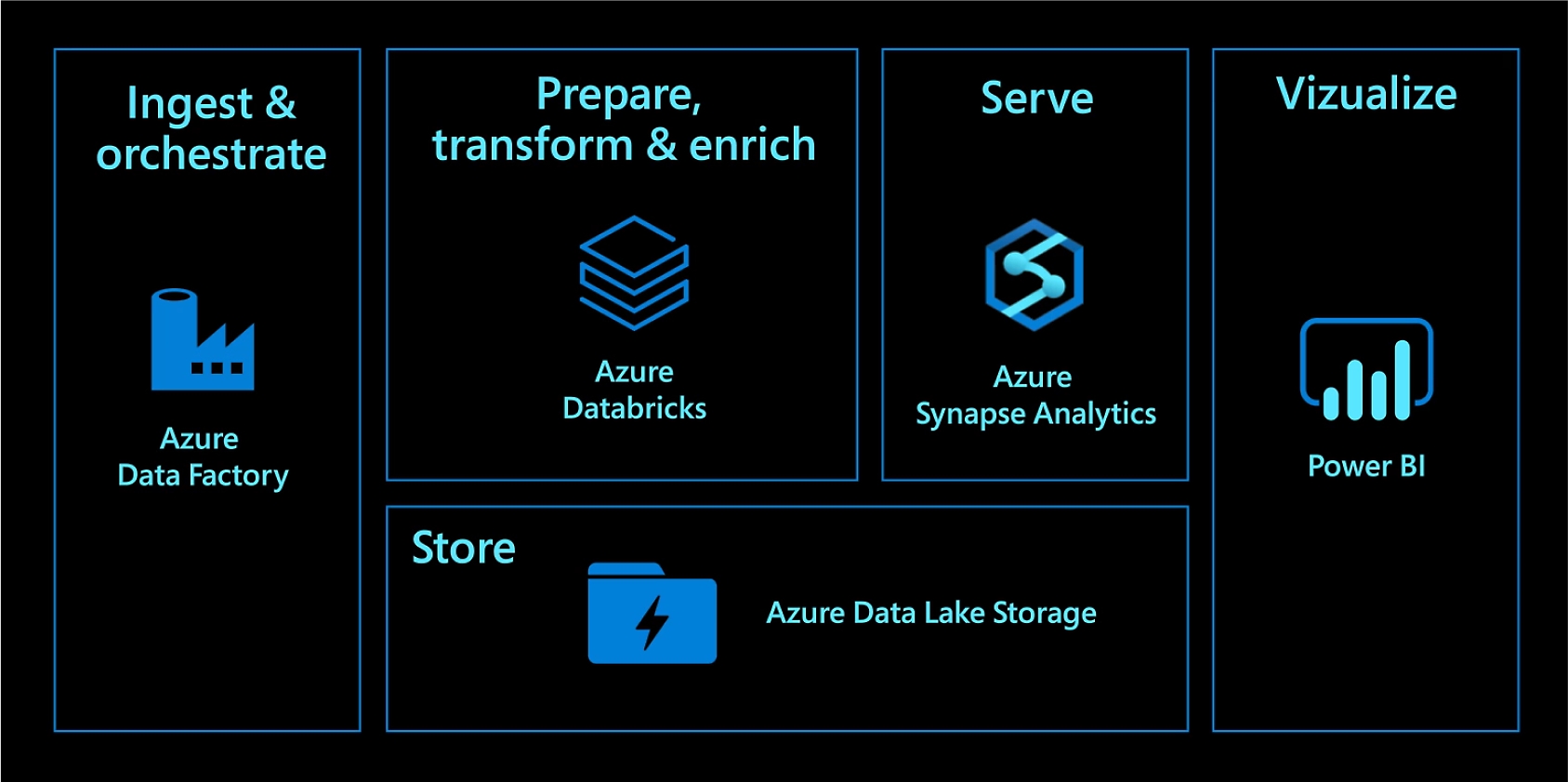
Leistungsstarkes, modernes Data Warehousing
Kombinieren Sie Daten jeden Umfangs, und gewinnen Sie Erkenntnisse mithilfe von Analysedashboards und Betriebsberichten. Automatisieren Sie die Datenverschiebung mit Azure Data Factory, laden Sie die Daten anschließend in Azure Data Lake Storage, transformieren und bereinigen Sie diese mit Azure Databricks, und stellen Sie sie für die Analyse mit Azure Synapse Analytics bereit. Modernisieren Sie Ihr Data Warehouse in der Cloud für unübertroffene Leistung und Skalierbarkeit.
Wichtige Dienstfunktionen
-
Optimierte Spark-Engine
Nutzen Sie die einfache Datenverarbeitung in einer automatisch skalierenden Infrastruktur, und profitieren Sie dabei dank der hochoptimierten Apache Spark™-Engine von einer bis zu 50-fachen Leistungssteigerung.
-
Machine-Learning-Runtime
Mit einem Klick können Sie auf vorkonfigurierte Machine-Learning-Umgebungen zugreifen, um Ihre Machine-Learning-Prozesse mit modernen und gängigen Frameworks wie PyTorch, TensorFlow und scikit-learn zu erweitern.


-
MLflow
Überwachen Sie Experimente, geben Sie diese frei, reproduzieren Sie Testläufe, und verwalten Sie Modelle gemeinsam in einem zentralen Repository.
-
Auswahl von Sprachen
Verwenden Sie Ihre bevorzugte Sprache, z. B. Python, Scala, R, Spark SQL und .NET, für serverlose oder bereitgestellte Computeressourcen.


-
Kollaborative Notebooks
Greifen Sie schnell auf Daten zu, und analysieren Sie diese, um Informationen zu gewinnen und weiterzugeben. Darüber hinaus können Sie Modelle gemeinsam mit den Tools und Sprachen Ihrer Wahl entwickeln.
-
Delta Lake
Gestalten Sie vorhandene Data Lakes zuverlässiger und skalierbarer, indem Sie eine Open-Source-Speicherschicht für Transaktionen nutzen, die für den gesamten Datenlebenszyklus konzipiert ist.


-
Native Integration mit Azure-Diensten
Ergänzen Sie Ihre Analyse- und Machine-Learning-Lösung durch die enge Verzahnung mit Azure-Diensten wie Azure Data Factory, Azure Data Lake Storage, Azure Machine Learning und Power BI.
-
Interaktive Arbeitsbereiche
Ermöglichen Sie die nahtlose Zusammenarbeit zwischen wissenschaftlichen Fachkräften für Daten, technischen Fachkräften für Daten und Business Analysts.


-
Sicherheit der Businessklasse
Mit den benutzerfreundlichen, nativen Sicherheitsfeatures werden Ihre Daten am Speicherort geschützt, sodass die Arbeitsbereiche für Analysen für Tausende Benutzer und Datasets stets konform, privat und isoliert sind.
-
Bereit für die Produktion
Führen Sie unternehmenskritische Datenworkloads skalierbar auf einer vertrauenswürdigen Datenplattform aus, die Integrationen für CI/CD und Überwachungslösungen bietet.


Lernen Sie aus Beispielen für Lösungsarchitekturen

Data Science und Machine Learning mit Azure Databricks
Gewinnen Sie mühelos Erkenntnisse aus Livestreamingdaten. Erfassen Sie kontinuierlich Daten von jedem IoT-Gerät oder Protokolle von Websiteclickstreams, und verarbeiten Sie diese nahezu in Echtzeit.

Moderne Analysearchitektur mit Azure Databricks
Verwandeln Sie Ihre Daten mit erstklassigen Tools für maschinelles Lernen in verwertbare Informationen. Diese Architektur ermöglicht es Ihnen, beliebige Daten in beliebiger Größe zu kombinieren und maßgeschneiderte Machine Learning-Modelle zu erstellen und bereitzustellen.

Pipelines für Erfassung, ETL und Streamverarbeitung mit Azure Databricks
Beschleunigen und verwalten Sie den gesamten Machine-Learning-Lebenszyklus mit Azure Databricks, MLflow und Azure Machine Learning, um Machine-Learning-Anwendungen zu entwickeln, zu teilen, bereitzustellen und zu verwalten.
Integrierte umfassende Sicherheit und Compliance
-
Microsoft investiert über 1 Milliarde USD pro Jahr in die Forschung und Entwicklung der Cybersecurity.


-
Microsoft beschäftigt mehr als 3.500 Sicherheitsexperten, die ausschließlich den Schutz und die Sicherheit Ihrer Daten im Blick haben.

-
Azure verfügt über mehr Zertifizierungen als jeder andere Cloudanbieter. Sehen Sie sich die vollständige Liste an.
Weitere Informationen zu Azure Databricks-Produkten und -Diensten

Azure Data Factory
Hybrid-Datenintegrationsdienst für einfachere ETL-Vorgänge im großen Stil.

Azure Data Lake Storage Gen2
Hochgradig skalierbare, sichere Data Lake-Funktionalität auf Basis von Azure Blob Storage.

Azure Machine Learning
Machine-Learning-Dienst für Unternehmen zur schnelleren Erstellung und Bereitstellung von Modellen.

Power BI
Fügen Sie Ihren Anwendungen Analysen und interaktive Berichte hinzu.
-
Preis für Azure Databricks
Erstellen Sie Cluster schnell per Spinup, und skalieren Sie bedarfsbasiert automatisch hoch oder herunter. Sehen Sie sich alle Azure Databricks-Preisoptionen an.

Erste Schritte mit einem kostenlosen Azure-Konto
1

2

Nachdem Ihr Guthaben aufgebraucht ist, wechseln Sie zur nutzungsbasierten Zahlung, um Ihr Wachstum mit den gleichen kostenlosen Dienstleistungen voranzutreiben. Es fallen nur Gebühren an, wenn Sie die kostenlosen monatlichen Kontingente überschreiten.
3

Community und Azure-Support
Im MSDN-Forum und auf Stack Overflowkönnen Sie Fragen stellen und Unterstützung und Antworten von Microsoft-Techniker*innen und Azure-Expert*innen aus der Community erhalten. Alternativ können Sie sich an den Azure-Supportwenden.
Beliebte Labs und Vorlagen
Führen Sie eigenverantwortliche Labs durch, und lernen Sie beliebte Schnellstartvorlagen für häufige Konfigurationen kennen, die von Microsoft und der Community erstellt wurden.
Ressourcen zu Azure Databricks
Häufig gestellte Fragen zu Azure Databricks
-
Die Azure Databricks-SLA sichert eine Verfügbarkeit von 99,95 % zu.
-
Eine Databricks-Einheit (Databricks Unit, DBU) ist eine Verarbeitungskapazitätseinheit pro Stunde, deren Nutzung pro Sekunde abgerechnet wird.
-
Ein Datentechnikworkload ist ein Auftrag, der den Cluster, in dem er ausgeführt wird, sowohl automatisch startet als auch beendet. Ein Workload kann z. B. durch den Azure Databricks-Auftragsplaner ausgelöst werden, der einen Apache Spark-Cluster exklusiv für den Auftrag startet und diesen beendet, sobald der Auftrag abgeschlossen ist.
Der Datenanalyseworkload ist nicht automatisiert. Befehle in Azure Databricks-Notebooks werden z. B. in Apache Spark-Clustern ausgeführt, bis sie manuell beendet werden. Mehrere Benutzer können einen Cluster gemeinsam verwenden, um ihn zu analysieren.