
Composite indexes were introduced in Azure Cosmos DB at Microsoft Build 2019. With our latest service update, additional query types can now leverage composite indexes. In this post, we’ll explore composite indexes and highlight common use cases.
Index types in Azure Cosmos DB
Azure Cosmos DB currently has the following index types that are used for the following types of queries:
Range indexes:
- Equality queries
- Range queries
- ORDER BY queries on a single property
- JOIN queries
Spatial indexes:
- Geospatial functions
Composite indexes:
- ORDER BY queries on multiple properties
- Queries with a filter as well as an ORDER BY clause
- Queries with a filter on two or more properties
Composite index use cases
By default, Azure Cosmos DB will create a range index on every property. For many workloads, these indexes are enough, and no further optimizations are necessary. Composite indexes can be added in addition to the default range indexes. Composite indexes have both a path and order (ASC or DESC) defined for each property within the composite index.
ORDER BY queries on multiple properties
If a query has an ORDER BY clause with two or more properties, a composite index is required. For example, the following query requires a composite index defined on age and name (age ASC, name ASC):
SELECT * FROM c ORDER BY c.age ASC, c.name ASC
This query will sort all results in ascending order by the value of the age property. If two documents have the same age value, the query will sort the documents by name.
Queries with a filter as well as an ORDER BY clause
If a query has a filter as well as an ORDER BY clause on different properties, a composite index will improve performance. For example, the following query will require fewer request units (RU’s) if a composite index on name and age is defined and the query is updated to include the name in the ORDER BY clause:
Original query utilizing range index:
SELECT * FROM c WHERE c.name = “Tim” ORDER BY c.age ASC
Revised query utilizing a composite index on name and age:
SELECT * FROM c WHERE c.name = “Tim” ORDER BY c.name ASC, c.age ASC
While a composite index will significantly improve query performance, you can still run the original query successfully without a composite index. When you run the revised query with a composite index, it will sort documents by the age property. Since all documents matching the filter have the same name value, the query will return them in ascending order by age.
Queries with a filter on multiple properties
If a query has a filter with two or more properties, adding a composite index will improve performance.
Consider the following query:
SELECT * FROM c WHERE c.name = “Tim” and c.age > 18
In the absence of a composite index on (name ASC, and age ASC), we will utilize a range index for this query. We can improve the efficiency of this query by creating a composite index for name and age.
Queries with multiple equality filters and a maximum of one range filter (such as >,<, <=, >=, !=) will utilize the composite index. In some cases, if a query can’t fully utilize a composite index, it will use a combination of the defined composite indexes and range indexes. For more information, reference our indexing policy documentation.
Composite index performance benefits
We can run some sample queries to highlight the performance benefits of composite indexes. We will use a nutrition dataset that is used in Azure Cosmos DB labs.
In this example, we will optimize a query that has a filter as well as an ORDER BY clause. We will start with the default indexing policy which indexes all properties with a range index. Executing the following query as referenced in the image below in the Azure Portal, we observe the query metrics:
Query metrics:
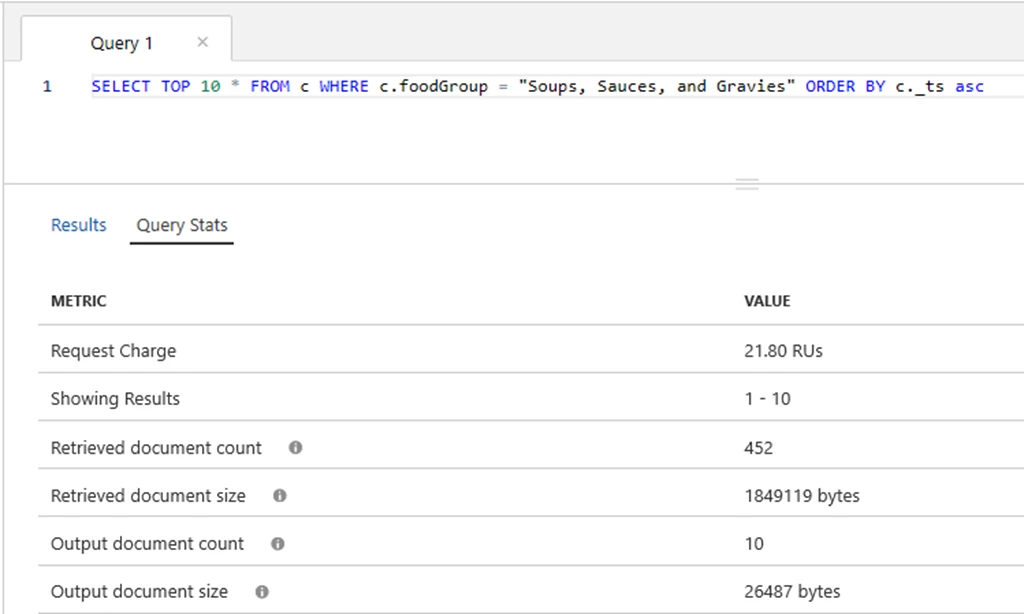
This query, with the default indexing policy, required 21.8 RU’s.
Adding a composite index on foodGroup and _ts and updating the query text to include foodGroup in the ORDER BY clause significantly reduced the query’s RU charge.
Query metrics:
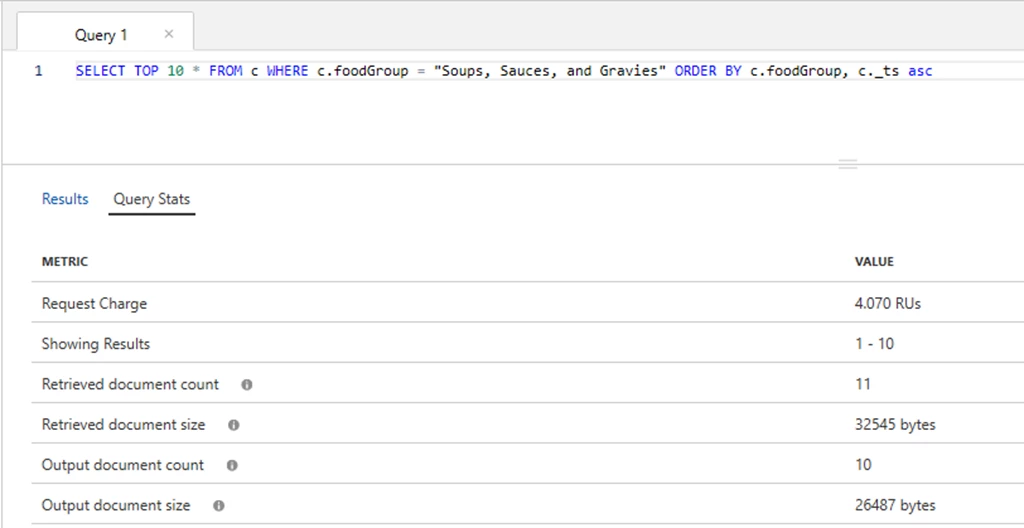
After adding a composite index, the query’s RU charge decreased from 21.8 RU’s to only 4.07 RU’s. This query optimization will be particularly impactful as the total data size increases. The benefits of a composite index are significant when the properties in the ORDER BY clause have a high cardinality.
Creating composite indexes
You can learn more about creating composite indexes in this documentation. It’s simple to update the indexing policy directly through the Azure Portal. While creating a composite index for data that’s already in Azure Cosmos DB, the index update will utilize the RU’s leftover from normal operations. After the new indexing policy is defined, Azure Cosmos DB will automatically index properties with a composite index as they’re written.
Explore whether composite indexes will improve RU utilization for your existing workloads on Azure Cosmos DB.





