
Azure AI Services
Bygg banebrytende, markedsklare kunstig intelligens-programmer med bruksklare og tilpassbare API-er og modeller
Distribuer pålitelig kunstig intelligens raskt med en portefølje av kunstig intelligens-tjenester
Vi introduserer Phi-3, de mest avanserte og kostnadseffektive SLM-ene som er tilgjengelig, utviklet av Microsoft.

Oversikt
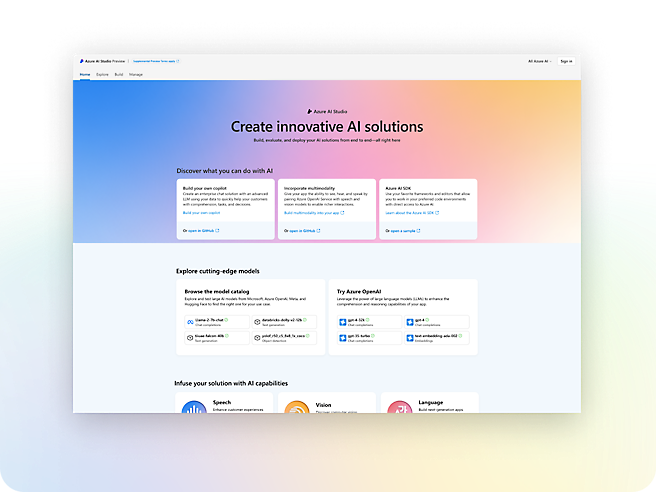
Bygg intelligente apper med bransjeledende kunstig intelligens
- Integrer raskt generativ kunstig intelligens i produksjonsarbeidsbelastninger ved hjelp av studioer, SDK-er og API-er.Få et konkurransefortrinn ved å bygge kunstig intelligens-apper drevet av grunnleggende modeller, inkludert de fra OpenAI, Meta og Microsoft.Oppdag og reduser skadelig bruk med innebygd ansvarlig kunstig intelligens, Azure-sikkerhet i foretaksklassen og verktøy for ansvarlig kunstig intelligens.

Tjenester
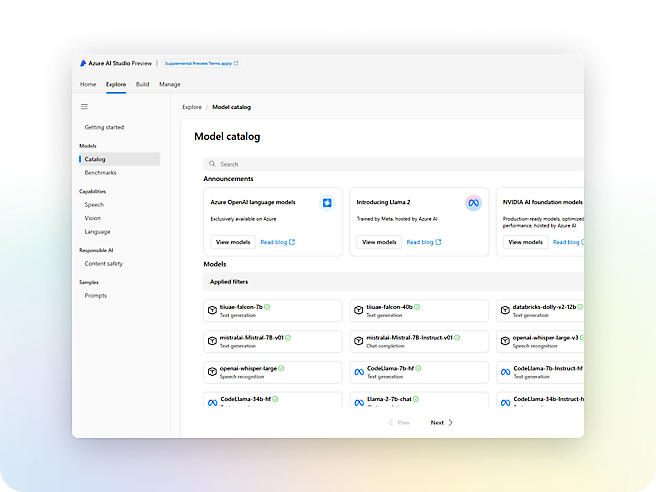
Bygg med API-er og modeller som kan tilpasses
Azure OpenAI Service
Bygg dine egne copilot- og generative kunstig intelligens-programmer med banebrytende språk- og visjonsmodeller.
Azure AI Search
Hent de mest relevante dataene ved hjelp av nøkkelord, vektor og hybridsøk.
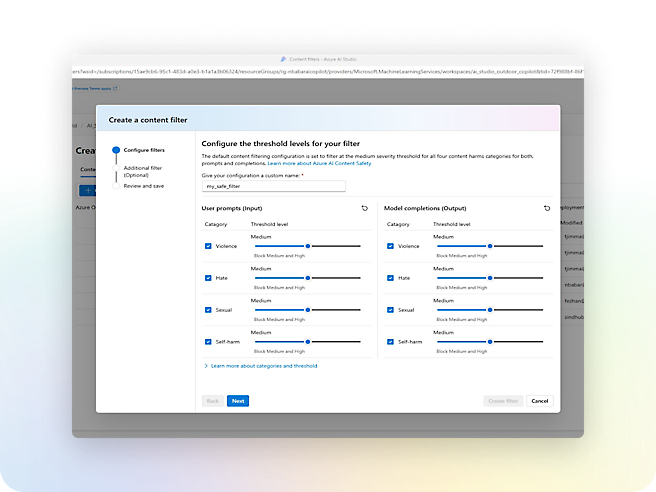
Azure AI Content Safety
Overvåk tekst og bilder for å oppdage støtende eller upassende innhold.
Azure AI Translator
Oversett dokumenter og tekst i sanntid på mer enn 100 språk.
Azure AI Speech
Bruk bransjeledende tjenester for kunstig intelligens, slik som tale til tekst, tekst til tale, taleoversettelse og talergjenkjenning.
Azure AI Vision
Les tekst, analyser bilder og oppdag ansikter med optisk tegngjenkjenning (OCR) og maskinlæring.
Azure AI Language
Bygg samtalegrensesnitt, oppsummer dokumenter og analyser tekst ved hjelp av forhåndsbygde funksjoner drevet av kunstig intelligens.
Azure AI Document Intelligence
Bruk avansert maskinlæring til uttrekking av tekst, nøkkel/verdipar, tabeller og strukturer fra dokumenter.
Innebygd sikkerhet og forskriftssamsvar
Microsoft har forpliktet seg til å investere USD 20 milliarder i cybersikkerhet over en periode på fem år.
Vi har mer enn 8500 eksperter på sikkerhet og trusselinformasjon i 77 land.
Azure har en av bransjens største porteføljer for sertifisering av forskriftssamsvar.

Priser
Priser for tjenester innen Azure kunstig intelligens
Utforsk fleksible, forbruksbaserte priser for familien av kunstig intelligens-tjenester. Hver tjeneste støtter ulike prisalternativer som passer dine behov.

Finn din kunstig intelligens-løsning
Oppdag Azure AI – en portefølje med tjenester for kunstig intelligens designet for utviklere og dataeksperter.
Kundehistorier
Finn ut hvordan kunder bruker Azure






RESSURSER
Finn ut mer om Azure kunstig intelligenstjenester






OPPRETTING AV KONTO
Kom i gang med en gratis konto
Start med USD 200 i Azure-kreditt.

KONTOREGISTRERING
Kom i gang med betale for forbruk priser
Ingen forhåndsforpliktelser – avbryt når som helst.