

借助优化的 Apache Spark 实现大数据分析和 AI
使用 Azure Databricks,即可解锁所有数据的见解并构建人工智能 (AI) 解决方案,在数分钟内设置 Apache Spark™ 环境,自动缩放以及在交互式工作区中协作共享项目。Azure Databricks 支持 Python、Scala、R、Java 和 SQL,以及数据科学框架和库(包括 TensorFlow、PyTorch 和 scikit-learn)。
Apache Spark™ 是 Apache Software Foundation 的商标。
可靠的数据工程
用于批处理和流式处理工作负载的大规模数据处理。
用于所有数据的分析
支持对最完整和最新数据的分析。
协作式数据科学
在大型数据集上简化和加速数据科学。
植根于开放源代码
速度快且经过优化的 Apache Spark 环境。
经过优化的 Apache Spark 环境快速入门
Azure Databricks 提供最新版本的 Apache Spark,使你可以与开放源代码库无缝集成。利用 Azure 的全球规模和可用性,在完全托管的 Apache Spark 环境中快速启动群集和构建群集。设置、配置并调试群集,以确保提供可靠性和性能,而无需监视。利用自动缩放和自动终止来提高总拥有成本 (TCO)。
通过共享工作区和常用语言大幅提高工作效率
无论你是数据科学家、数据工程师还是业务分析师,都可以在开放且统一的平台上有效地协作,以运行所有类型的分析工作负载。使用所选语言(包括 Python、Scala、R 和 SQL)进行构建。通过 GitHub 和 Azure DevOps,轻松实现笔记本的版本控制。
增强机器学习对大数据的处理能力
使用集成的 Azure 机器学习访问高级自动化机器学习功能,以快速识别合适的算法和超参数。简化从云端部署到边缘的机器学习模型的管理、监视和更新。Azure 机器学习还为试验、机器学习管道和模型提供中央注册表。
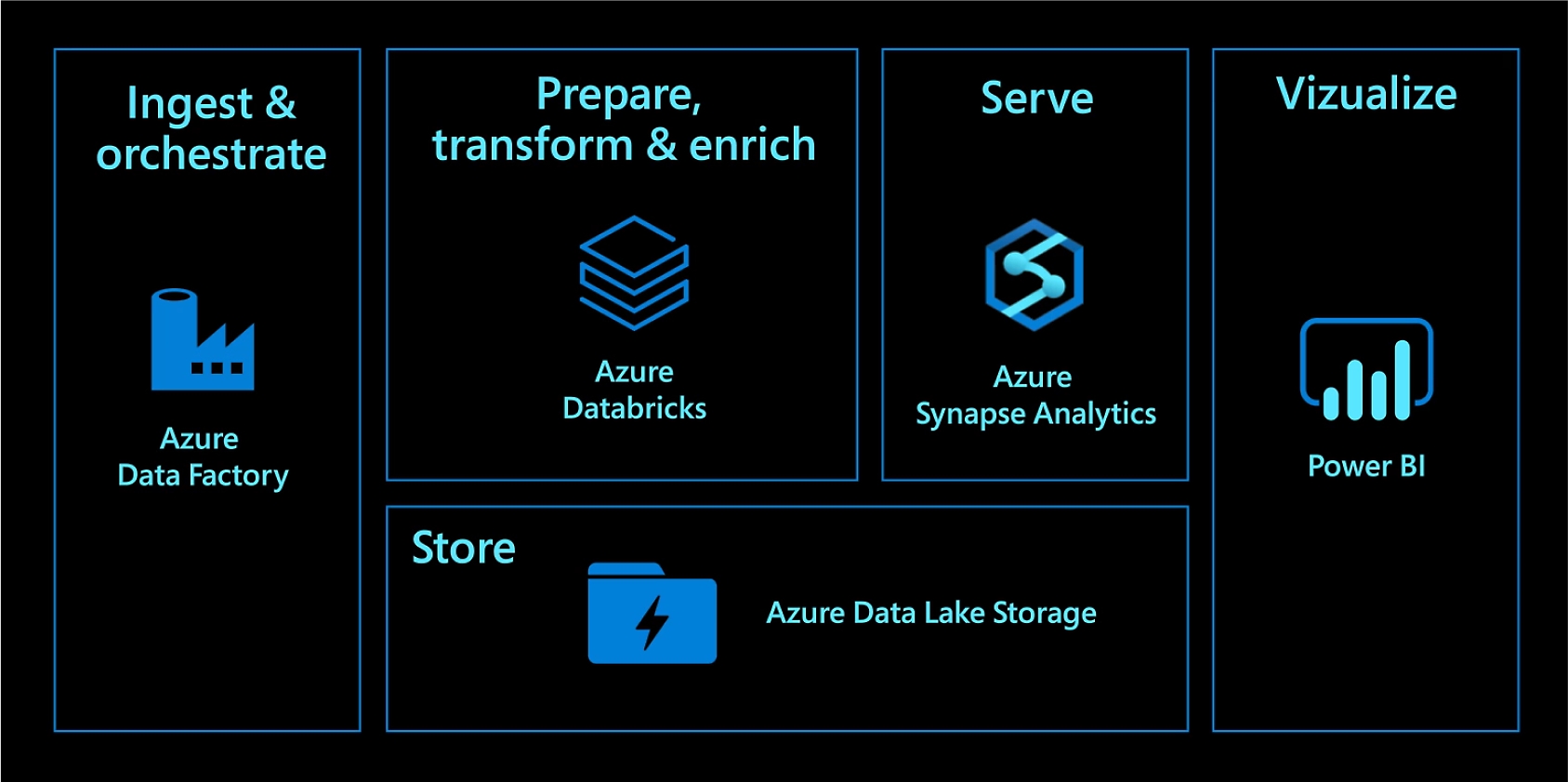
获得高性能的现代数据仓库
通过分析仪表板和操作报表,合并任意规模的数据并获取见解。使用 Azure 数据工厂自动执行数据移动,然后将数据加载到 Azure Data Lake Storage,使用 Azure Databricks 转换和清理数据,并使用 Azure Synapse Analytics 对数据进行分析。在云中实现数据仓库的现代化,实现无与伦比的性能和可扩展性。
主要服务功能
-
优化的 Spark 引擎
在自动缩放基础结构上进行简单的数据处理,该基础结构由高度优化的 Apache Spark™ 支持,性能提升高达 50 倍。
-
机器学习运行时
单击一下即可访问预配置的机器学习环境,以使用最先进和最热门的框架(如 PyTorch、TensorFlow 和 scikit-learn)进行增强机器学习。


-
MLflow
跟踪和共享试验、重现运行,并从中央存储库协作管理模型。
-
语言选项
无论使用无服务器计算资源还是预配的计算资源,都可使用你偏好的语言,包括 Python、Scala、R、Spark SQL 和 .Net。


-
协作式笔记本
快速访问和浏览数据、查找并共享新见解,并使用所选的语言和工具协同构建模型。
-
Delta Lake
使用专为完整数据生命周期设计的开源事务存储层,将数据可靠性和可伸缩性引入现有的数据湖。


-
与 Azure 服务的本机集成
利用与 Azure 服务(如 Azure 数据工厂、Azure Data Lake Storage、Azure 机器学习和 Power BI)的深度集成,完成端到端分析和机器学习解决方案。
-
交互式工作区
支持数据科学家、数据工程师和商业分析师之间的无缝协作。


-
企业级安全性
毫不费力的原生安全性可以在数据驻留位置保护数据,并跨数千个用户和数据集创建合规、专用且隔离的分析工作区。
-
生产就绪
使用用于 CI/CD 和监视的生态系统集成,在受信任的数据平台上自信地运行和缩放任务关键型数据工作负载。


通过解决方案体系结构示例了解详细信息

Azure Databricks 的数据科学和机器学习
轻松从实时流数据中获取见解。持续从所有 IoT 设备或网站点击流日志捕获数据,并准实时地处理数据。

使用 Azure Databricks 的新式分析体系结构
使用领先机器学习工具将数据转化为可行见解。通过这种架构,可将任何规模的数据进行组合,且可大规模构建和部署自定义机器学习模型。

引入、ETL 和流处理管道与 Azure Databricks
利用 Azure Databricks、MLflow 和 Azure 机器学习加速和管理端到端机器学习生命周期,以生成、共享、部署和管理机器学习应用程序。
内置的全面安全性和合规性
-
Microsoft 每年在网络安全研发方面的投资超过 USD10 亿。


-
我们雇佣了 3,500 多名安全专家,专门负责数据安全和隐私方面的工作。

-
Azure 拥有比任何其他云提供商都多的认证。查看完整列表。
详细了解 Azure Databricks 产品和服务

Azure 数据工厂
可大规模简化 ETL 的混合数据集成服务。

Azure Data Lake Storage Gen 2
基于 Azure Blob 存储构建的高度可缩放的安全 Data Lake 功能。

Azure 机器学习
企业级机器学习服务,可用于更快地构建和部署模型。

Power BI
向应用程序添加分析和交互式报表。

开始使用 Azure 免费帐户

2

用完额度后,请改为即付即用定价以继续使用相同的免费服务构建自己的内容。只需为超出每月免费使用量以外的部分付费。
3

社区和 Azure 支持
在 MSDN 论坛和 Stack Overflow 上向 Microsoft 工程师和 Azure 社区专家提问并获取支持,或者与 Azure 支持联系。
热门的实验室和模板
发现由 Microsoft 和社区提供的 自定进度实验室 和热门的 常用配置快速入门模板 。
浏览 Azure Databricks 资源
有关 Azure Databricks 的常见问题解答
-
Azure Databricks SLA 保证 99.95% 的可用性。
-
Databricks 单位(或 DBU)是每小时处理能力的单位,按每秒使用量计费。
-
数据工程工作负载是指在其运行的群集上自动启动和终止群集的作业。例如,Azure Databricks 作业计划程序可能会触发工作负载,该计划程序仅为该作业启动新的 Apache Spark 群集,并在作业完成后自动终止群集。
数据分析工作负载不会自动执行。例如,Azure Databricks 笔记本中的命令在 Apache Spark 群集上运行,直到手动将其终止。多个用户可以共享一个群集以协作进行分析。