
This blog was written in collaboration with the DeepSpeed team, the Azure ML team, and the Azure HPC team at Microsoft.
Large-scale transformer-based deep learning models trained on large amounts of data have shown great results in recent years in several cognitive tasks and are behind new products and features that augment human capabilities. These models have grown several orders of magnitude in size during the last five years. Starting from a few million parameters of the original transformer model all the way to the latest 530 billion-parameter Megatron-Turing (MT-NLG 530B) model as shown in Figure 1. There is a growing need for customers to train and fine-tune large models at an unprecedented scale.

Figure 1: Landscape of large models and hardware capabilities.
Azure Machine Learning (AzureML) brings large fleets of the latest NVIDIA GPUs powered by NVIDIA Quantum InfiniBand interconnects to tackle large-scale AI training. We already train some of the largest models including Megatron/Turing and GPT-3 on Azure. Previously, to train these models, users needed to set up and maintain a complex distributed training infrastructure that usually required several manual and error-prone steps. This led to a subpar experience both in terms of usability and performance.
Today, we are proud to announce a breakthrough in our software stack, using DeepSpeed and 1024 NVIDIA A100s to scale the training of a 2T parameter model with a streamlined user experience at 1K+ GPU scale. We are bringing these software innovations to you through AzureML (including a fully optimized PyTorch environment) that offers great performance and an easy-to-use interface for large-scale training.
Customers can now use DeepSpeed on Azure with simple-to-use training pipelines that utilize either the recommended AzureML recipes or via bash scripts for VMSS-based environments. As shown in Figure 2, Microsoft is taking a full stack optimization approach where all the necessary pieces including the hardware, the OS, the VM image, the Docker image (containing optimized PyTorch, DeepSpeed, ONNX Runtime, and other Python packages), and the user-facing Azure ML APIs have been optimized, integrated, and well-tested for excellent performance and scalability without unnecessary complexity.

Figure 2: Microsoft full-stack optimizations for scalable distributed training on Azure.
This optimized stack enabled us to efficiently scale training of large models using DeepSpeed on Azure. We are happy to share our performance results supporting 2x larger model sizes (2 trillion vs. 1 trillion parameters), scaling to 2x more GPUs (1024 vs. 512), and up to 1.8x higher compute throughput/GPU (150 TFLOPs vs. 81 TFLOPs) compared to those published on other cloud providers.
We offer near-linear scalability both in terms of an increase in model size as well as increase in number of GPUs. As shown in Figure 3a, together with the DeepSpeed ZeRO-3, its novel CPU offloading capabilities, and a high-performance Azure stack powered by InfiniBand Quantum interconnects and NVIDIA A100 GPUs, we were able to maintain an efficient throughput/GPU (>157 TFLOPs) in a near-linear fashion as the model size increased from 175 billion parameters to 2 trillion parameters. On the other hand, for a given model size, for example, 175B, we achieve near-linear scaling as we increase the number of GPUs from 128 all the way to 1024 as shown in Figure 3b. The key takeaway from the results presented in this blog is that Azure and DeepSpeed together are breaking the GPU memory wall and enabling our customers to easily and efficiently train trillion-parameter models at scale.
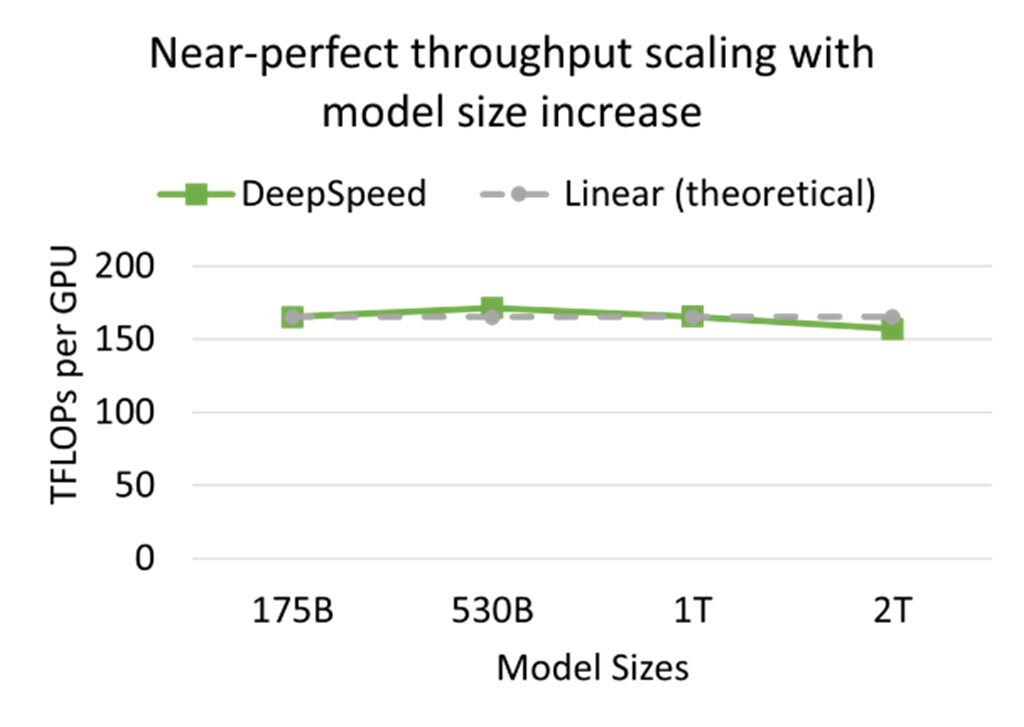
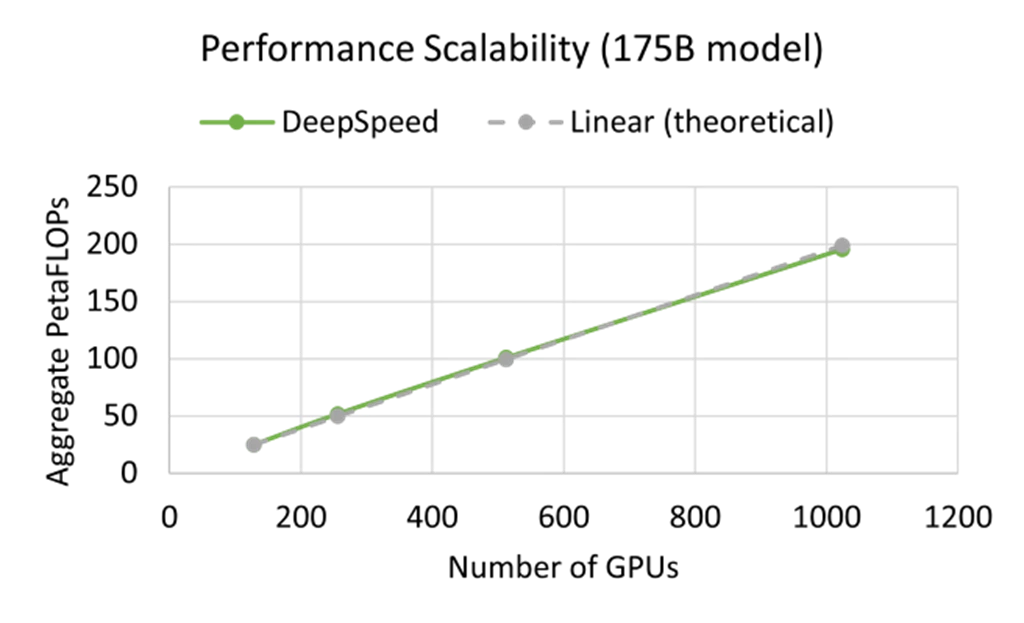
(a) (b)
Figure 3: (a) Near-perfect throughput/GPU as we increase the model size from 175 billion to 2 trillion parameters (BS/GPU=8), (b) Near-perfect performance scaling with the increase in number of GPU devices for the 175B model (BS/GPU=16). The sequence length is 1024 for both cases.
Learn more
To learn more about the optimizations, technologies, and detailed performance trends presented above, please refer to our extended technical blog.
- Learn more about DeepSpeed, which is part of Microsoft’s AI at Scale initiative.
- Learn more about Azure HPC + AI.
- To get started with DeepSpeed on Azure, please follow our getting started tutorial.
- The results presented in this blog were produced on Azure by following the recipes and scripts published as part of the Megatron-DeepSpeed repository. The recommended and most easy-to-use method to run the training experiments is to utilize the AzureML recipe.
- If you are running experiments on a custom environment built using Azure VMs or VMSS, please refer to the bash scripts we provide in Megatron-DeepSpeed.





