

Azure empowers intelligent services like Microsoft Copilot, Bing, and Azure OpenAI Service that have captured our imagination in recent days. These services, facilitating various applications like Microsoft Office 365, chatbots, and search engines with generative AI, owe their magic to large language models (LLMs). While the latest LLMs are transcendental, bringing a generational change in how we apply artificial intelligence in our daily lives and reason about its evolution, we have merely scratched the surface. Creating more capable, fair, foundational LLMs that consume and present information more accurately is necessary.
How Microsoft maximizes the power of LLMs
However, creating new LLMs or improving the accuracy of existing ones is no easy feat. To create and train improved versions of LLMs, supercomputers with massive computational capabilities are required. It is paramount that both the hardware and software in these supercomputers are utilized efficiently at scale, not leaving performance on the table. This is where the sheer scale of the supercomputing infrastructure in Azure cloud shines and setting a new scale record in LLM training matters.
Customers need reliable and performant infrastructure to bring the most sophisticated AI use cases to market in record time. Our objective is to build state-of-the-art infrastructure and meet these demands. The latest MLPerf™ 3.1 Training results1 are a testament to our unwavering commitment to building high-quality and high-performance systems in the cloud to achieve unparalleled efficiency in training LLMs at scale. The idea here is to use massive workloads to stress every component of the system and accelerate our build process to achieve high quality.
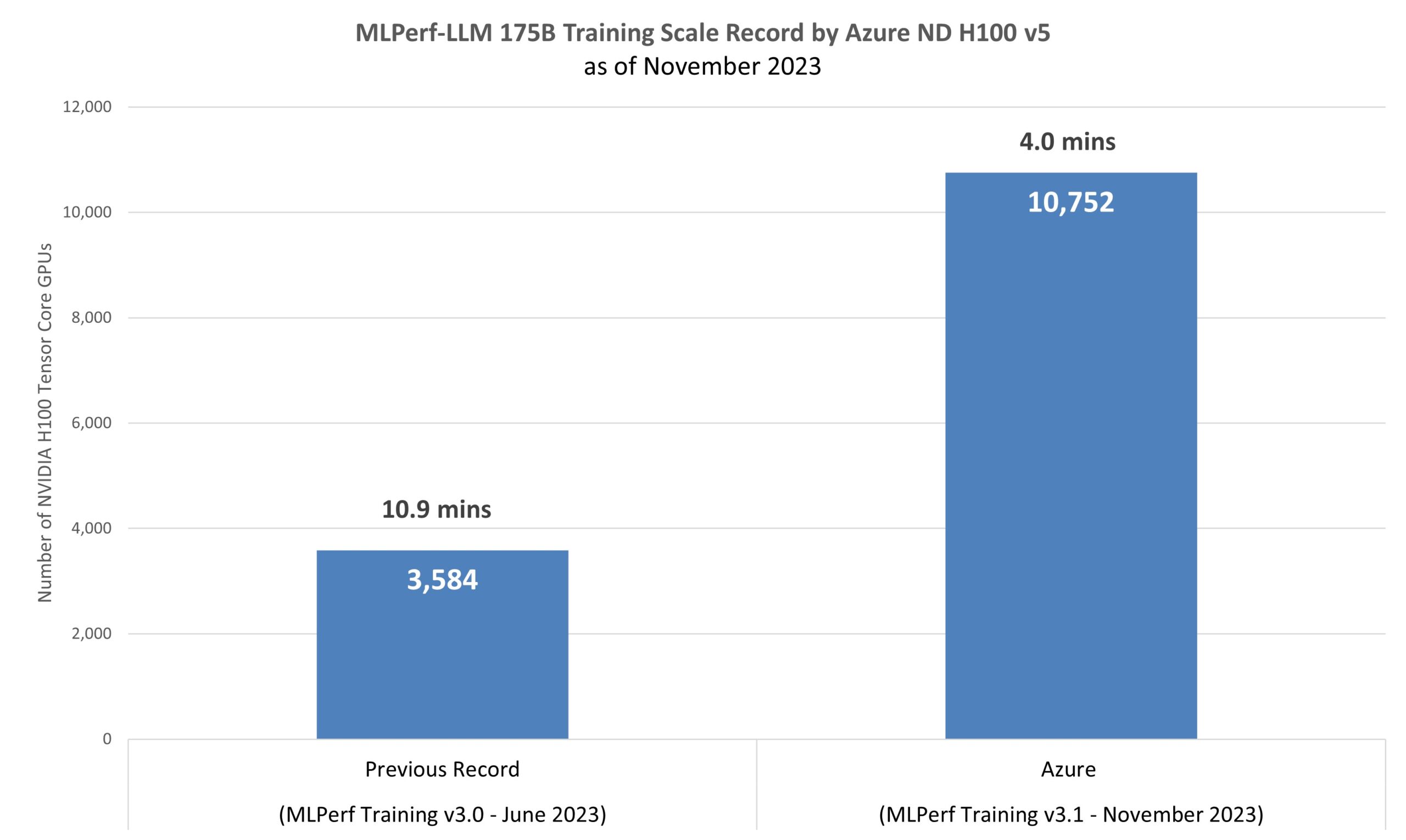
The GPT-3 LLM model and its 175 billion parameters were trained to completion in four minutes on 1,344 ND H100 v5 virtual machines (VMs), which represent 10,752 NVIDIA H100 Tensor Core GPUs, connected by the NVIDIA Quantum-2 InfiniBand networking platform (as shown in Figure 1). This training workload uses close to real-world datasets and restarts from 2.4 terabytes of checkpoints acting closely a production LLM training scenario. The workload stresses the H100 GPUs Tensor Cores, direct-attached Non-Volatile Memory Express disks, and the NVLink interconnect that provides fast communication to the high-bandwidth memory in the GPUs and cross-node 400Gb/s InfiniBand fabric.
Azure’s submission, the largest in the history of MLPerf Training, demonstrates the extraordinary progress we have made in optimizing the scale of training. MLCommons’ benchmarks showcase the prowess of modern AI infrastructure and software, underlining the continuous advancements that have been achieved, ultimately propelling us toward even more powerful and efficient AI systems
David Kanter, Executive Director of MLCommons
Microsoft’s commitment to performance
In March 2023, Microsoft introduced the ND H100 v5-series which completed training a 350 million parameter Bidirectional Encoder Representations from Transformers (BERT) language model in 5.4 minutes, beating our existing record. This resulted in a four times improvement in time to train BERT within just 18 months, highlighting our continuous endeavor to bring the best performance to our users.
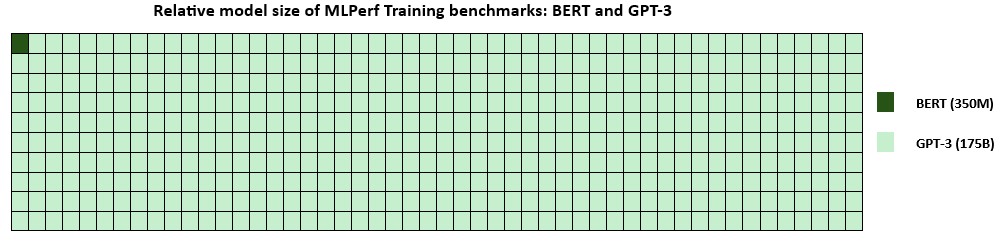
Today’s results are with GPT-3, a large language model in the MLPerf Training benchmarking suite, featuring 175 billion parameters, a remarkable 500 times larger than the previously benchmarked BERT model (figure 2). The latest training time from Azure reached a 2.7x improvement compared to the previous record from MLPerf Training v3.0. The v3.1 submission underscores the ability to decrease training time and cost by optimizing a model that accurately represents current AI workloads.
The power of virtualization
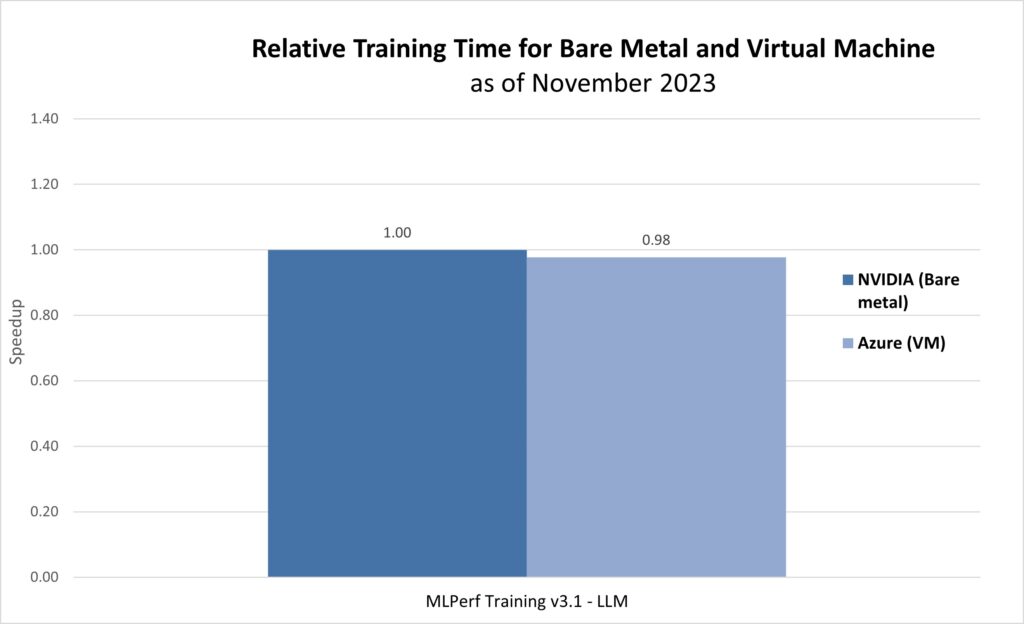
NVIDIA’s submission to the MLPerf Training v3.1 LLM benchmark on 10,752 NVIDIA H100 Tensor Core GPUs achieved a training time of 3.92 minutes. This amounts to just a 2 percent increase in the training time in Azure VMs compared to the NVIDIA bare-metal submission, which has the best-in-class performance of virtual machines across all offerings of HPC instances in the cloud (figure 3).
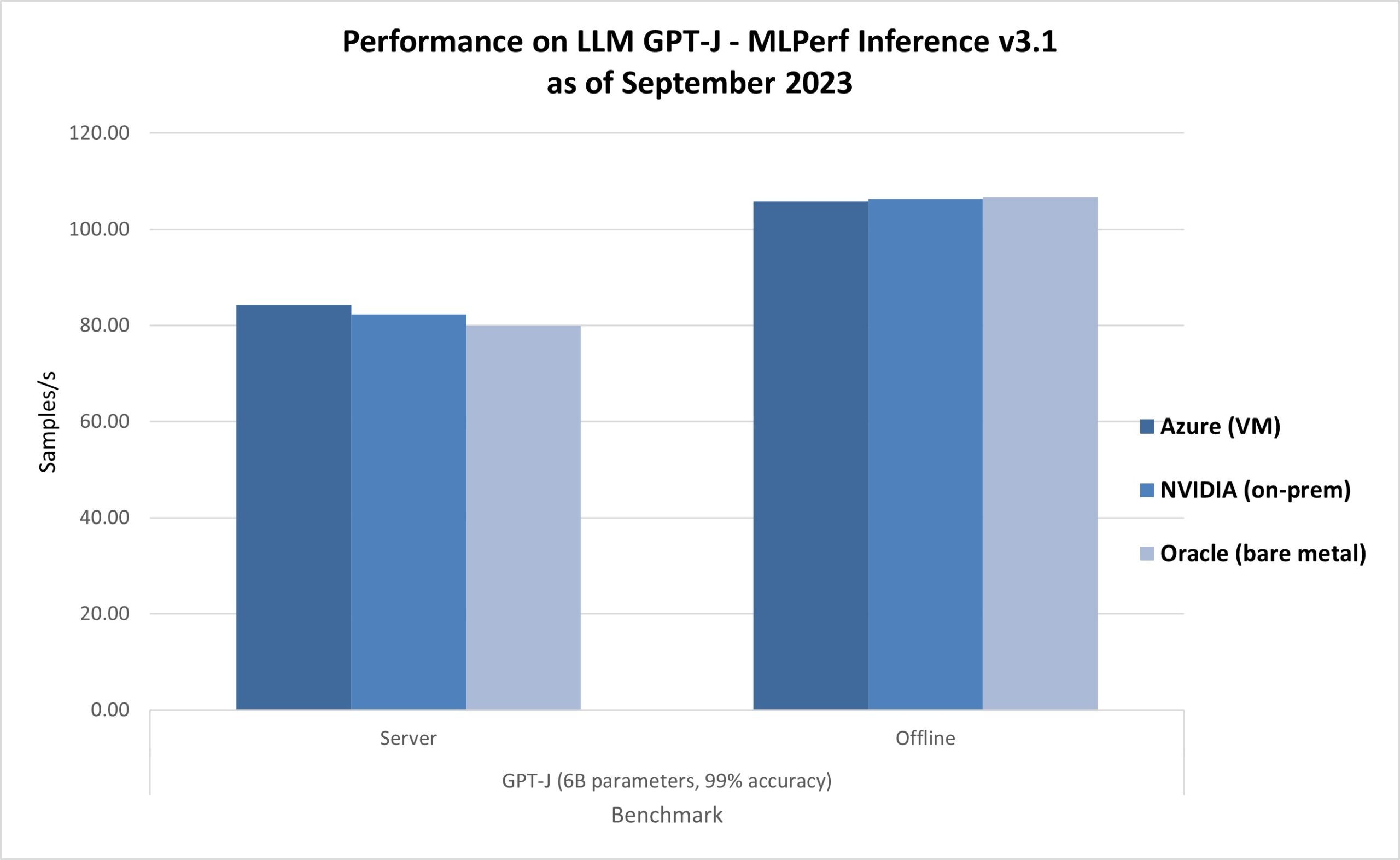
The latest results in AI Inferencing on Azure ND H100 v5 VMs show leadership results as well, as shown in MLPerf Inference v3.1. The ND H100 v5-series delivered 0.99x-1.05x relative performance compared to the bare-metal submissions on the same NVIDIA H100 Tensor Core GPUs (figure 4), echoing the efficiency of virtual machines.
In conclusion, created for performance, scalability, and adaptability, the Azure ND H100 v5-series offers exceptional throughput and minimal latency for both training and inferencing tasks in the cloud and offers the highest quality infrastructure for AI.
Learn more about Azure AI Infrastructure
References
- MLCommons® is an open engineering consortium of AI leaders from academia, research labs, and industry. They build fair and useful benchmarks that provide unbiased evaluations of training and inference performance for hardware, software, and services—all conducted under prescribed conditions. MLPerf™ Training benchmarks consist of real-world compute-intensive AI workloads to best simulate customer’s needs. Tests are transparent and objective, so technology decision-makers can rely on the results to make informed buying decisions.





