
This blog post is co-authored by David Stein, Senior Staff Software Engineer, Jinghui Mo, Staff Software Engineer, and Hangfei Lin, Staff Software Engineer, all from Feathr team.
Feature store motivation
With the advance of AI and machine learning, companies start to use complex machine learning pipelines in various applications, such as recommendation systems, fraud detection, and more. These complex systems usually require hundreds to thousands of features to support time-sensitive business applications, and the feature pipelines are maintained by different team members across various business groups.
In these machine learning systems, we see many problems that consume lots of energy of machine learning engineers and data scientists, in particular duplicated feature engineering, online-offline skew, and feature serving with low latency.
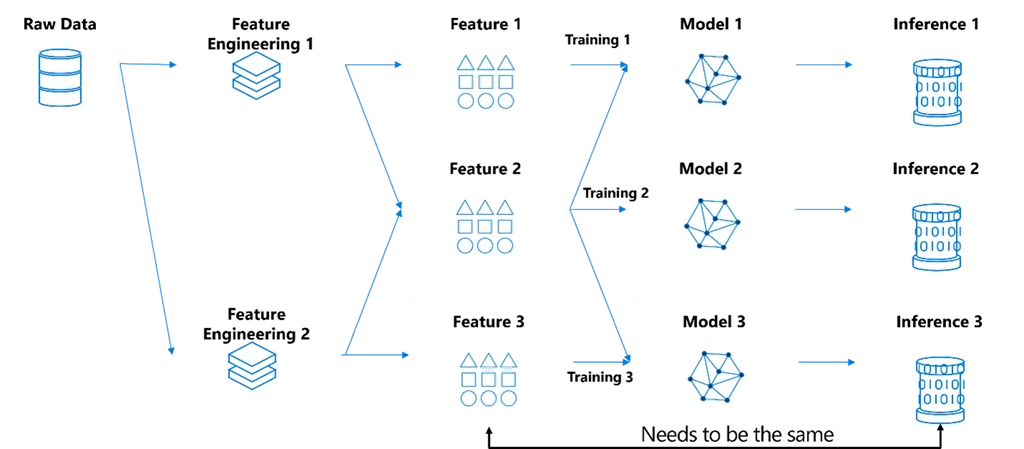
Figure 1: Illustration on problems that feature store solves.
Duplicated feature engineering
- In an organization, thousands of features are buried in different scripts and in different formats; they are not captured, organized, or preserved, and thus cannot be reused and leveraged by teams other than those who generated them.
- Because feature engineering is so important for machine learning models and features cannot be shared, data scientists must duplicate their feature engineering efforts across teams.
Online-offline skew
- For features, offline training and online inference usually require different data serving pipelines—ensuring consistent features across different environments is expensive.
- Teams are deterred from using real-time data for inference due to the difficulty of serving the right data.
- Providing a convenient way to ensure data point-in-time correctness is key to avoid label leakage.
Serving features with low latency
- For real-time applications, getting feature lookups from database for real-time inference without compromising response latency and with high throughput can be challenging.
- Easily accessing features with very low latency is key in many machine learning scenarios, and optimizations needs to be done to combine different REST API calls to features.
To solve those problems, a concept called feature store was developed, so that:
- Features are centralized in an organization and can be reused
- Features can be served in a synchronous way between offline and online environment
- Features can be served in real-time with low latency
Introducing Feathr, a battle-tested feature store
Developing a feature store from scratch takes time, and it takes much more time to make it stable, scalable, and user-friendly. Feathr is the feature store that has been used in production and battle-tested in LinkedIn for over 6 years, serving all the LinkedIn machine learning feature platform with thousands of features in production.
At Microsoft, the LinkedIn team and the Azure team have worked very closely to open source Feathr, make it extensible, and build native integration with Azure. It’s available in this GitHub repository and you can read more about Feathr on the LinkedIn Engineering Blog.
Some of the highlights for Feathr include:
- Scalable with built-in optimizations. For example, based on some internal use case, Feathr can process billions of rows and PB scale data with built-in optimizations such as bloom filters and salted joins.
- Rich support for point-in-time joins and aggregations: Feathr has high performant built-in operators designed for Feature Store, including time-based aggregation, sliding window joins, look-up features, all with point-in-time correctness.
- Highly customizable user-defined functions (UDFs) with native PySpark and Spark SQL support to lower the learning curve for data scientists.
- Pythonic APIs to access everything with low learning curve; Integrated with model building so data scientists can be productive from day one.
- Rich type system including support for embeddings for advanced machine learning/deep learning scenarios. One of the common use cases is to build embeddings for customer profiles, and those embeddings can be reused across an organization in all the machine learning applications.
- Native cloud integration with simplified and scalable architecture, which is illustrated in the next section.
- Feature sharing and reuse made easy: Feathr has built-in feature registry so that features can be easily shared across different teams and boost team productivity.
Feathr on Azure architecture
The high-level architecture diagram below articulates how would a user interacts with Feathr on Azure:
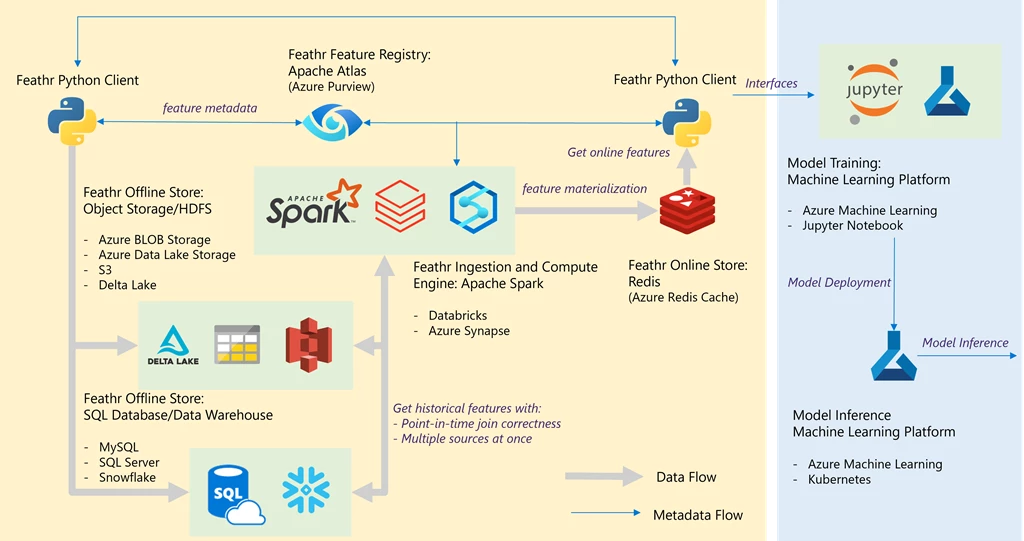
Figure 2: Feathr on Azure architecture.
- A data or machine learning engineer creates features using their preferred tools (like pandas, Azure Machine Learning, Azure Databricks, and more). These features are ingested into offline stores, which can be either:
- Azure SQL Database (including serverless), Azure Synapse Dedicated SQL Pool (formerly SQL DW).
- Object storage, such as Azure BLOB storage, Azure Data Lake Store, and more. The format can be Parquet, Avro, or Delta Lake.
- The data or machine learning engineer can persist the feature definitions into a central registry, which is built with Azure Purview.
- The data or machine learning engineer can join on all the feature dataset in a point-in-time correct way, with Feathr Python SDK and with Spark engines such as Azure Synapse or Databricks.
- The data or machine learning engineer can materialize features into an online store such as Azure Cache for Redis with Active-Active, enabling multi-primary, multi-write architecture that ensures eventual consistency between clusters.
- Data scientists or machine learning engineers consume offline features with their favorite machine learning libraries, for example scikit-learn, PyTorch, or TensorFlow to train a model in their favorite machine learning platform such as Azure Machine Learning, then deploy the models in their favorite environment with services such as Azure Machine Learning endpoint.
- The backend system makes a request to the deployed model, which makes a request to the Azure Cache for Redis to get the online features with Feathr Python SDK.
A sample notebook containing all the above flow is located in the Feathr repository for more reference.
Feathr has native integration with Azure and other cloud services. The table below shows these integrations:
|
Feathr component |
Cloud Integrations |
|
Offline store – Object Store |
Azure Blob Storage
|
|
Offline store – SQL |
Azure SQL DB |
|
Online store |
Azure Cache for Redis |
|
Feature Registry |
Azure Purview |
|
Compute Engine |
Azure Synapse Spark Pools |
|
Machine Learning Platform |
Azure Machine Learning |
|
File Format |
Parquet |
Table 1: Feathr on Azure Integration with Azure Services.
Installation and getting started
Feathr has a pythonic interface to access all Feathr components, including feature definition and cloud interactions, and is open sourced here. The Feathr python client can be easily installed with pip:
pip install -U feathr
For more details on getting started, please refer to the Feathr Quickstart Guide. The Feathr team can also be reached in the Feathr community.
Going forward
In this blog, we’ve introduced a battle-tested feature store, called Feathr, which is scalable and enterprise ready, with native Azure integrations. We are dedicated to bringing more functionalities into Feathr and Feathr on Azure integrations, and feel free to give any feedback by raising issues in Feathr GitHub repository.
- Checkout the GitHub repository for Feathr.
- Reach out to Feathr community.
- Read Feathr open-source blog post from our LinkedIn colleagues.