
HPC-optimized virtual machines now available
Azure HBv2-series Virtual Machines (VMs) are now generally available in the South Central US region. HBv2 VMs will also be available in West Europe, East US, West US 2, North Central US, Japan East soon.
HBv2 VMs deliver supercomputer-class performance, message passing interface (MPI) scalability, and cost efficiency for a variety of real-world high performance computing (HPC) workloads, such as CFD, explicit finite element analysis, seismic processing, reservoir modeling, rendering, and weather simulation.
Azure HBv2 VMs are the first in the public cloud to feature 200 gigabit per second HDR InfiniBand from Mellanox. HDR InfiniBand on Azure delivers latencies as low as 1.5 microseconds, more than 200 million messages per second per VM, and advanced in-network computing engines like hardware offload of MPI collectives and adaptive routing for higher performance on the largest scaling HPC workloads. HBv2 VMs use standard Mellanox OFED drivers that support all RDMA verbs and MPI variants.
Each HBv2 VM features 120 AMD EPYC™ 7002-series CPU cores with clock frequencies up to 3.3 GHz, 480 GB of RAM, 480 MB of L3 cache, and no simultaneous multithreading (SMT). HBv2 VMs provide up to 340 GB/sec of memory bandwidth, which is 45-50 percent more than comparable x86 alternatives and three times faster than what most HPC customers have in their datacenters today. A HBv2 virtual machine is capable of up to 4 double-precision teraFLOPS, and up to 8 single-precision teraFLOPS.
One and three year Reserved Instance, Pay-As-You-Go, and Spot Pricing for HBv2 VMs is available now for both Linux and Windows deployments. For information about five-year Reserved Instances, contact your Azure representative.
Disruptive speed for critical weather forecasting
Numerical Weather Prediction (NWP) and simulation has long been one of the most beneficial use cases for HPC. Using NWP techniques, scientists can better understand and predict the behavior of our atmosphere, which in turn drives advances in everything from coordinating airline traffic, shipping of goods around the globe, ensuring business continuity, and critical disaster preparedness from the most adverse weather. Microsoft recognizes the criticality of this field is to science and society, which is why Azure shares US hourly weather forecast data produced by the Global Forecast System (GFS) from the National Oceanic and Atmospheric Administration (NOAA) as part of the Azure Open Datasets initiative.
Cormac Garvey, a member of the HPC Azure Global team, has extensive experience supporting weather simulation teams on the world’s most powerful supercomputers. Today, he’s published a guide to running the widely-used Weather Research and Forecasting (WRF) Version 4 simulation suite on HBv2 VMs.
Cormac used a 371M grid point simulation of Hurricane Maria, a Category 5 storm that struck the Caribbean in 2017, with a resolution of 1 kilometer. This model was chosen not only as a rigorous benchmark of HBv2 VMs but also because the fast and accurate simulation of dangerous storms is one of the most vital functions of the meteorology community.
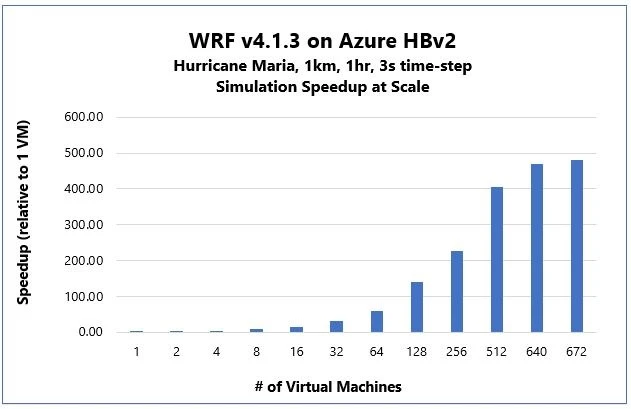
Figure 1: WRF Speedup from 1 to 672 Azure HBv2 VMs.
|
Nodes (VMs) |
Parallel Processes |
Average Time(s) per Time Step |
Scaling Efficiency |
Speedup (VM-based) |
|
1 |
120 |
18.51 |
100 percent |
1.00 |
|
2 |
240 |
8.9 |
104 percent |
2.08 |
|
4 |
480 |
4.37 |
106 percent |
4.24 |
|
8 |
960 |
2.21 |
105 percent |
8.38 |
|
16 |
1,920 |
1.16 |
100 percent |
15.96 |
|
32 |
3,840 |
0.58 |
100 percent |
31.91 |
|
64 |
7,680 |
0.31 |
93 percent |
59.71 |
|
128 |
15,360 |
0.131 |
110 percent |
141.30 |
|
256 |
23,040 |
0.082 |
88 percent |
225.73 |
|
512 |
46,080 |
0.0456 |
79 percent |
405.92 |
|
640 |
57,600 |
0.0393 |
74 percent |
470.99 |
|
672 |
80,640 |
0.0384 |
72 percent |
482.03 |
Figure 2: Scaling and configuration data for WRF on Azure HBv2 VMs.
Note: for some scaling points, optimal performance is achieved with 30 MPI ranks and 4 threads per rank, while in others 90 MPI ranks was optimal. All tests were run with OpenMPI 4.0.2.
Azure HBv2 VMs executed the “Maria” simulation with mostly super-linear scalability up to 128 VMs (15,360 parallel processes). Improvements from scaling continue up to the largest scale of 672 VMs (80,640 parallel processes) tested in this exercise, where a 482x speedup over a single VM. At 512 nodes (VMs) we observe a ~2.2x performance increase as compared to a leading supercomputer that debuted among the top 20 fastest machines in 2016.
The gating factor to higher levels of scaling efficiency? The 371M grid point model, even as one of the largest known WRF models, is too small at such extreme levels of parallel processing. This opens the door for leading weather forecasting organizations to leverage Azure to build and operationalize even higher resolution models that higher numerical accuracy and a more realistic understanding of these complex weather phenomena.
Visit Cormac’s blog post on the Azure Tech Community to learn how to run WRF on our family of H-series Virtual Machines, including HBv2.
Better, safer product design from hyper-realistic CFD
Computational fluid dynamics (CFD) is core to the simulation-driven businesses of many Azure customers. A common request from customers is to “10x” their capabilities while keeping costs as close to constant as possible. Specifically, customers often seek ways to significantly increase the accuracy of their models by simulating it in higher resolution. Given that many customers already solve CFD problems with ~500-1000 parallel processes per job, this is a tall task that implies linear scaling to at least 5,000-10,000 parallel processes. Last year, Azure accomplished one of these objectives when it became the first public cloud to scale a CFD application to more than 10,000 parallel processes. With the launch of HBv2 VMs, Azure’s CFD capabilities are increasing again.
Jon Shelley, also a member of the Azure Global HPC team, worked with Siemens to validate one its largest CFD simulations ever, a 1 billion cell model of a sports car named after the famed 24 Hours of Le Mans race with a 10x higher-resolution mesh than what Azure tested just last year. Jon has published a guide to running Simcenter STAR-CCM+ at large scale on HBv2 VMs.
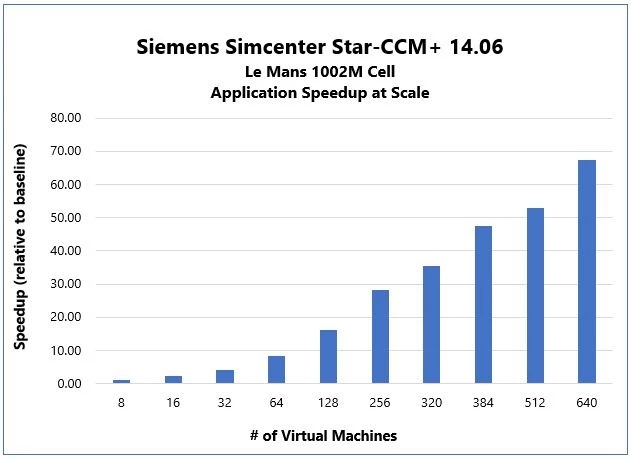
Figure 3: Simcenter STAR-CCM+ Scaling Efficiency from 1 to 640 Azure HBv2 VMs
|
Nodes (VMs) |
Parallel Processes |
Solver Elapsed Time |
Scaling Efficiency |
Speedup (VM-based) |
|
8 |
928 |
337.71 |
100 percent |
1.00 |
|
16 |
1,856 |
164.79 |
102.5 percent |
2.05 |
|
32 |
3,712 |
82.07 |
102.9 percent |
4.11 |
|
64 |
7,424 |
41.02 |
102.9 percent |
8.23 |
|
128 |
14,848 |
20.94 |
100.8 percent |
16.13 |
|
256 |
29,696 |
12.02 |
87.8 percent |
28.10 |
|
320 |
37,120 |
9.57 |
88.2 percent |
35.29 |
|
384 |
44,544 |
7.117 |
98.9 percent |
47.45 |
|
512 |
59,392 |
6.417 |
82.2 percent |
52.63 |
|
640 |
57,600 |
5.03 |
83.9 percent |
67.14 |
Figure 4: Scaling and configuration data for STAR-CCM+ on Azure HBv2 VMs
Note: A given scaling point may achieve optimal performance with 90, 112, 116, or 120 parallel processes per VM. Plotted data below shows optimal performance figures. All tests were run with HPC-X MPI ver. 2.50.
Once again, Azure HBv2 executed the challenging problem with linear efficiency to more than 15,000 parallel processes across 128 VMs. From there, high scaling efficiency continued, peaking at nearly 99 percent at more than 44,000 parallel processes. At the largest scale of 640 VMs and 57,600 parallel processes, HBv2 delivered 84 percent scaling efficiency. This is among the largest scaling CFD simulations with Simcenter STAR-CCM+ ever performed, and now can be replicated by Azure customers.
Extreme HPC I/O meets cost-efficiency
An increasing scenario on the cloud is on-demand HPC-grade parallel filesystems. The rationale is straight forward; if a customer needs to perform a large quantity of compute, that customer often needs to also move a lot of data into and out of those compute resources. The catch? Simple cost comparisons against traditional on-premises HPC filesystem appliances can be unfavorable, depending on circumstances. With Azure HBv2 VMs, however, NVMeDirect technology can be combined with ultra low-latency RDMA capabilities to deliver on-demand “burst buffer” parallel filesystems at no additional cost beyond the HBv2 VMs already provisioned for compute purposes.
BeeGFS is one such filesystem and has a rapidly growing user base among both entry-level and extreme-scale users. The BeeOND filesystem is even used in production on the novel HPC + AI hybrid supercomputer “Tsubame 3.0.”
Here is a high-level summary of how a sample BeeOND filesystem looks when created across 352 HBv2 VMs, providing 308 terabytes of usable, high-performance namespace.
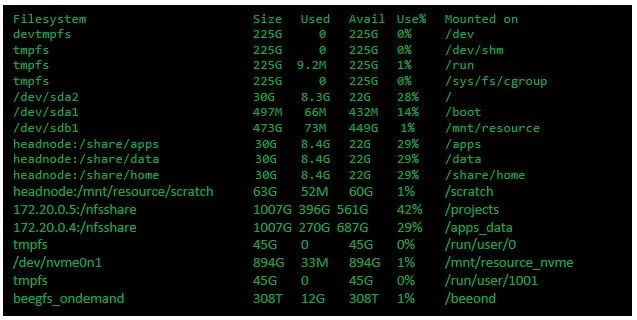
Figure 5: Overview of example BeeOND filesystem on HBv2 VMs.
Running the widely-used IOR test of parallel filesystems across 352 HBv2 VMs, BeeOND achieved peak read performance of 763 gigabytes per second, and peak write performance of 352 gigabytes per second.
10x-ing the cloud HPC experience
Microsoft Azure is committed to delivering to our customers a world-class HPC experience, and maximum levels of performance, price/performance, and scalability.
“The 2nd Gen AMD EPYC processors provide fantastic core scaling, access to massive memory bandwidth and are the first x86 server processors that support PCIe 4.0; all of these features enable some of the best high-performance computing experiences for the industry,” said Ram Peddibhotla, corporate vice president, Data Center Product Management, AMD. “What Azure has done for HPC in the cloud is amazing; demonstrating that HBv2 VMs and 2nd Gen EPYC processors can deliver supercomputer-class performance, MPI scalability, and cost efficiency for a variety of real-world HPC workloads, while democratizing access to HPC that will help drive the advancement of science and research.”
“200 gigabit HDR InfiniBand delivers high data throughout, extremely low latency, and smart In-Network Computing engines, enabling high performance and scalability for compute and data applications. We are excited to collaborate with Microsoft to bring the InfiniBand advantages into Azure, providing users with leading HPC cloud services” said Gilad Shainer, Senior Vice President of Marketing at Mellanox Technologies. “By taking advantage of InfiniBand RDMA and its MPI acceleration engines, Azure delivers higher performance compared to other cloud options based on Ethernet. We look forward to continuing to work with Microsoft to introduce future generations and capabilities.”
- Find out more about High Performance Computing in Azure.
- Running WRF v4 on Azure.
- Tuning BeeGFS and BeeOND on Azure for Specific I/O Patterns.
- Azure HPC on Github.
- Azure HPC CentOS 7.6 and 7.7 images.
- Learn about Azure Virtual Machines.