

In the early days of the AI shift, AI applications were largely built as thin layers on top of off-the-shelf foundation models. But as developers began tackling more complex use cases, they quickly encountered the limitations of simply using RAG on top of off-the-shelf models. While this approach offered a fast path to production, it often fell short in delivering the accuracy, reliability, efficiency, and engagement needed for more sophisticated use cases.
However, this dynamic is shifting. As AI shifts from assistive copilots to autonomous co-workers, the architecture behind these systems must evolve. Autonomous workflows, powered by real-time feedback and continuous learning, are becoming essential for productivity and decision-making. AI applications that incorporate continuous learning through real-time feedback loops—what we refer to as the ‘signals loop’—are emerging as the key to building more adaptive and resilient differentiation over time.
Building truly effective AI apps and agents requires more than just access to powerful LLMs. It demands a rethinking of AI architecture—one that places continuous learning and adaptation at its core. The ‘signals loop’ centers on capturing user interactions and product usage data in real time, then systematically integrating this feedback to refine model behavior and evolve product features, creating applications that get better over time.
As the rise of open-source frontier models democratizes access to model weights, fine-tuning (including reinforcement learning) is becoming more accessible and building these loops becomes more feasible. Capabilities like memory are also increasing the value of signals loops. These technologies enable AI systems to retain context and learn from user feedback—driving greater personalization and improving customer retention. And as the use of agents continues to grow, ensuring accuracy becomes even more critical, underscoring the growing importance of fine-tuning and implementing a robust signals loop.
At Microsoft, we’ve seen the power of the signals loop approach firsthand. First-party products like Dragon Copilot and GitHub Copilot exemplify how signals loops can drive rapid product improvement, increased relevance, and long-term user engagement.
Implementing signals loop for continuous AI improvement: Insights from Dragon Copilot and GitHub Copilot
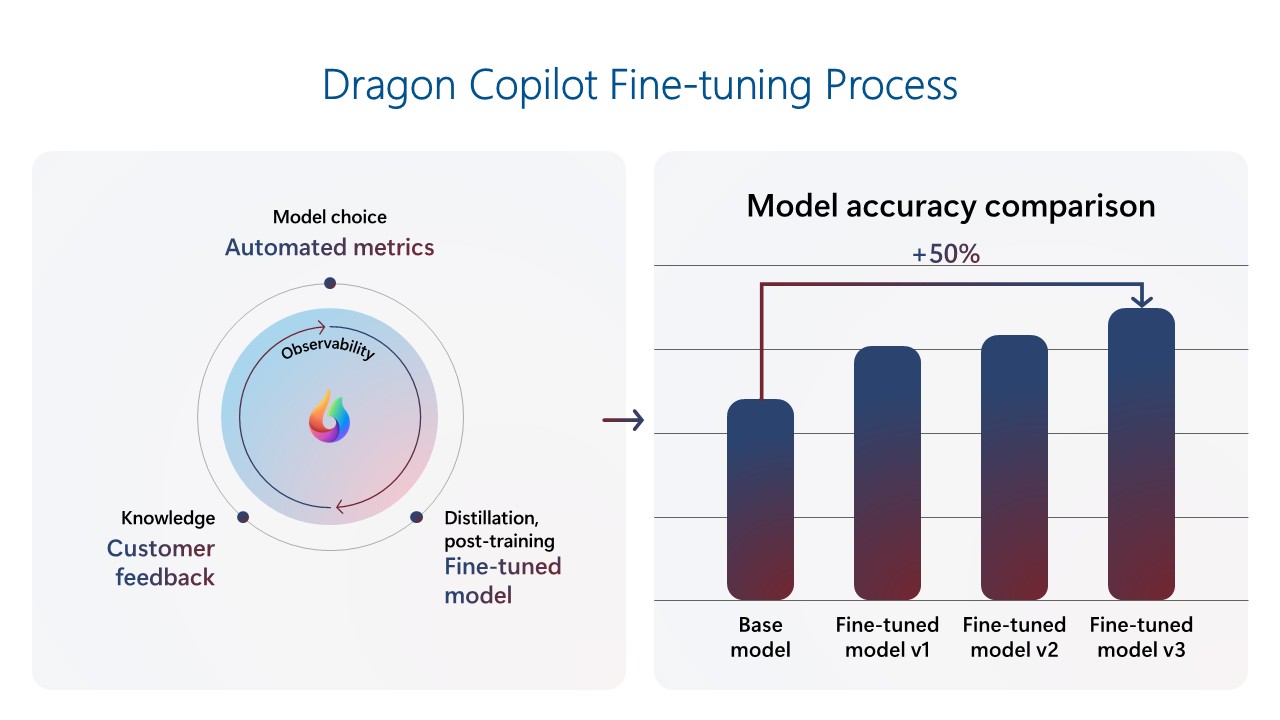
Dragon Copilot is a healthcare Copilot that helps doctors become more productive and deliver better patient care. The Dragon Copilot team has built a signals loop to drive continuous product improvement. The team built a fine-tuned model using a repository of clinical data, which resulted in much better performance than the base foundational model with prompting only. As the product has gained usage, the team used customer feedback telemetry to continuously refine the model. When new foundational models are released, they are evaluated with automated metrics to benchmark performance and updated if there are significant gains. This loop creates compounding improvements with every model generation, which is especially important in a field where the demand for precision is extremely high. The latest models now outperform base foundational models by ~50%. This high performance helps clinicians focus on patients, capture the full patient story, and improve care quality by producing accurate, comprehensive documentation efficiently and consistently.
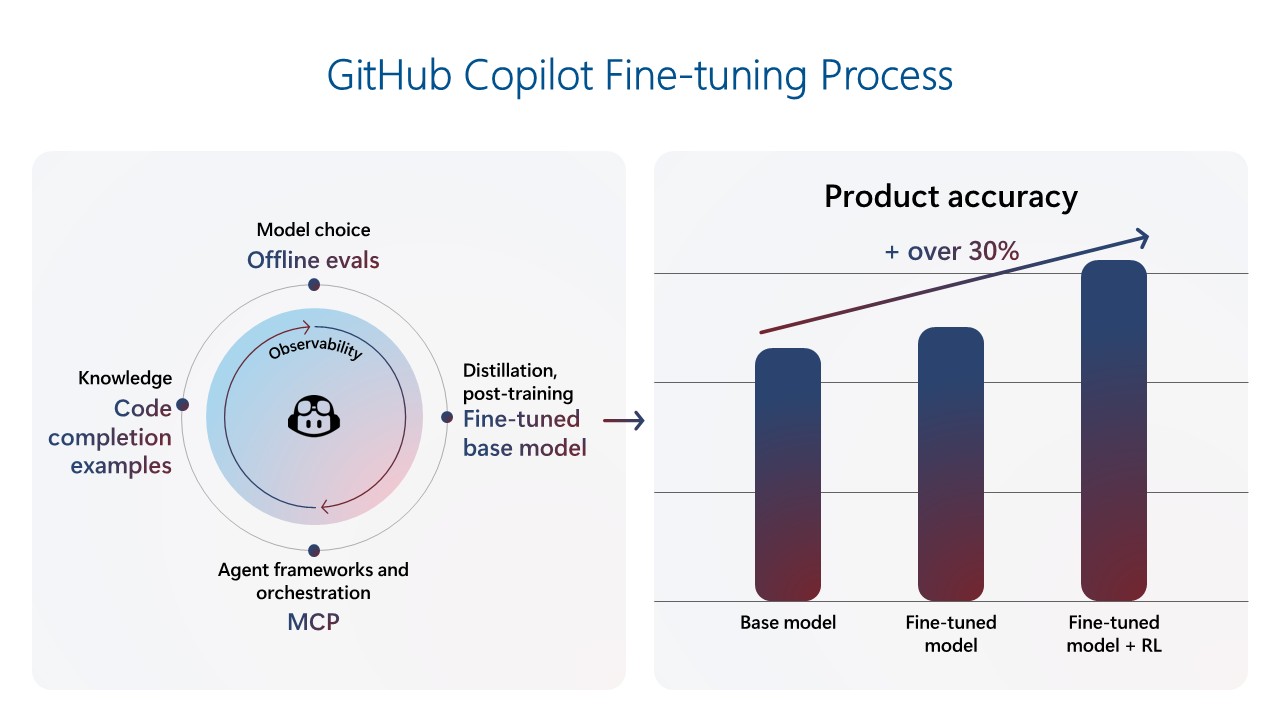
GitHub Copilot was the first Microsoft Copilot, capturing widespread attention and setting the standard of what AI-powered assistance could look like. In its first year, it rapidly grew to over a million users, and has now reached more than 20 million users. As expectations for code suggestion quality and relevance continue to rise, the GitHub Copilot team has shifted its focus to building a robust mid-training and post-training environment, enabling a signals loop to deliver Copilot innovations through continuous fine-tuning. The latest code completions model was trained on over 400 thousand real-world samples from public repositories and further tuned via reinforcement learning using hand-crafted, synthetic training data. Alongside this new model, the team introduced several client-side and UX changes, achieving an over 30% improvement in retained code for completions and a 35% improvement in speed. These enhancements allow GitHub Copilot to anticipate developer needs and act as a proactive coding partner.
Key implications for the future of AI: Fine-tuning, feedback loops, and speed matter
The experiences of Dragon Copilot and GitHub Copilot underscore a fundamental shift in how differentiated AI products will be built and scaled moving forward. A few key implications emerge:
- Fine-tuning is not optional—it’s strategically important: Fine-tuning is no longer niche, but a core capability that unlocks significant performance improvements. Across our products, fine-tuning has led to dramatic gains in accuracy and feature quality. As open-source models democratize access to foundational capabilities, the ability to fine-tune for specific use cases will increasingly define product excellence.
- Feedback loops can generate continuous improvement: As foundational models become increasingly commoditized, the long-term defensibility of AI products will not come from the model alone, but from how effectively those models learn from usage. The signals loop—powered by real-world user interactions and fine-tuning—enables teams to deliver high-performing experiences that continuously improve over time.
- Companies must evolve to support iteration at scale, and speed will be key: Building a system that supports frequent model updates requires adjusting data pipelines, fine-tuning, evaluation loops, and team workflows. Companies’ engineering and product orgs must align around fast iteration and fine-tuning, telemetry analysis, synthetic data generation, and automated evaluation frameworks to keep up with user needs and model capabilities. Organizations that evolve their systems and tools to rapidly incorporate signals—from telemetry to human feedback—will be best positioned to lead. Azure AI Foundry provides the essential components needed to facilitate this continuous model and product improvement.
- Agents require intentional design and continuous adaptation: Building agents goes beyond model selection. It demands thoughtful orchestration of memory, reasoning, and feedback mechanisms. Signals loops enable agents to evolve from reactive assistants into proactive co-workers that learn from interactions and improve over time. Azure AI Foundry provides the infrastructure to support this evolution, helping teams design agents that act, adapt dynamically, and deliver sustained value.
While in the early days of AI fine-tuning was not economical and required lots of time and effort, the rise of open-source frontier models and methods like LoRA and distillation have made tuning more cost-effective, and tools have become easier to use. As a result, fine-tuning is more accessible to more organizations than ever before. While out-of-the-box models have a role to play for horizontal workloads like knowledge search or customer service, organizations are increasingly experimenting with fine-tuning for industry and domain-specific scenarios, adding their domain-specific data to their products and models.
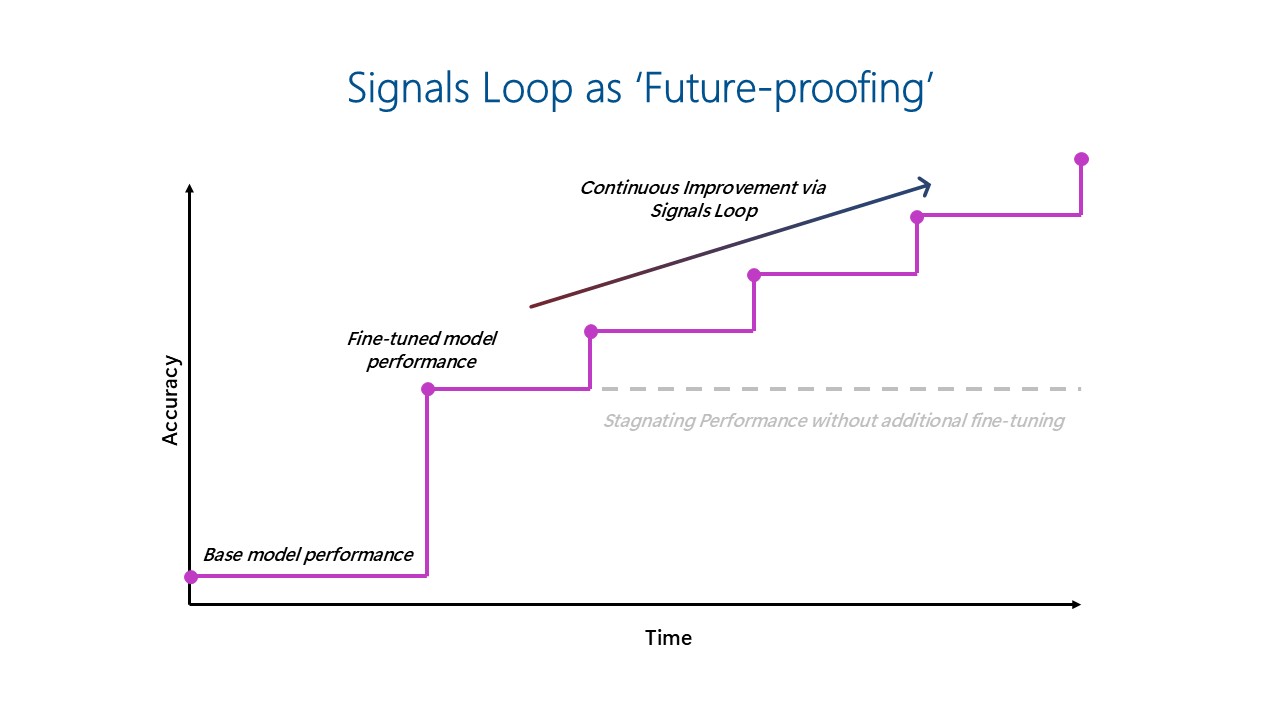
The signals loop ‘future proofs’ AI investments by enabling models to continuously improve over time as usage data is fed back into the fine-tuned model, preventing stagnated performance.
Build adaptive AI experiences with Azure AI Foundry
To simplify the implementation of fine-tuning feedback loops, Azure AI Foundry offers industry-leading fine-tuning capabilities through a unified platform that streamlines the entire AI lifecycle—from model selection to deployment—while embedding enterprise-grade compliance and governance. This empowers teams to build, adapt, and scale AI solutions with confidence and control.
Here are four key reasons why fine-tuning on Azure AI Foundry stands out:
- Model choice: Access a broad portfolio of open and proprietary models from leading providers, with the flexibility to choose between serverless or managed compute options.
- Reliability: Rely on 99.9% availability for Azure OpenAI models and benefit from latency guarantees with provisioned throughput units (PTUs).
- Unified platform: Leverage an end-to-end environment that brings together models, training, evaluation, deployment, and performance metrics—all in one place.
- Scalability: Start small with a cost-effective Developer Tier for experimentation and seamlessly scale to production workloads using PTUs.
Join us in building the future of AI, where copilots become co-workers, and workflows become self-improving engines of productivity.
Learn more
- Register for Ignite’s AI fine-tuning in Azure AI Foundry to make your agents unstoppable.
- Download the white paper: Learn how to unlock business-value with fine-tuning.
- Explore fine-tuning with Azure AI Foundry documentation.