
Earlier today, we disclosed a set of major updates to Azure Machine Learning designed for data scientists to build, deploy, manage, and monitor models at any scale. This has been in private preview for the last 6 months, with over 100 companies, and we’re incredibly excited to share these updates with you today. This post covers the learnings we’ve had with Azure Machine Learning so far, the trends we’re seeing from our customers today, the key design points we’ve considered in building these new features, and dive into the new capabilities.
Learnings so far
We launched Azure Machine Learning Studio three years ago, designed to enable established data scientists and those new to the space to easily compose and deploy ML models. Before the term was in use, we enabled serverless training of experiments built by graphically composing from a rich set of modules, and then deploying these as a web service with the push of a button. The service serves billions of scoring requests on top of hundreds of thousands of models built by data scientists. It has been incredibly rewarding to see how the service has been used by our customers including:
- Teaching Data Science in high school at the Australian School for Girls
- Predictive maintenance at Rolls-Royce
- Recognition of snow leopards from remote camera stations with the Snow Leopard Trust
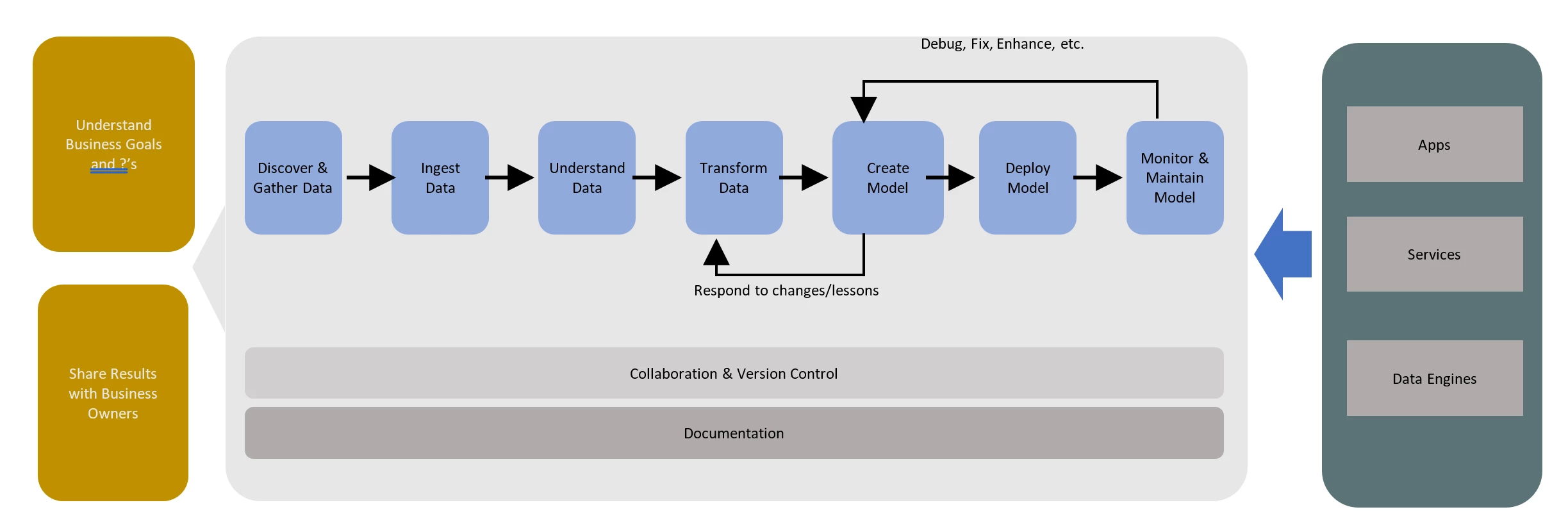
Over time we’ve worked with many customers who are looking for the next level of power and control and the capabilities we announced today address those desires. As we look at the data science workflow, we see customers walking through the following stages:
Key trends
Over the last few years, we’ve interacted with customers in every industry, with varying amounts of experience with ML, solving problems across every domain. Reflecting on those engagements, we see the following trends:
Accelerating adoption of ML and AI by developers – When we talk with developers, they are looking to create immersive, personalized, and productive experiences for their customers. More and more, we are seeing ML and AI capabilities becoming part of the way apps are being written. Within Microsoft, it’s been exciting to see how developers across the company are using AI in the applications we’re building. Two of my favorite examples come from the PowerPoint team. They have leveraged Microsoft Cognitive Services to build real-time translation and captioning capabilities and language understanding tools to transform bullet point lists into timelines. The Microsoft Cognitive Services, a set of 30 ready-to-use AI APIs, have been used by hundreds of thousands of developers looking to enhance their applications. This demand for AI by developers will only increase, further pushing organizations to provide easy to consume AI built on their data, as the way we write software evolves around these new capabilities.
Hybrid training and scoring – Every customer has a unique set of requirements on their data. Compliance, cost, regulation, physics, and existing processes and applications are all factors in where data and decisions can live. This poses a data management and movement challenge, as well as a need for tools, services, and frameworks that can operate across all data. Additionally, we need the ability to deploy the model in many places. While we see customers consolidating large amounts of data into data lakes and using tools like Spark for preparing and analyzing their data, the models they produce need to be deployed to a variety of form factors. We’ve seen two common hybrid patterns. The first involves sensitive data residing in an on-premises system being used to train a model that then gets deployed to the cloud or an application. The second involves training models on vast amounts of data ingested into the cloud (such as an IOT application), and then deploying that model on-premises or in a disconnected environment.
Scoring as close to the event as possible – Following on the above point, it is becoming more important for developers to be able to consume models everywhere, and we see a rise in edge and on-device based scoring. Recently, our Custom Vision Service enabled the ability to output a trained recognition model to CoreML for consumption directly within iOS. Customers in the IOT space are looking to put models directly onto devices, or onto gateway devices that can operate independently. Whether looking to address latency or the ability to support scoring even while disconnected, customers want the flexibility to train a model anywhere but control their deployment to place scoring as close to the event as possible.
Accelerating diversification of hardware, frameworks, and tools – One of the most exciting aspects of working in this space is the pace of innovation that we’re seeing across every layer of the stack. There is a dizzying array of tools to choose from, each being used in amazing ways. At the hardware layer, we see exponential increases in processing capabilities across CPU, GPU, FPGAs, and more. Over time, this innovation will result in mature toolchains, all the way to the hardware level that are optimized for specific workloads, letting customers tune and tradeoff cost, latency, and control. In the short term, we see customers experimenting to discover the best set of tools for their use case.
Design points
Given the learnings we’ve had, we’ve anchored our design on the following four points to shape these new capabilities
Machine Learning at scale
The services and tools we build must operate at scale, and we see customers encountering challenges with at least five different dimensions of “scale.”
Operating across all data – Customers must be able to have access to all their data to use building models at scale. In many cases, this means being able to use tools like Spark on increasing amounts of data in a data lake, but this is only part of the challenge. Customers need to be able to find and acquire the data, and then they need to be able to understand and shape the data. None of those stages can be bottlenecked as data sizes increase, so our tools need to scale from a local CSV file to petabyte-scale data lakes in the cloud.
Operating at increased compute needs (up and out) – Beyond the expansion of data, the techniques we’re using require scaling our processing power. Customers must be scale up onto machines that can fit huge datasets directly in memory, or machines with the latest GPUs for deep learning. Customers will scale out for problem sets on top of distributed data infrastructures like Spark, or for massively parallel processing in hyperparameter sweeps and model evaluation on top of our Azure Batch service. These two forces combine as we look to do deep learning at scale, requiring many scaled up machines.
Scaling the number of models and experiments you have – As teams increase the rate of experimentation, the number of experiments being run, and models being produced will increase. It becomes critical to be able to manage, monitor, and maintain those models. Teams need the ability to pinpoint and recreate any version of a model, and the number of artifacts that need to be tracked scales as organizations power more decisions with AI.
Scaling the consumption of models – Models produced, using any tools and frameworks, must be deployed in ways that enable easy scaling to serve any number of requests. For us, this means embracing container based deployment of models to enable customers fine-grained control, as well as being able to use services such as Azure Container Service to provide a scalable hosting layer in Azure.
Scaling the team – Data science teams are not teams of one. Our tools and services must enable collaboration and sharing, in a secure fashion, across all stages of the data science lifecycle. Much as source control systems have evolved for software development to flexibly support a variety of teams and processes, our system needs to support the AI development lifecycle as teams continue to grow.
Building with the tools you’re using today
There is no one framework or toolchain which rules them all. Given the rapid diversification of the ecosystem, our customers can experiment and choose the tools that will work best for them. The acceleration of innovation in the ecosystem also means that the tools and frameworks and techniques today are going to be different than those in six months’ time. Any service and tool that we build needs to enable data scientists to pick and choose from the ecosystem and use those tools, and we must build it in a way that provides a consistent experience for training, deployment, and management as these evolve.
One side effect of this expansion in the tools space is a challenge with reproducibility. In 12 months’ time, how will you recreate an experiment given that the tools have changed? Much like software developers needing to checkpoint a verified set of dependencies, our system needs to ensure that as frameworks come and go, you can reliably reproduce the results.
Increasing the rate of experimentation
When we look at the key areas of friction for data science teams, we consistently hear about challenges in:
- Acquiring, prepping, and understanding data
- Reliably scaling training, from rapid local prototyping and scaling to larger data sets
- Comparing and selecting models trained with different tools and techniques
- Deploying models to production
- Getting telemetry back from the deployed models to learn and improve the model
We believe that by eliminating the friction in each of these steps, and between these steps, teams will be able to increase their rate of experimentation. This lets them create better models more quickly, ultimately providing more value for their customers and increasing the efficiency of the team. The services and tools must reduce these key points of friction, while still preserving the flexibility and control required.
Models everywhere
Finally, the service we’re building must enable the deployment, management, and monitoring of models everywhere. It’s critical that our customers can have flexibility in their deployment form factor, including:
- Deploying to the cloud, for scalable web services for consumption by millions of devices or apps
- Deploying to a data lake, for processing data at scale in batch, interactive, and real-time streaming pipelines
- Deploying to a data engine, like SQL Server 2017, for scoring data inline for transaction processing and data warehousing
- Deploying to the edge, for moving the scoring as close to the event as possible and supporting disconnected scenarios
Diving into our new capabilities
Given these design points, we’ve released the following new capabilities for Azure Machine Learning
Experimentation
The Azure Machine Learning Experimentation service allows developers and data scientists to increase their rate of experimentation. With every project backed by a Git repository, and with a simple command line tool for managing experimentation and training runs, every execution can track the code, configuration, and data that’s used for the run. More importantly, the outputs of that experiment, from model files, log output, and key metrics are tracked, giving you a powerful repository with the history of how your model evolves over time.
The Experimentation service is built to allow you to leverage any Python tools and frameworks that you want to use. The experiments can run locally, inside of a Docker container locally or remotely, or scaling out on top of Spark. The power of Apache Spark in HDInsight enables data preparation and transformation, as well as training, across large amounts of your data. Deep learning based experimentation can occur on GPU accelerated virtual machines using any framework such the Microsoft Cognitive Toolkit, Tensorflow, Caffe, PyTorch, and more. Going forward, the Azure Batch AI service can be used to provide massive scaled out training, and then operationalized through the Model Management service.
Python libraries from Machine Learning Server (revoscalepy and microsoftml) available with Azure Machine Learning include the Pythonic versions of Microsoft’s Parallel External Memory Algorithms (linear and logistic regression, decision tree, boosted tree and random forest) and the battle tested ML algorithms and transforms (deep neural net, one class SVM, fast tree, forest, linear and logistic regressions). In addition, these libraries contain a rich set of APIs for connecting with remote data sources and deployment targets. Using these libraries, one can train a model with the Experimentation Service and operationalize these models wherever Machine Learning Server runs – SQL Server, HD Insight, Windows Server, Linux, and all three distributions of Spark; this power of training and operationalization is available for virtually every Python toolkit. This gives you the incredible power to build your models and operationalize them in the production data platforms right from your favorite data science environment.
We know that data science isn’t a linear process, and the Experimentation service lets you look back in time to compare experiments that produced the right results. When you find the right version, it’s easy to set your project to the exact code, configuration, and data that were used so you can start development from any point in history. Finally, by tracking the environment configuration, the Experimentation service makes it easy to quickly set up and configure new environments with exactly the same configuration. The Experimentation service manages training on your local machine, in Docker containers running locally or in the cloud, or on scale-out engines in Azure like Spark on HDInsight. By changing a command line parameter, you can easily move my job from local execution to the cloud.
Model Management
The Model Management service provides deployment, hosting, versioning, management, and monitoring for models in Azure, on-premises, and to IOT Edge devices. We’ve taken a key bet on Docker as the vehicle to provide customers with control, flexibility, and the convenience of containers as the mechanism for hosting models. With containers, you get a repeatable and consistent environment for hosting your models. Models are exposed via web services written in Python, giving you the ability to add more advanced logic, custom logging, state management, or other code into the web service execution pipeline. That logic is packaged up to construct a container which can be registered in your Azure Container Registry and then deployed using any standard Docker toolchain. When deploying models at scale on an Azure Container Service cluster, we’ve built a hosting infrastructure optimized for model serving, that handles automatic scaling of containers, as well as efficiently routing requests to available containers.
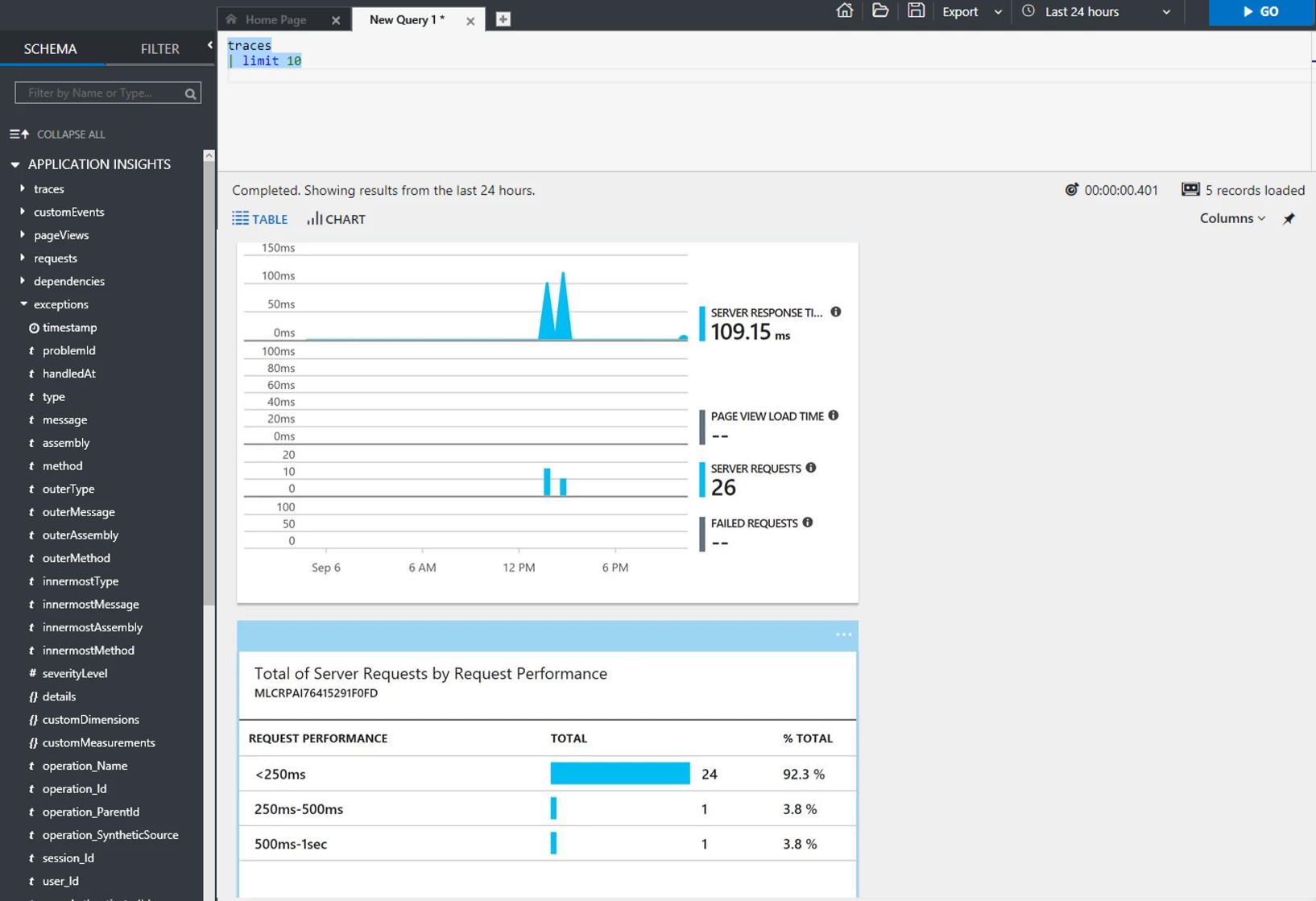
Deployed models and services can be monitored through Application Insights, giving you details on model execution, including specific model metrics, on a per-decision level. With deployed models, versions are tracked, enabling a link back to the specific code, configuration, and data used to create the model. Support is provided for managing deployments of model upgrades, enabling no-downtime while reliably deploying new versions, and allowing rollback to previous versions if required. Retraining scenarios, where a deployed model is monitored and then updated after being trained on new data, are possible, enabling continuous improvement of models based on new data.
One key benefit of this model is that it gives you full control over the deployment profile. Do you want to have a single cluster that is the host for all of your models? Do you want to deploy a cluster per department or customer? Do you have a single model that needs to support high call volumes during the day and scale down at night? Our goal is to give you control of the container hosting infrastructure in order to have the control and customization that have heard you ask for. You have full flexibility to choose the VM type and deployment profile, and we’ve made it easy to get started with the Data Science Virtual Machine as a single instance for development and testing before deploying to a cluster.
Models deployed through the Model Management service also surface swagger as an easy mechanism to consume the services from your code. Our partners in Excel are using this capability to make it incredibly easy to discover and consume models directly from Excel.
The Experimentation and Model Management services work together to provide governance and lineage of deployed models all the way back to the training job used to create the model. With telemetry enabled on a deployed model, this gives you visibility into any decision and the ability to trace the decision back to the experiment that created the model. This gives you a debugging and diagnostics story across the end to end lifecycle of a model.
Workbench
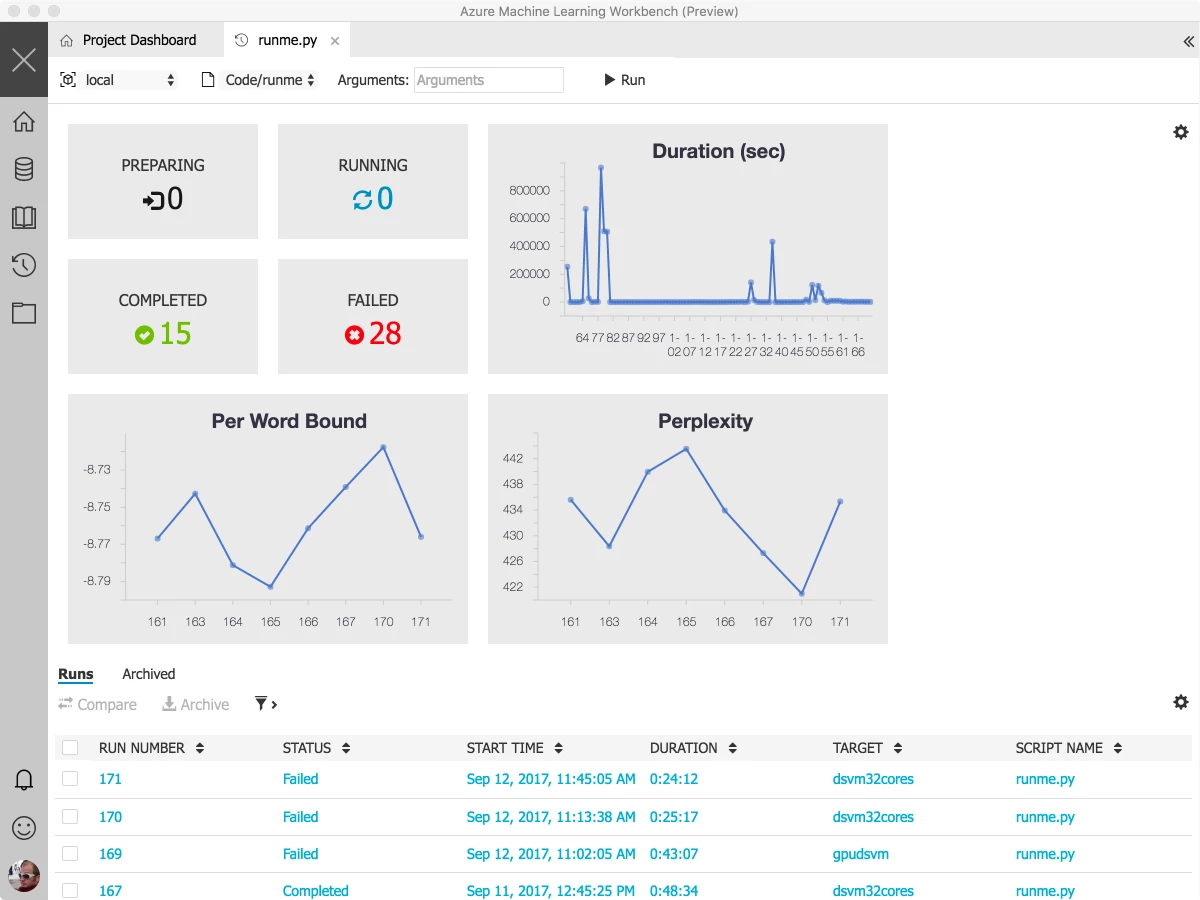
When we started working on this, we worked to ensure that our service is fully operable from the command line. But we also heard that there were challenges with environment set up, data wrangling, and visualizing run comparison. We’ve built the Azure Machine Learning Workbench as a companion application to your current development process, and we’re excited to get your feedback. The Azure Machine Learning Workbench is a client application that runs on Windows and Macs. It has an easy set-up and installation and will install a configured Python environment, complete with conda, Jupyter, and more, along with connectivity to all of the backend services in Azure. We intend it to be a control panel for your development lifecycle and a great way to get started using the services.
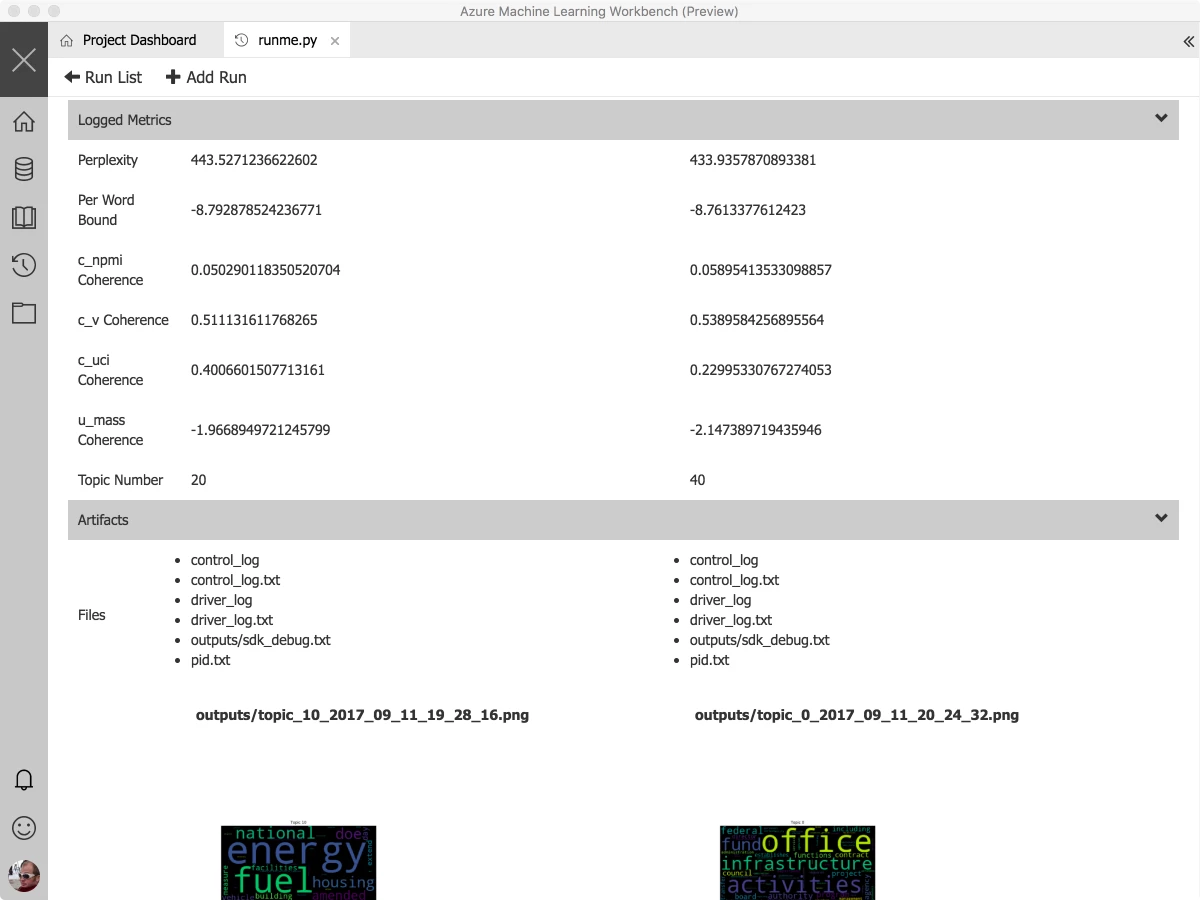
We’ve also put a rich set of samples into the application, with single-click training using a range of tools and techniques. You can see these by clicking “New Project.” The experimentation history management mentioned as part of the Experimentation service is shown below. You can get a glance of the evolution of key metrics over the history of your runs, get a detailed view of any individual run, and compare the performance side by side.
Any visualization you’ve built in your code, using matplotlib, for instance, will be archived and stored as part of the details of the run. In the screenshot below, you can see the wordclouds being emitted following some document analysis. Also, note that the Git commit id is included, enabling you to easily checkout from that commit if you want to pick up and start editing from where you were with this experiment.
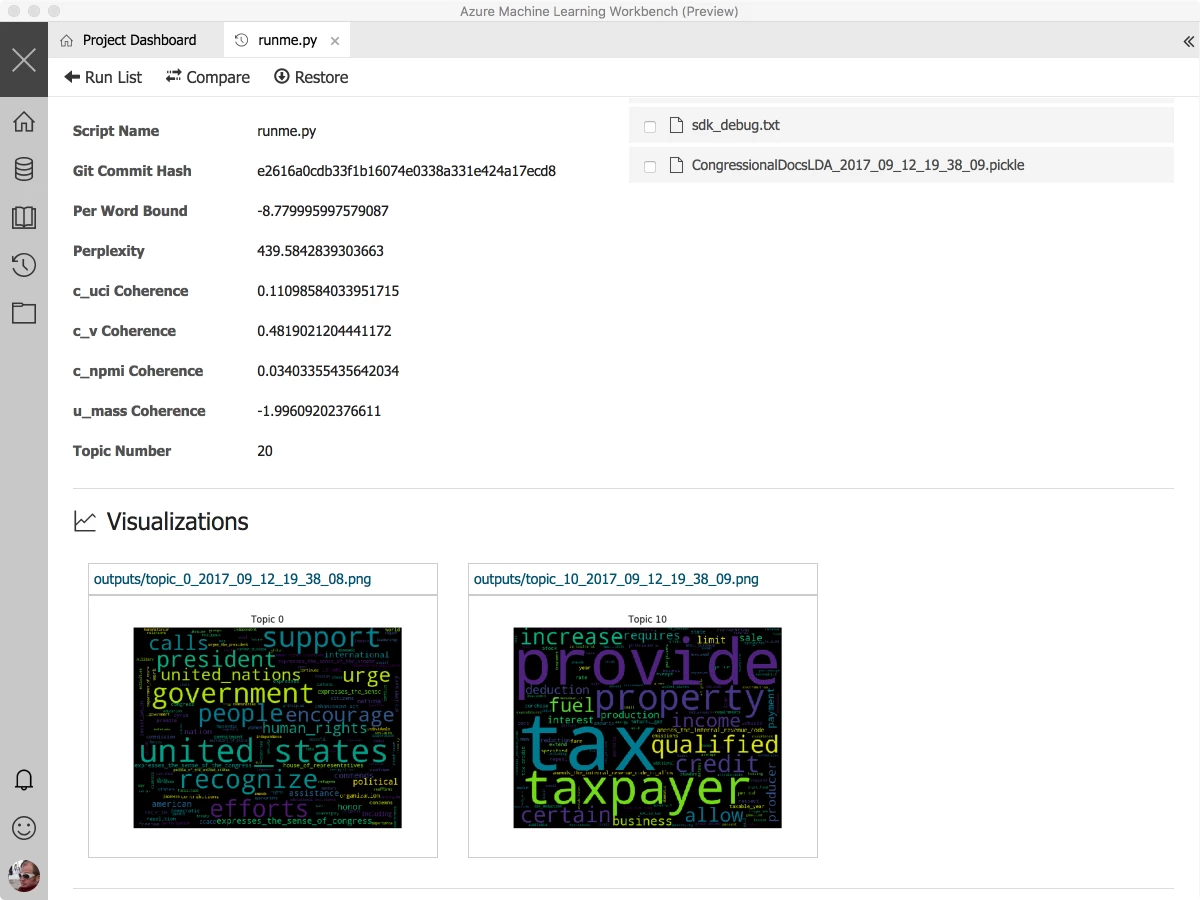
Finally, runs can be compared and evaluated side by side:
The Azure Machine Learning Workbench also hosts Jupyter notebooks that can be configured to target local or remote kernels, enabling iterative development within the notebook on your laptop, or hooked up to a massive Spark cluster running on HDInsight.
AI powered data wrangling
We know that one of the biggest areas where time is spent is in data preparation. We have consistent feedback on the challenges (and time spent) getting data, shaping it, and preparing it, and we are looking to make that better. We want to reduce the time and effort to acquire data for modeling, and we want to fundamentally change the pace with which data scientists can prepare and understand data, and accelerate the time to get to “doing data science.” As part of the Azure Machine Learning Workbench, we’re introducing a new set of data wrangling technology, powered by AI to make you more productive preparing data. We have combined a variety of techniques, using advanced research from Microsoft Research on program synthesis (PROSE) and data cleaning, to create a data wrangling experience that drastically reduces the time that needs to be spent getting data prepared. With the inclusion of a simple set of libraries for handling data sources, data scientists can focus on their code, not on changing file paths and dependencies when they move between environments. By building these experiences together, the data scientist can leverage the same tools in the small and in the large, as they scale out transparently across our cloud compute engines, simply by choosing target environments for execution.
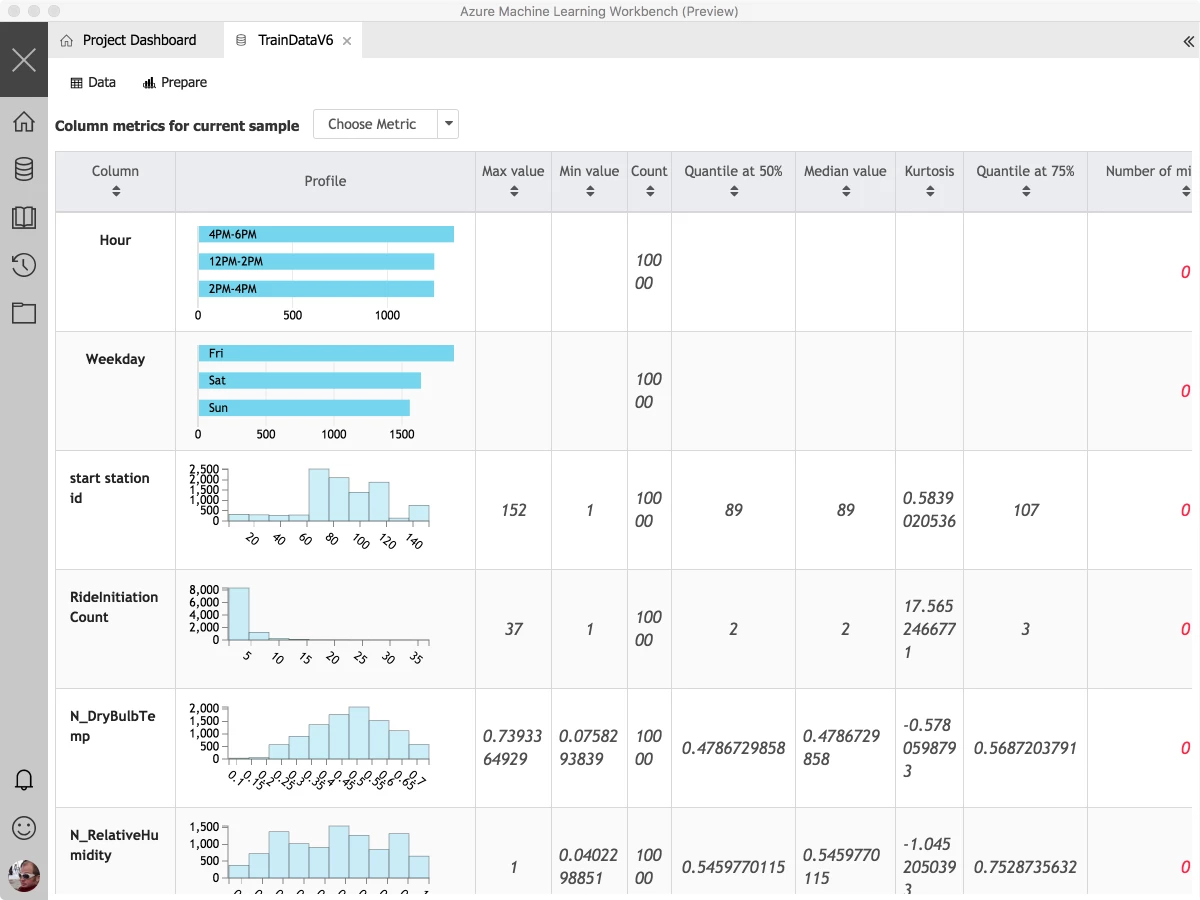
One of the most powerful capabilities of this data wrangling tool is building your data transformations by example. We know that a lot of time is spent on formats and transformations of numbers and dates, and have made it simple to transform data by providing examples. Here I’m taking a datetime string and changing it into a day of week + 2 hour bucket that I can later use to join or summarize my data set. If the transformations provided don’t fit what I need, it’s also easy to inject custom python code or libraries which can be used to filter or transform the data.
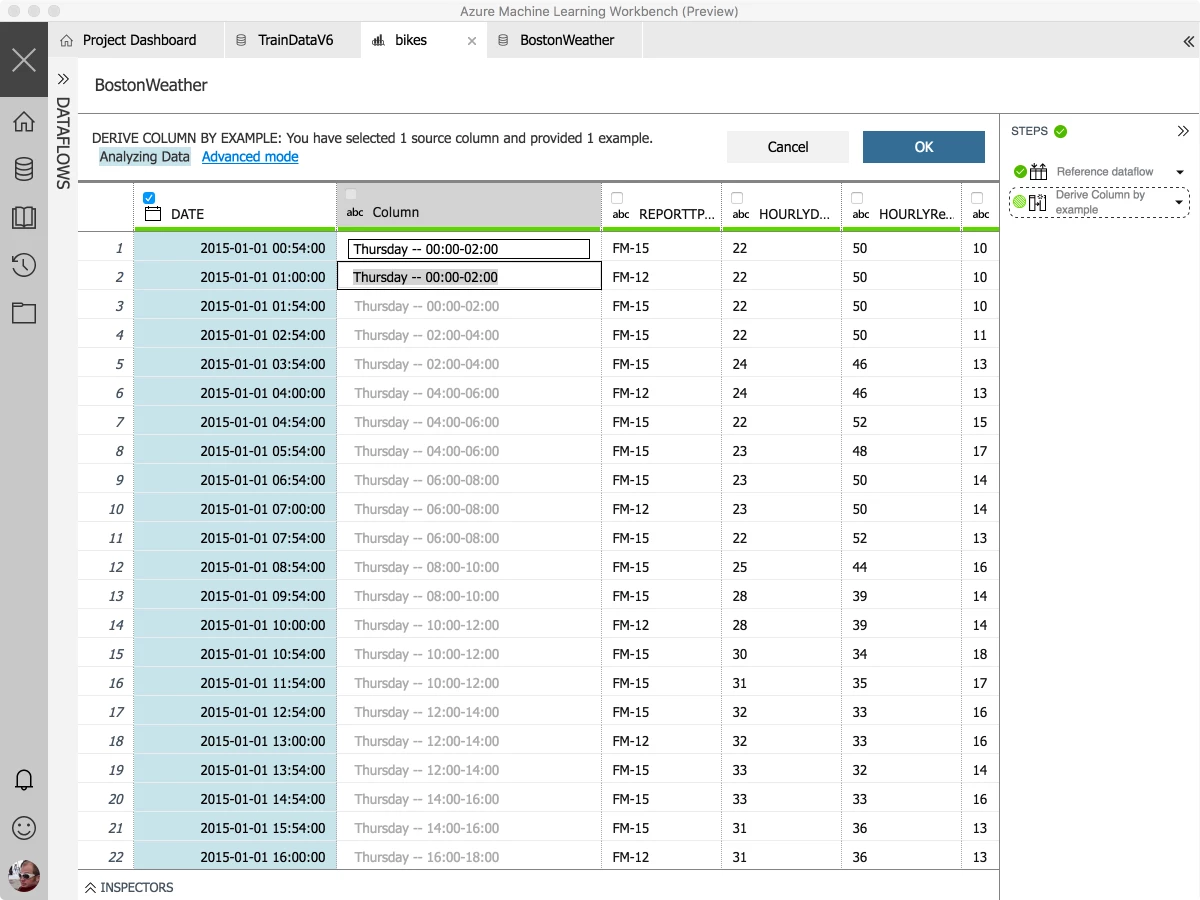
The data transformations you build can easily be incorporated into your Python code by easily returning a pandas dataframe containing the results of the transformation.
Generating the dataframe creates the following code:
# Use the Azure Machine Learning data wrangling package
from azureml.dataprep import package
# Use the Azure Machine Learning data collector to log various metrics
from azureml.logging import get_azureml_logger
logger = get_azureml_logger()
# This call will load the referenced package and return a DataFrame.
# If run in a PySpark environment, this call returns a
# Spark DataFrame. If not, it will return a Pandas DataFrame.
df = package.run('bikes.dprep', dataflow_idx=0)
# Remove this line and add code that uses the DataFrame
df.head(10)
Visual Studio Code Tools for AI
Finally, we know that it’s important for you to use the development tools of your choice, and we want to make that experience work seamlessly with our new services in Azure. We’re pleased to announce our first editor integration with the release of the Visual Studio Code Tools for AI. This extension provides a rich set of capabilities for building models with deep learning frameworks including Microsoft Cognitive Toolkit (CNTK), Google TensorFlow, Theano, Keras and Caffe2, while integrating with the Experimentation service for executing jobs locally and in the cloud, and for deployment with the Model Management services.
Getting started
If you’re interested in learning more, head over and check out our documentation on how to deploy a new account in Azure. You can also find a great set of quick start guides, as well as detailed tutorials walking through the features of the service.
- Setup and installation
- Quick start sample – Iris
- In depth, three part Iris classification tutorial
- In depth data wrangling tutorial
Data scientists on our team have put together detailed scenario walkthroughs, complete with sample data, for you to get started on some interesting challenges or adapt their techniques to your next problem, including:
- Aerial image classification
- Document collection analysis
- Predictive maintenance
- Time series based forecasting
We’re constantly working on and refreshing the documentation, if you have a comment or suggestion, please let us know.
What’s next
Today, these services and tools are available as a public preview in Azure. In the coming months, we will bring the service to GA while we continue to work with customers and use their feedback to guide the key features, updates, and global rollout. We invite you to engage with the team through our feedback site, on our MSDN forum, or tag us on twitter with the #AzureML. Senior PM Ted Way will be presenting a webinar on October 4, 2017 if you’re interested in learning more.
This is the start of an exciting journey, and we can’t wait to work with you on it!