

This post was co-authored by Mark Hamilton, Sudarshan Raghunathan, Chris Hoder, and the MMLSpark contributors.
Integrating the power of Azure Cognitive Services into your big data workflows on Apache Spark™
Today at Spark + AI Summit 2019, we’re excited to introduce a new set of models in the SparkML ecosystem that make it easy to leverage the Azure Cognitive Services at terabyte scales. With only a few lines of code, developers can embed cognitive services within your existing distributed machine learning pipelines in Spark ML. Additionally, these contributions allow Spark users to chain or Pipeline services together with deep networks, gradient boosted trees, and any SparkML model and apply these hybrid models in elastic and serverless distributed systems.
From image recognition to object detection using speech recognition, translation, and text-to-speech, Azure Cognitive Services makes it easy for developers to add intelligent capabilities to their applications in any scenario. To this date, more than a million developers have already discovered and tried Cognitive Services to accelerate breakthrough experiences in their application.
Azure Cognitive Services on Apache Spark™
Cognitive Services on Spark enable working with Azure’s Intelligent Services at massive scales with the Apache Spark™ distributed computing ecosystem. The Cognitive Services on Spark are compatible with any Spark 2.4 cluster such as Azure Databricks, Azure Distributed Data Engineering Toolkit (AZTK) on Azure Batch, Spark in SQL Server, and Spark clusters on Azure Kubernetes Service. Furthermore, we provide idiomatic bindings in PySpark, Scala, Java, and R (Beta).
Cognitive Services on Spark allows users to embed general purpose and continuously improve intelligent models directly into their Apache Spark™ and SQL computations. This contribution aims to liberate developers from low-level networking details, so they can focus on creating intelligent, distributed applications. Each Cognitive Service is a SparkML transformer, so users can add services to existing SparkML pipelines. We also introduce a new type of API to the SparkML framework that allows users to parameterize models by either a single scalar, or a column of a distributed spark DataFrame. This API yields a succinct, yet powerful fluent query language that offers a full distributed parameterization without clutter. For more information, check out our session.
Use Azure Cognitive Services on Spark in these 3 simple steps:
- Create an Azure Cognitive Services Account
- Install MMLSpark on your Spark Cluster
- Try our example notebook
Low-latency, high-throughput workloads with the cognitive service containers
The cognitive services on Spark are compatible with services from any region of the globe, however many scenarios require low or no-connectivity and ultra-low latency. To tackle these with the cognitive services on Spark, we have recently released several cognitive services as docker containers. These containers enable running cognitive services locally or directly on the worker nodes of your cluster for ultra-low latency workloads. To make it easy to create Spark Clusters with embedded cognitive services, we have created a Helm Chart for deploying a Spark clusters onto the popular container orchestration platform Kubernetes. Simply point the Cognitive Services on Spark at your container’s URL to go local!

Add any web service to Apache Spark™ with HTTP on Spark
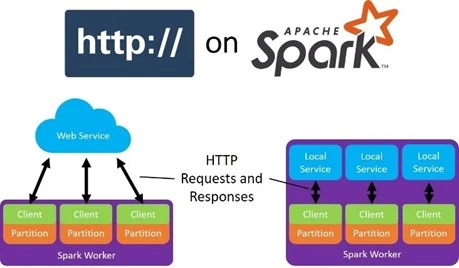
The Cognitive Services are just one example of using networking to share software across ecosystems. The web is full of HTTP(S) web services that provide useful tools and serve as one of the standard patterns for making your code accessible in any language. Our goal is to allow Spark developers to tap into this richness from within their existing Spark pipelines.
To this end, we present HTTP on Spark, an integration between the entire HTTP communication protocol and Spark SQL. HTTP on Spark allows Spark users to leverage the parallel networking capabilities of their cluster to integrate any local, docker, or web service. At a high level, HTTP on Spark provides a simple and principled way to integrate any framework into the Spark ecosystem.
With HTTP on Spark, users can create and manipulate their requests and responses using SQL operations, maps, reduces, filters, and any tools from the Spark ecosystem. When combined with SparkML, users can chain services together and use Spark as a distributed micro-service orchestrator. HTTP on Spark provides asynchronous parallelism, batching, throttling, and exponential back-offs for failed requests so that you can focus on the core application logic.
Real world examples
The Metropolitan Museum of Art

At Microsoft, we use HTTP on Spark to power a variety of projects and customers. Our latest project uses the Computer Vision APIs on Spark and Azure Search on Spark to create a searchable database of Art for The Metropolitan Museum of Art (The MET). More Specifically, we load The MET’s Open Access catalog of images, and use the Computer Vision APIs to annotate these images with searchable descriptions in parallel. We also used CNTK on Spark, and SparkML’s Locality Sensitive Hash implementation to futurize these images and create a custom reverse image search engine. For more information on this work, check out our AI Lab or our Github.

The Snow Leopard Trust
We partnered with the Snow Leopard Trust to help track and understand the endangered Snow Leopard population using the Cognitive Services on Spark. We began by creating a fully labelled training dataset for leopard classification by pulling snow leopard images from Bing on Spark. We then used CNTK and Tensorflow on Spark to train a deep classification system. Finally, we interpreted our model using LIME on Spark to refine our leopard classifier into a leopard detector without drawing a single bounding box by hand! For more information, you can check out our blog post.

Conclusion
With only a few lines of code you can start integrating the power of Azure Cognitive Services into your big data workflows on Apache Spark™. The Spark bindings offer high throughput and run anywhere you run Spark. The Cognitive Services on Spark fully integrate with containers for high performance, on premises, or low connectivity scenarios. Finally, we have provided a general framework for working with any web service on Spark. You can start leveraging the Cognitive Services for your project with our open source initiative MMLSpark on Azure Databricks.
Learn more
Email: mmlspark-support@microsoft.com





