

Takeaway: Brain is Azure’s AI-powered cloud reliability intelligence system: an AIOps system that sits as an intelligent layer on top of Azure Resource Graph and fuses platform telemetry, AI/ML models, service dependencies, and customer impact into a single, continuously updated view of how every service, region, and workload is performing. It already powers customer Azure resource health notifications, deployment safeguards, and outage declaration, and it is the foundation for agentic AI now reshaping how Azure operates. This post starts a multi-part series on what Brain is, how we built it, what we’ve learned operating it at scale, and where it goes next.
How Azure’s AI-powered reliability intelligence system works
Azure runs on a digital twin of its own health. Brain is an AIOps-powered cloud health intelligence system that operates as an intelligent layer on top of Azure Resource Graph (ARG); together, they form this digital twin. It integrates platform telemetry, AI/ML models, and data engineering to continuously maintain and enrich a real-time view of how services, regions, and customer workloads are performing across Azure. Over time, that shared picture is becoming the foundation for a more automated reliability surface: one that can turn insight into action.
Today, Brain already powers important reliability workflows across Azure, such as health notifications for customer’s resources, deployment safeguards, and outage declaration. If you run on Azure, Brain is already changing three things you can notice:
- How fast we tell you when something is wrong.
- How accurately we scope it to your resources.
- How quickly the right engineer gets on it.
This post is about how and what it lets you do differently.
We’re starting a multi-post series with this one to take you through what Brain is, how we built it, what it has learned operating Azure at scale, and where it goes next. Today, the foundation.
Why Brain is needed
Azure runs hundreds of services across more than 80 Azure regions, over 500 datacenters, and over 800,000 kilometers of fiber and subsea cable, representing one of the world’s largest global cloud footprints. And yet with the massive amount of activity these Azure services create, manage, and process worldwide, on a quietly degrading day, we will sometimes still learn about an issue from a customer before our own systems do. For customers, that gap is the worst kind of incident; the one where they are debugging their own application before they learn the fault was ours.
That gap between what we measure and what we know is the limiting factor on cloud reliability today. It is not a tooling problem. We have plenty of tools. It is a comprehension problem. The amount of signal a hyperscale cloud produces has outgrown the human ability to read it, and the conventional answer: more dashboards, more alerts, more on-call rotations. It’s a treadmill, not an answer. Every additional dashboard gives an operator another window to look through; what’s missing is something that tells them what they’re looking at, in time to act.
Closing that gap meant building something we hadn’t built yet: not better dashboards, not smarter alerts, but a continuously updated model of the platform’s health that reasons across every signal in real time, and acts on those conclusions automatically at the scale the platform demands.
What is Brain? Azure’s centralized AIOps for cloud reliability
Brain is Azure’s centralized AIOps-powered cloud health intelligence system that uses AI/ML, including agentic AI and data engineering, to continuously model Azure’s health and to automatically take reliability actions based on it. It has been utilized in Azure production generating resource health determinations across the platform.
At its core, Brain is shaped by three things: what goes in, what comes out, and what those outputs drive.
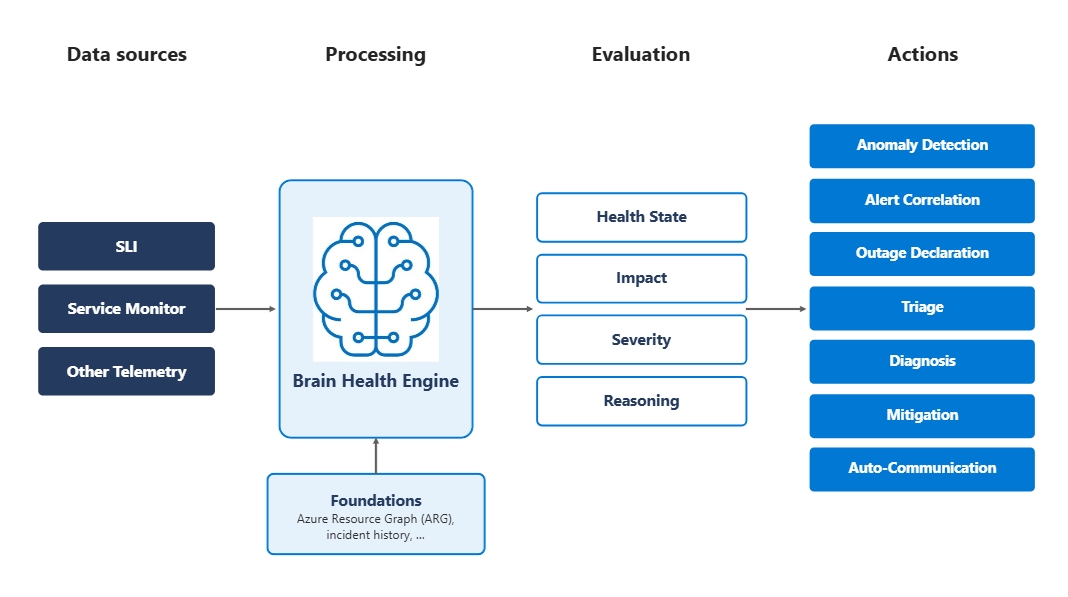
Brain ingests signals from three classes of source:
- Standardized service-level indicators: the SLIs Azure customers and operators already know from their reliability dashboards.
- Domain-specific monitors that individual service teams have built and registered with Brain, and the broader telemetry stream including deployments, support volume, and cross-service dependency signals.
- Third-party indicators that surround every Azure operation.
Each path serves a different purpose; together, they give Brain coverage that no single path could.
Regardless of the input, Brain evaluates every subject (service, region, deployment unit, or customer resource) and returns four outputs: health state, severity, impact, and the reason for its conclusion. Standard outputs in standard vocabulary mean every downstream system speaks the same language; no more disconnect in what “impacted” means across teams.
The insights generated by Brain power a growing set of automated reliability actions, including:
- Outage declarations based on blast radius.
- Customer notifications targeted to affected subscriptions and regions.
- Incident routing to the appropriate service team.
- Deployment gates that pause harmful rollouts.
- Linking related incidents.
- Diagnostic tools that help engineers investigate issues.
Foundations of Azure’s digital twin for cloud health
To understand what makes “the intelligence system” different from “a dashboard,” it helps to look at what’s actually in its foundation. Brain’s representation of Azure carries, at minimum:
- Topology: every service, region, availability zone, deployment unit, and dependency graph enabled by Azure Resource Graph is represented as a live model that updates as services scale, dependencies change, and new components come online. This transparency into Azure service health and downstream impact helps Azure customers understand and diagnose application issues more quickly and improves the reliability of applications built on Azure.
- Service catalog: what each service does, who owns it, what its tier is, what its expected behavior looks like, and what its service-level objectives are.
- Runtime state: live indicators of how every component is currently behaving, including error rates, latency, throughput, resource utilization, and error distributions across customers.
- Intent: what’s supposed to be happening right now, which deployments are in flight, which planned operations are underway, and which capacity changes are scheduled.
- History: prior incidents, what caused them, what mitigated them, and which signals preceded them. The system’s working memory of how Azure has gotten unhealthy before, and what worked to fix it.
- The customer’s view: what each tenant is currently experiencing. Not just what the platform is emitting, but what’s actually arriving at the customer’s application. Errors customers see, latency customers feel, and regions where their traffic is succeeding or failing.
None of these are novel on their own: every cloud platform has versions of each. Brain brings them together into a single, unified, AI-driven representation instead of scattering them across twelve separate dashboards in twelve separate tools that an operator has to mentally connect under time pressure.
When Brain says a service is degrading, that statement is not a threshold being crossed. It is a determination made by reasoning across topology, runtime state, current intent, historical patterns, and customer-side evidence simultaneously. It is the intelligence system speaking, not a metric firing. And it is the speed of that determination measured in seconds, not in the minutes a human would take to assemble the same picture from separate tools that translates directly into customer experience: shorter incidents, sharper notifications, and faster routing.
What it means to operate against a cloud intelligence system
This is the move that changes everything for an Azure customer, and it’s the one most easily missed if you read “digital twin” as a metaphor rather than as a system.
Consider how a deployment-driven degradation typically resolves in two different worlds.
In a world without a shared intelligence system, the work is reconstruction. A rollout is in flight. A region’s error rate begins to drift.
- The team that owns the service sees the drift in their dashboard.
- The team that owns the upstream dependency sees a different metric drift in their dashboard.
- The team that owns the deployment system sees the rollout proceeding normally from their dashboard.
- None of those three teams initially have the picture; they get on a bridge and assemble it from fragments. While they assemble, the customer impact spreads. By the time the connection between the rollout, the dependency, and the customer-visible errors is made, by humans, under pressure, mid-incident, the rollout has reached more regions, the customer ticket queue has grown, and the resolution is now harder than it had to be.
In a world with the intelligence system, the work is consumption. The rollout is in the intelligence system, Brain knows it’s in flight: what it’s changing, what regions it’s reaching, what it’s supposed to do. The error-rate drift is in the system: Brain sees it correlated to the rollout, weighted against the dependency graph, evaluated against historical patterns of what “small wobble” looks like versus what “real degradation” looks like.
The affected customers are in the system, their tenants map to platform resources affected by the upstream dependency, which is itself affected by the rollout. Brain produces a single determination: the rollout is causing customer-visible impact in this region; expected resolution requires the rollout to pause.
That determination then flows, at the same moment, to every system that needs to act on it. The deployment system pauses the rollout while the determination is true, so the next set of customers Brain would have impacted aren’t impacted at all.
The incident management system creates a single incident with the upstream dependency identified, not three duplicate incidents from three confused teams so the right engineer reaches the right problem first. The customer communication system drafts a notification with the right tenant scope and the right plain-English description, so the customers who are affected receive updates from Microsoft sooner, with information they can actually use.
For Azure customers, none of that coordination is visible. What’s visible is a shorter incident, an accurate alert that hit their automation instead of a human, and diagnosis that was already named when their on call opened the bridge. On services where Brain’s resource-health evaluation is in production, detection precision for service-impacting issues has improved significantly, and coverage of in-scope incidents continues to expand.
In the past year, a substantial majority of Brain-integrated outages were auto-communicated to affected customers, and on those, time-to-notification improved materially compared to manually issued notifications.
None of those downstream systems are doing their own investigation. They all consume the same determination from the intelligence system, in the same vocabulary, with the same supporting evidence. That is what “operating against an intelligence system” means and it is the first thing we found we had to build before any of the agentic AI work that people associate with Azure today became viable.
This not only helps to improve Azure’s reliability, but also benefits Azure customers who built their applications on top of Azure by providing transparency of service health and timely communications.
The future of agentic AI and cloud operations
There is a larger conversation happening across the cloud industry this year about agentic AI and about AI systems that act, not just observe. Microsoft is part of that conversation. But the conversation has a quiet asymmetry that gets less attention than it deserves.
Agents need something to be agentic about:
- A triage agent that doesn’t know the dependency graph cannot triage anything.
- A diagnosis agent that cannot reach prior incident history cannot reason about root cause.
- A communication agent that doesn’t know which customers are actually affected cannot write to them.
- None of these systems are meaningfully autonomous; none of them deserve your trust if every one of them has to do their own investigation of what reality is, every time, from raw signals.
That is what made the health intelligence system “the digital twin”: the prerequisite, not the consequence, of agentic operations at this scale. Build the agents first, on top of fragmented data, and you get a federation of confident systems that disagree with each other in production. Build the model first, and the agents become composable: they reason from the same picture, and the picture is one you can audit.
This is the throughline of the series we’re starting today. Brain is the cloud health intelligence system the next generation of cloud agents will need. If your organization is exploring agentic AI for any operations function: your cloud, your applications, or your infrastructure, the architectural pattern Brain represents is one to look at carefully. The agents are the headline; the intelligence system underneath is the work.
What’s next for Azure reliability and Brain
We have the system. The system has determination. A service in a region is degrading.
However, degrading compared to what? Healthy by whose definition? When two teams disagree about whether their service is healthy, which one is right? When the platform is degrading but no individual customer is impacted yet, what state are we actually in?
Those are not philosophical questions. They are the next engineering questions we have to answer, because a system cannot make determinations until the people building it agree on what determinations actually are. Most of the industry, until recently, has been quietly getting this wrong.
In the next post in this series, we’ll show you exactly how, and what we built to replace the broken vocabulary of cloud health that the industry has been operating on for the last decade. To follow the series as new posts are published, see the Advancing reliability blog tag.
Azure reliability
Query, explore, and analyze your cloud resources at scale.

Acknowledgments
This work reflects the contributions of many engineers and researchers across the Brain AIOps team, MSR (Microsoft Research), and Azure service teams.





