
For operators, many challenges can be involved in their journey to the cloud, some more complex than others. Here, it is important to note that when it comes to operators’ path to cloud migration, there is no such thing as a one-size-fits-all solution. Operators have unique needs for security, observability, resiliency, and performance.
As a result, Microsoft offers a level of support for operators that is far greater than simply taking existing cloud services and repackaging them. We understand that it is critically important to know exactly what operator workloads require—including what it takes to meet the demands imposed by operators as a result of their commitment to delivering fault-tolerant services to customers.
In this blog, we delve into one such example of Microsoft’s commitment to operators and to developing a hands-on product strategy born from years of research. This has led directly to solutions that we offer operators today as part of Azure of Operators.
Bringing a cellular packet core to the cloud
Several years ago, Microsoft started work on a research project aimed at determining the feasibility of implementing a cellular core network (EPC) on a hyperscale public cloud. What came from this work was a research prototype of a distributed network architecture for the EPC on the public cloud. It ran as a cloud service, provisioning for high network availability while balancing the unpredictability of public clouds. Keeping the original EPC design, this prototype cloud EPC provided the same basic function of a cellular core network and was compatible with standard cellular equipment (such as phones and base stations).
To better understand the needs of operators planning to migrate to the cloud, we deployed the cloud EPC on Azure and tested it using a combination of real mobile phones and synthetic workloads. It demonstrated higher availability when compared to existing telco solutions at the time, as well as a level of performance that was comparable to many commercial cellular networks.
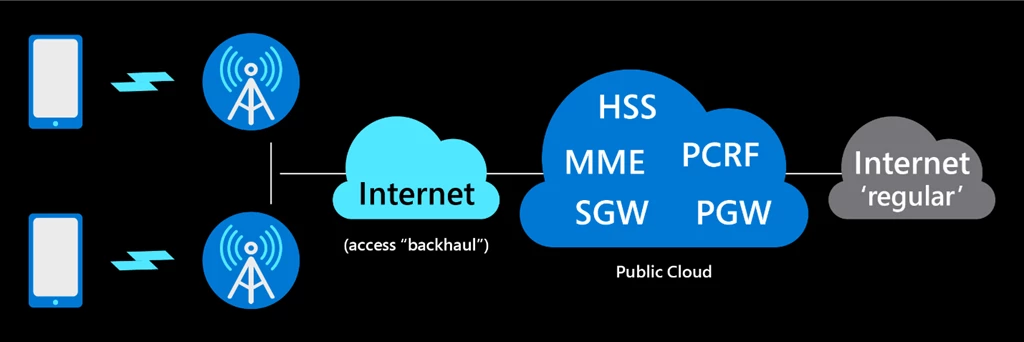
Figure 1: Research prototype for high-level network deployment
In the end, this work offered the possibility of a distributed network architecture leveraging the public cloud—evidence of Microsoft’s ability to potentially relieve operators of the burden of managing their own infrastructure.
Going a step further
For Microsoft, the aforementioned project was just the start of building greater awareness and expertise—both of which are now being used to the benefit of operators on their cloud migration journeys. So, to further understand how the earlier prototype cloud EPC might perform in the real world while carrying actual mobile traffic, learnings from this early project were incorporated into a real-world cellular network trial that lasted two years.
The real-world experiment was created in conjunction with the city of Cambridge in the United Kingdom. Consisting of five cellular towers installed at various points across the city, the experiment was designated to benefit underserved communities that lacked traditional broadband access. Microsoft deployed the cloud EPC on public Azure regions located in Dublin, Ireland, in parallel with a failover positioned in Amsterdam, the Netherlands. The trial with this small network ran successfully for the entire period, functioning without a single outage. Microsoft gained a wealth of technological and operational data that we currently leverage for the benefit of operators today.

Figure 2: Data from the Cambridge trial
Four key lessons learned
1. It’s very doable
One of the most important outcomes of the Cambridge trial is the notion that a telecom-grade virtual network function (VNF) can indeed work on the hyperscale public cloud. Even though the EPC was in the cloud outside of the country, Microsoft could still provide a live LTE network with solid network performance. Traffic reached between 20 to 40GB each day, and the maximum link throughput was more than 20 Mbps (with 2×2 MIMO on 5MHz); during this time, most users received at least 4 Mbps in download speeds.
2. Setup is much faster
Operators want to know what tools and services are available to make sense of the complexities of moving to the cloud. Based on our experiment, locating the EPC on the cloud makes a cellular roll-out far easier. It could have taken months to procure and commission traditional EPC equipment alone, not to mention the need for capital expenditure. Instead, it took less than five minutes to initiate it in a new Azure region.
3. It’s highly reliable
Addressing the concerns that hyperscale clouds are not up to the high availability standard that operators require, this study proved that VNFs running on Azure can be highly reliable. In measuring the reliability of various Azure components over a three-month period, Azure met four nines availability, which was sufficient for the trial. Here, it is key to note that other services within Azure (such as Azure ExpressRoute, and deployments across Azure Availability Sets and Azure Availability Zones, plus reliable data stores) could be incorporated into the deployment to improve network uptime further.
4. It’s easy to maintain
Another important finding from the experiment was the ease of network management. Microsoft was able to write a network management interface on Azure to conduct daily operations. And by leveraging Azure’s data analytics tools, we were able to monitor the network health and generate alerts through the Azure portal. We achieved all this without writing a single line of code, thereby enabling a single team member to manage the entire network.
What does this mean for operators today?
Microsoft continues to refine its strategy and portfolio of services based on research such as the Cambridge trial, practical experience with hundreds of customers running networks using advanced technology, and deep relationships with operators globally. Some of the design features taken from these learnings include:
The use of microservices-based architectures to reduce footprint and improve performance
For example, our IP Multimedia Core Network Subsystem (IMS) was the first commercial cloud-native network function built specifically to run inside containers within hybrid cloud architectures. Recognizing that a small compute footprint is required to meet the financial demands of operator infrastructures, care was taken to ensure that the microservices methodologies employed were granular enough to realize the benefits of resiliency, flexibility, and scalability, but not so granular that they impact data persistence and performance.
Additional complexities had to be considered for network functions supporting real-time user traffic, requiring new data plane acceleration and packet processing pipeline innovations that can provide near-silicon-like throughput without using excessive CPU cycles or custom hardware. These technologies were first employed within our Session Border Controller and later within the 5G core, built specifically for multi-access edge compute environments where resources are incredibly constrained.
Similarly, solutions such as Unity Cloud Orchestration have harnessed cloud-native technologies to simplify orchestration by using a single tool such as Kubernetes to manage containerized network functions. Unity Cloud reduces times and complexity in capacity and high availability network planning, as these functions are dynamically managed. And Unity Cloud simplifies feature delivery and the software and patch upgrade process using microservices.
The use of an automated management layer to reduce operational costs
The service automation capabilities enabled by ServiceIQ and Unity Cloud Operations—exposed as application programming interfaces (APIs) to a business intelligence layer, allow operators to create networks that are more secure, flexible, efficient, scalable, and resilient. These networks will be:
- Self-healing: Using the power of big data and AI, the network may build predictive failure models, which are then combined with automated processes that are capable of altering network configurations to avoid failure conditions.
- Self-defending: Behavioral analytics models can be built to identify network element behavior that is abnormal and could indicate a compromised component. An automated process could then sandbox the suspect network element for further analysis and remediation or even roll back to the last known good configuration.
- Self-optimizing: AI recognizes patterns that lead to more efficient compute resources, radio resources, power settings, and adjusts network configuration accordingly.
- Self-configuring: As new network elements are added, they are automatically recognized, provisioned, and configured in the network.
Whether an operator chooses a Microsoft first-party VNF or cloud-native network function (CNF) or chooses to work with the third-party VNF or CNF partners certified on the Azure platform, Azure will ensure the underlying cloud platform provides the necessary orchestration, management, and exposure capabilities to ensure resiliency, manage performance, and automate execution needed to support core network workloads.
Our work
Microsoft’s level of commitment to supporting the migration of operators to the cloud cannot be understated. The research work cited here represents only a couple of examples of the many projects we continue to explore and which will continue to inform our roadmap moving forward. In the end, this body of knowledge leads the direction we take to support operators in order to make migration to the cloud as smooth as possible. Microsoft knows that when it comes to reliability, speed, and consistency within hyperscale public cloud deployment, there is no one better suited to support operators.
Learn more
To learn more about our vision and strategy, take a look at our Azure for Operators: A cloud for network operators ebook and Azure for Operators infographic.





