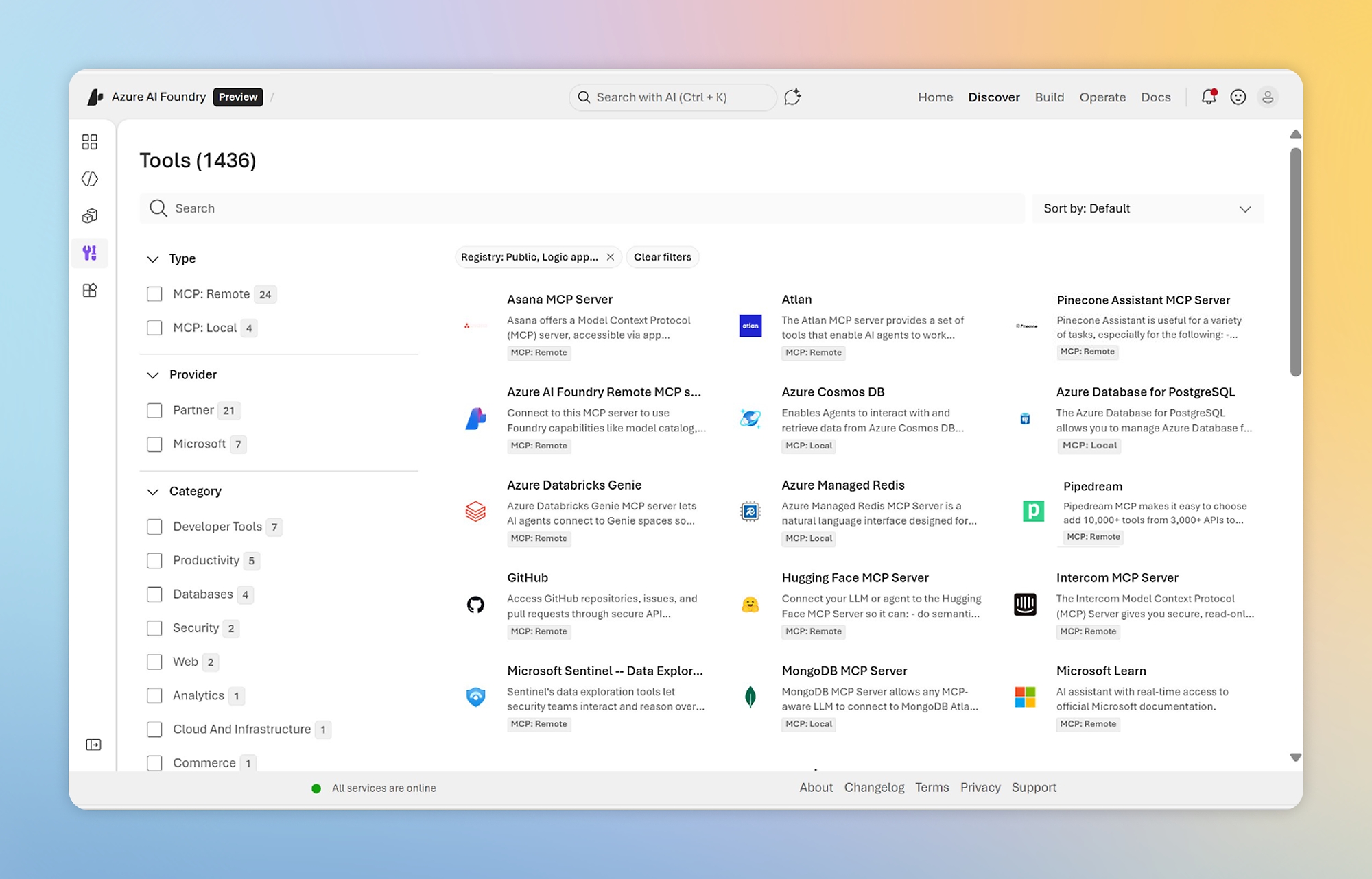
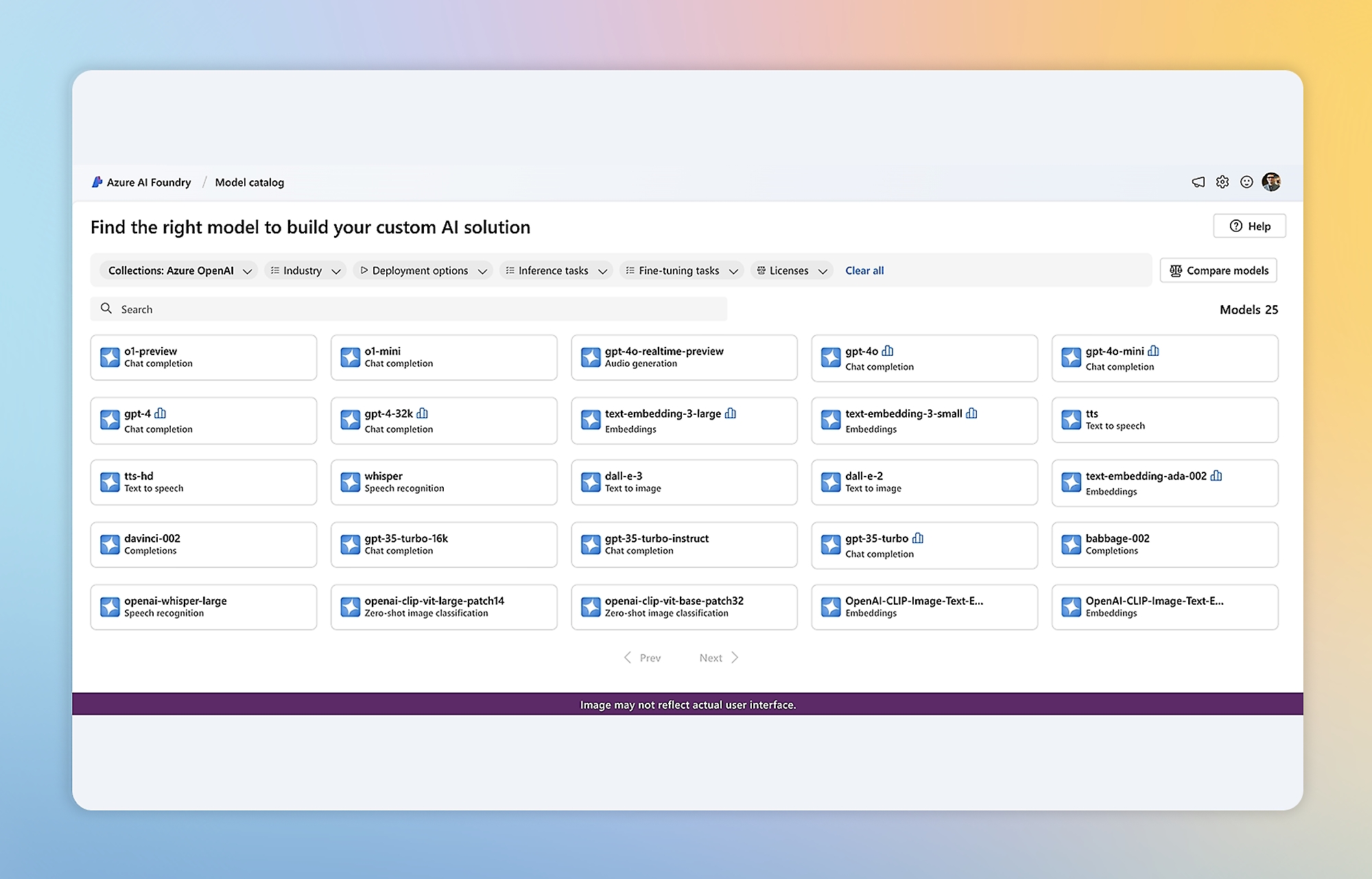
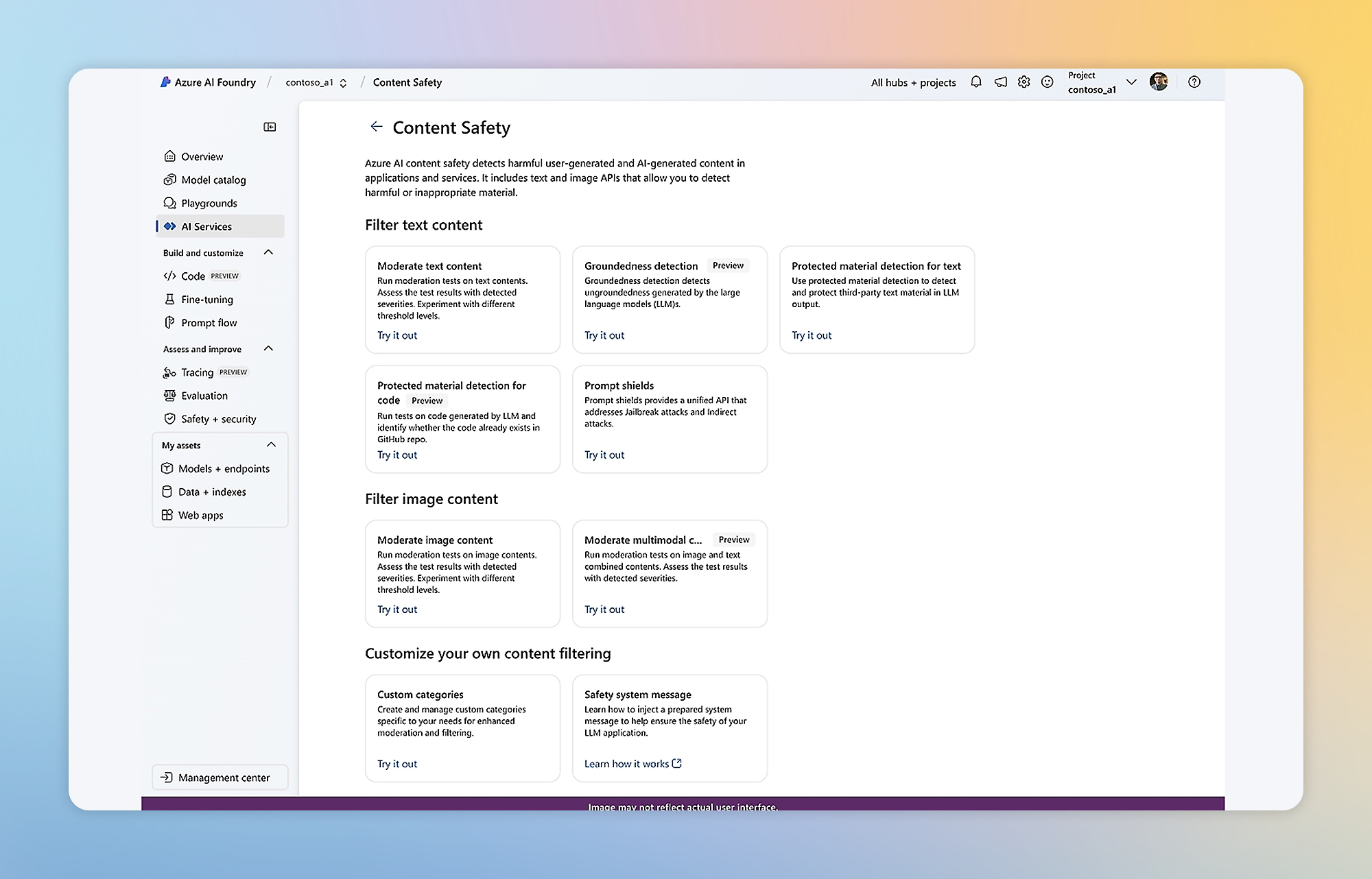
Foundry Tools
Build cutting-edge, market-ready AI applications with customizable tools, APIs, and models.



Full-time equivalent engineers dedicated to security initiatives at Microsoft.
Partners with specialized security expertise.
Compliance certifications, including over 50 specific to global regions and countries.