
The health industry is embracing the power of big data, cloud computing, and clinical analytics, harnessing data to deliver insights that can improve care and efficiency. Still, unstructured text remains a challenge—made even more complex by barriers of language. Doctors’ notes and other unstructured text are often left unreferenced, are hard to parse and learn from, and are difficult to extract insights from, which leads to missed opportunities for diagnosis and better care.
Microsoft recognizes the need to enable healthcare organizations worldwide to gather insights from this data—for better, faster, and more personalized care, and to improve health equity. With Text Analytics for Health, a part of Azure Cognitive Services, healthcare organizations around the world can now extract meaningful insights from unstructured text in seven languages and process it in a way that enables clinical decision support like never before. Moving beyond English, Text Analytics for Health has now released six additional languages in preview—Spanish, French, German, Italian, Portuguese, and Hebrew—making this groundbreaking technology that helps extract insights from multilingual unstructured clinical notes accessible to more health organizations globally. This marks the first of its kind Natural Language Processing (NLP) service that holistically supports analysis of unstructured biomedical data in multiple languages and was developed with a federated learning approach. Most health technology is limited to the English language, making it inaccessible to millions of people and countries where English is not the primary language. Releasing NLP technology in multiple languages is a huge step forward in bridging the gaps in health equity created by language barriers and ensuring that access and quality of health care is not determined by one’s ability to speak and understand English.
Text Analytics for Health uses powerful NLP to detect and identify medical terms in text, classify them and associate them with standard clinical coding systems, as well as infer semantic relationships and assertions in the data, enabling deeper contextual understanding. This opens a world of possibilities for providers, payors, life sciences, and pharmaceutical companies, allowing them to unify data points from unstructured text with structured data, and enabling them to surface key insights, identify risks, automate form-filling, or match clinical trials to patients for better sourcing of candidates—based on comprehensive data including unstructured clinical text.

Training the NLP model for different languages
One of the challenges for an NLP service comes in moving past English—in aiming to analyze text from different languages. This is what Microsoft’s team aimed to do—the goal was to empower all health organizations, no matter the language their text is in. The unique challenges come from the need to train AI models for multiple languages, as well as adjust to country-specific needs. Syntax is different between languages, especially when it comes to non-Latin languages. Languages have different semantics and boundaries, especially those with rich morphology or compound words. Vocabularies are different, jargon is country-specific, and even coding systems differ by country. Words are often borrowed from other languages, leading to text that contains a mixture of multiple languages. Written text is a mixture of colloquialisms, local medical terms, and shorthand that is country-specific. Training models to understand these differences and then evaluating those models required significant amounts of clinical data and working with subject matter experts in different languages.
Leumit Health Services, one of the four national health funds in Israel, worked closely with Microsoft’s R&D team to train the TA4H model for the Hebrew language. Israel has a unique and robust healthcare system where every individual’s records are stored in electronic medical records (EMR) and all citizen residents are required to join one of the four designated HMOs as per law. The health data available is rich, diverse, and provides a great starting point for research and analysis.
Leumit Health Services had over 130 million patient records in their EMR that could be used for training the Text Analytics for Health multilingual model for Hebrew. The challenge was—how to allow Microsoft access to de-identified data for training purposes in a manner that protected the privacy and security of the customer’s health information. The answer was in a Federated Learning approach—meaning data never left Leumit’s trust boundary and Microsoft was never exposed to patient’s health information. Leumit created a separate subscription in Azure with strict access permissions where Microsoft installed its federated learning infrastructure and tools. Leumit then put in de-identified data needed for the research and Microsoft developers triggered the model training in a federated learning setup on that de-identified data—all the while, this data never left their subscription, and the developers were never able to see any identifying details of the data.
Leumit then became one of the first customers to test the Text Analytics for Health model for clinical Hebrew, which is challenging since it often includes Hebrew and English words in the same sentence. The use case was trying to see if the Text Analytics for Health model could analyze free text from medical visits to identify predictors of strokes in patients. Preliminary results are very encouraging and positive—showing the model has ability to parse through both the Hebrew and English clinical statements and analyze them in a way that could help identify various potential indicators of stroke. This could help care providers set up early warning mechanisms and provide more personalized care for a variety of acute conditions.
Using Microsoft’s Hebrew NLP, we will be able to analyze our 20 years of EMR data and patient-to-doctor messages to develop tools that will save physicians time and will reduce their burnout in a post-Covid-19 world – Izhar Laufer, Head of Leumit Start.
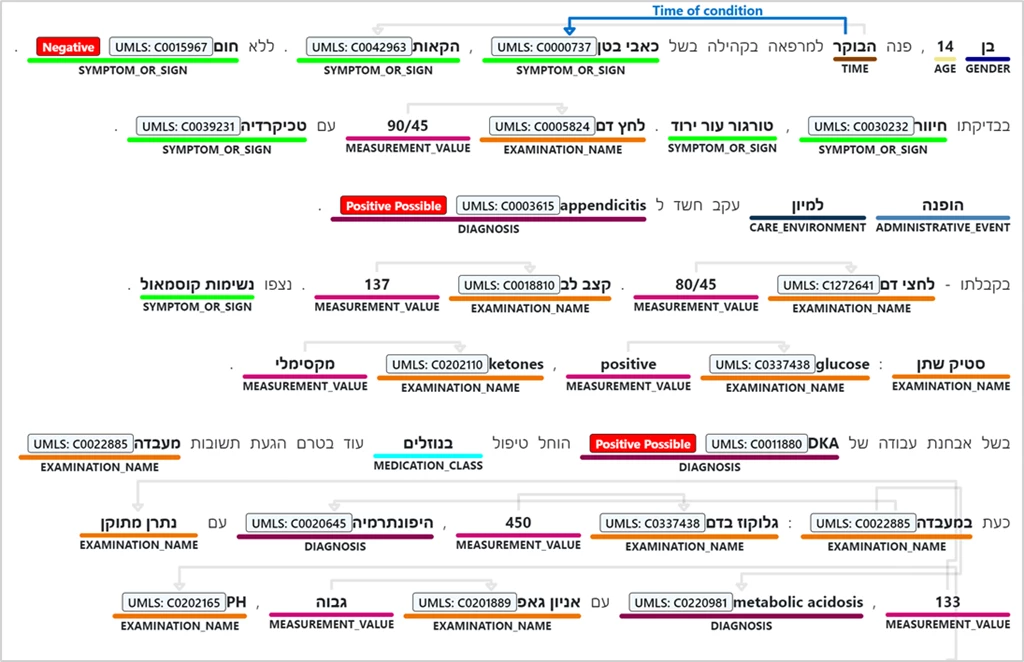
Figure 1: Analysis of Hebrew unstructured biomedical text using Text Analytics for Health

Figure 2: Analysis of Hebrew unstructured biomedical text using Text Analytics for Health
Analyzing unstructured text for Real-World Data
The challenge of unstructured data is even greater in the research world with the use of Real-World Data (RWD). In Brazil, amongst other places, the lack of a standard for interoperability and data collection leads to a lot of unstructured data—field reports, doctors’ notes, and even laboratory exam results. This slows down the process of research and analysis for providers such as Grupo Oncoclínicas. Founded in 2010, Grupo Oncoclínicas is the largest oncology treatment provider in the private sector in Brazil, with 129 units in 33 cities—including clinics, genomics and pathology laboratories, and integrated cancer treatment centers.
With the help of Dataside, a Microsoft partner in Brazil, OncoClinicas is using Microsoft’s Text Analytics for Health to extract data from non-structured fields like medical notes, anatomic pathology, and genomic and imaging reports like MRIs. This data is then used for various use cases such as clinical trial feasibility, a better understanding of the scenarios for pharmacoeconomics, and gaining a deeper understanding of group epidemiology and outcomes of interest.

Figure 3: Analysis of Portuguese unstructured biomedical text using Text Analytics for Health
“Text Analytics for Health was a turning point for Grupo Oncoclínicas to scale our processes and to structure our clinical notes, exam reports and field analysis, which previously only depended on manual curation. Having a solution that works in Portuguese is key—most global solutions tend to only cater to English, thereby neglecting other languages. Accuracy in the native Portuguese allowed us to maintain a high level of accuracy while analyzing the unstructured text.”—Marcio Guimaraes Souza, Head of Data and AI at Groupo OncoClinicas.
Analysis and structuring to Fast Healthcare Interoperability Resources (FHIR®)
The Italian Vita-Salute San Raffaele University and IRCCS San Raffaele Hospital are building the healthcare of the future by leveraging Microsoft’s Artificial Intelligence(AI) services. With Text Analytics for Health, the hospitals can classify, standardize, and analyze the enormous amount of clinical data available at the hospital in order to create an innovative digital platform for data management. Using this platform, the hospital’s physicians can gain important clinical insights about their patients and provide more personalized care. One of the use cases that is currently being developed using this data platform is for allowing the selection of patients eligible for immunotherapy for non-small cell lung cancer. Medical staff can leverage the analysis of AI solutions to increase the success rate of therapy by matching the relevant treatment to the most eligible patients.
“Text Analytics for Health has played a key role in analyzing the enormous amount of unstructured clinical data that we have at the hospital. We are also using the FHIR structuring capability, which allows greater interoperability with other hospital systems. Having Text Analytics for Health available in Italian now allows us to expand our capabilities even further to offer our patients the best possible care.”—Professor Carlo Tacchetti, Professor of Human Anatomy, Vita-Salute San Raffaele University, and coordinator of the project.

Figure 4: Analysis of Italian unstructured biomedical text using Text Analytics for Health
Do more with your data with Microsoft Cloud for Healthcare
With Text Analytics for Health, health organizations can transform their patient care, discover new insights and harness the power of machine learning and AI by leveraging unstructured text. Microsoft is committed to delivering technology that enables your data for the future of healthcare innovation with new features in the Microsoft Cloud for Healthcare.
We look forward to being your partner as you build the future of health.
• Learn more about Text Analytics for Health.
• Learn more about Microsoft Cloud for Healthcare.
®FHIR is a registered trademark of Health Level Seven International, registered in the U.S. Trademark Office, and is used with their permission.





