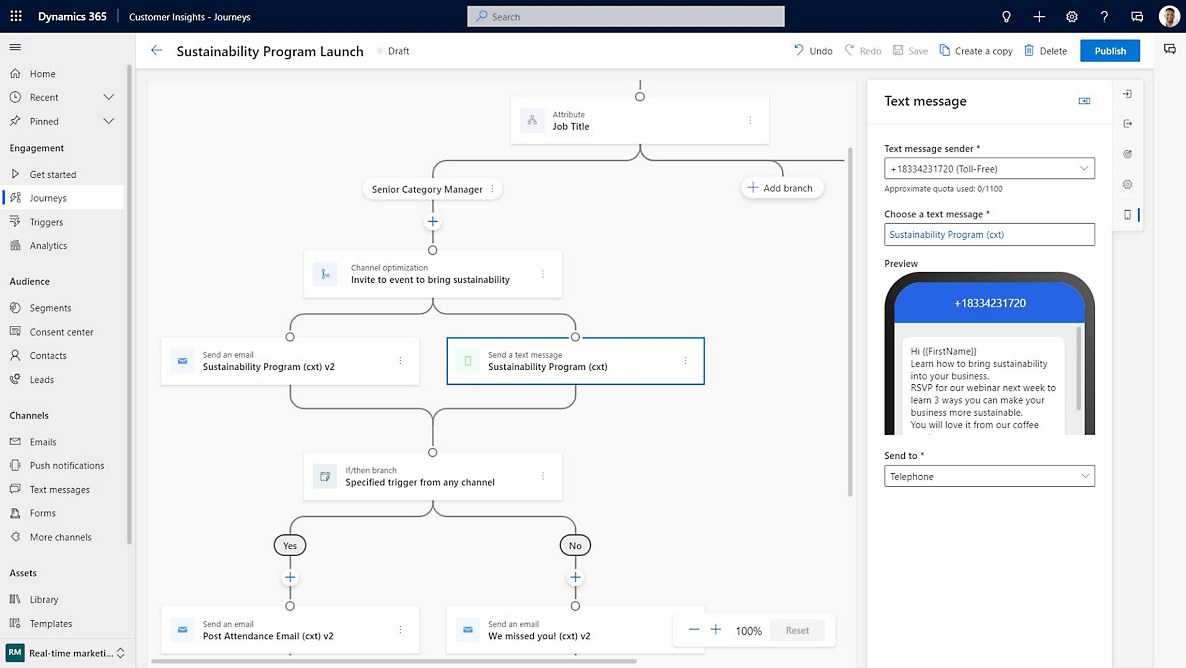
GitHub Copilot er en kodningsassistent med kunstig intelligens, der hjælper udviklere med at skrive kode hurtigere med mindre indsats. Den giver kontekstafhængig hjælp og tilbyder kodningsforslag som udviklertype, hvilket kan være alt lige fra en simpel linjefuldførelse til en helt ny kodeblok. Dette hjælper udviklere med at fokusere mere på problemløsning, samarbejde og innovation. Det er det mest udbredte udviklerværktøj med kunstig intelligens, der er integreret med førende editors og indbygget i GitHub, hvilket forbedrer jobtilfredsheden og produktiviteten.