AI + Machine Learning, Analytics, Azure AI, Azure AI Content Safety, Azure AI Search, Azure AI Studio, Azure Machine Learning, Azure OpenAI Service, Best practices, Management and Governance, Thought leadership
Achieve generative AI operational excellence with the LLMOps maturity model
Posted on
7 min read
This is the fourth blog in our series on LLMOps for business leaders. Read the first, second, and third articles to learn more about LLMOps on Azure AI.
In our LLMOps blog series, we’ve explored various dimensions of Large Language Models (LLMs) and their responsible use in AI operations. Elevating our discussion, we now introduce the LLMOps maturity model, a vital compass for business leaders. This model is not just a roadmap from foundational LLM utilization to mastery in deployment and operational management; it’s a strategic guide that underscores why understanding and implementing this model is essential for navigating the ever-evolving landscape of AI. Take, for instance, Siemens’ use of Microsoft Azure AI Studio and prompt flow to streamline LLM workflows to help support their industry leading product lifecycle management (PLM) solution Teamcenter and connect people who find problems with those who can fix them. This real-world application exemplifies how the LLMOps maturity model facilitates the transition from theoretical AI potential to practical, impactful deployment in a complex industry setting.
Exploring application maturity and operational maturity in Azure
The LLMOps maturity model presents a multifaceted framework that effectively captures two critical aspects of working with LLMs: the sophistication in application development and the maturity of operational processes.
Application maturity: This dimension centers on the advancement of LLM techniques within an application. In the initial stages, the emphasis is placed on exploring the broad LLM capabilities, often progressing towards more intricate techniques like fine-tuning and Retrieval Augmented Generation (RAG) to meet specific needs.
Operational maturity: Regardless of the complexity of LLM techniques employed, operational maturity is essential for scaling applications. This includes systematic deployment, robust monitoring, and maintenance strategies. The focus here is on ensuring that the LLM applications are reliable, scalable, and maintainable, irrespective of their level of sophistication.
This maturity model is designed to reflect the dynamic and ever-evolving landscape of LLM technology, which requires a balance between flexibility and a methodical approach. This balance is crucial in navigating the continuous advancements and exploratory nature of the field. The model outlines various levels, each with its own rationale and strategy for progression, providing a clear roadmap for organizations to enhance their LLM capabilities.
LLMOps maturity model
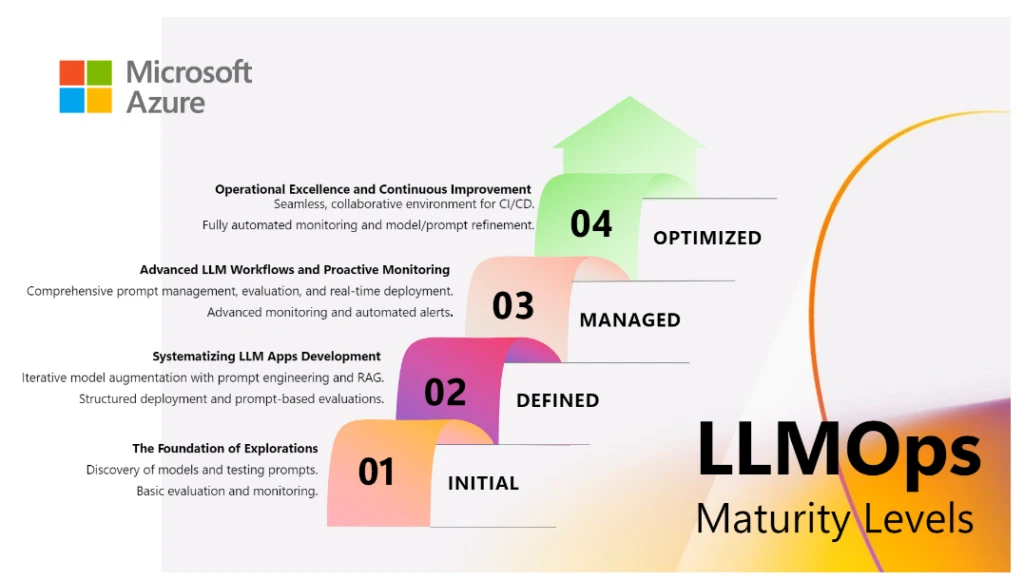
Level One—Initial: The foundation of exploration
At this foundational stage, organizations embark on a journey of discovery and foundational understanding. The focus is predominantly on exploring the capabilities of pre-built LLMs, such as those offered by Microsoft Azure OpenAI Service APIs or Models as a Service (MaaS) through inference APIs. This phase typically involves basic coding skills for interacting with these APIs, gaining insights into their functionalities, and experimenting with simple prompts. Characterized by manual processes and isolated experiments, this level doesn’t yet prioritize comprehensive evaluations, monitoring, or advanced deployment strategies. Instead, the primary objective is to understand the potential and limitations of LLMs through hands-on experimentation, which is crucial in understanding how these models can be applied to real-world scenarios.
At companies like Contoso1, developers are encouraged to experiment with a variety of models, including GPT-4 from Azure OpenAI Service and LLama 2 from Meta AI. Accessing these models through the Azure AI model catalog allows them to determine which models are most effective for their specific datasets. This stage is pivotal in setting the groundwork for more advanced applications and operational strategies in the LLMOps journey.
Level Two—Defined: Systematizing LLM app development
As organizations become more proficient with LLMs, they start adopting a systematic method in their operations. This level introduces structured development practices, focusing on prompt design and the effective use of different types of prompts, such as those found in the meta prompt templates in Azure AI Studio. At this level, developers start to understand the impact of different prompts on the outputs of LLMs and the importance of responsible AI in generated content.
An important tool that comes into play here is Azure AI prompt flow. It helps streamline the entire development cycle of AI applications powered by LLMs, providing a comprehensive solution that simplifies the process of prototyping, experimenting, iterating, and deploying AI applications. At this point, developers start focusing on responsibly evaluating and monitoring their LLM flows. Prompt flow offers a comprehensive evaluation experience, allowing developers to assess applications on various metrics, including accuracy and responsible AI metrics like groundedness. Additionally, LLMs are integrated with RAG techniques to pull information from organizational data, allowing for tailored LLM solutions that maintain data relevance and optimize costs.
For instance, at Contoso, AI developers are now utilizing Azure AI Search to create indexes in vector databases. These indexes are then incorporated into prompts to provide more contextual, grounded and relevant responses using RAG with prompt flow. This stage represents a shift from basic exploration to a more focused experimentation, aimed at understanding the practical use of LLMs in solving specific challenges.
Level Three—Managed: Advanced LLM workflows and proactive monitoring
During this stage, the focus shifts to refined prompt engineering, where developers work on creating more complex prompts and integrating them effectively into applications. This involves a deeper understanding of how different prompts influence LLM behavior and outputs, leading to more tailored and effective AI solutions.
At this level, developers harness prompt flow’s enhanced features, such as plugins and function callings, for creating sophisticated flows involving multiple LLMs. They can also manage various versions of prompts, code, configurations, and environments via code repositories, with the capability to track changes and rollback to previous versions. The iterative evaluation capabilities of prompt flow become essential for refining LLM flows, by conducting batch runs, employing evaluation metrics like relevance, groundedness, and similarity. This allows them to construct and compare various metaprompt variations, determining which ones yield higher quality outputs that align with their business objectives and responsible AI guidelines.
In addition, this stage introduces a more systematic approach to flow deployment. Organizations start implementing automated deployment pipelines, incorporating practices such as continuous integration/continuous deployment (CI/CD). This automation enhances the efficiency and reliability of deploying LLM applications, marking a move towards more mature operational practices.
Monitoring and maintenance also evolve during this stage. Developers actively track various metrics to ensure robust and responsible operations. These include quality metrics like groundedness and similarity, as well as operational metrics such as latency, error rate, and token consumption, alongside content safety measures.
At this stage in Contoso, developers concentrate on creating diverse prompt variations in Azure AI prompt flow, refining them for enhanced accuracy and relevance. They utilize advanced metrics like Question and Answering (QnA) Groundedness and QnA Relevance during batch runs to constantly assess the quality of their LLM flows. After assessing these flows, they use the prompt flow SDK and CLI for packaging and automating deployment, integrating seamlessly with CI/CD processes. Additionally, Contoso improves its use of Azure AI Search, employing more sophisticated RAG techniques to develop more complex and efficient indexes in their vector databases. This results in LLM applications that are not only quicker in response and more contextually informed, but also more cost-effective, reducing operational expenses while enhancing performance.
Level Four—Optimized: Operational excellence and continuous improvement
At the pinnacle of the LLMOps maturity model, organizations reach a stage where operational excellence and continuous improvement are paramount. This phase features highly sophisticated deployment processes, underscored by relentless monitoring and iterative enhancement. Advanced monitoring solutions offer deep insights into LLM applications, fostering a dynamic strategy for continuous model and process improvement.
At this advanced stage, Contoso’s developers engage in complex prompt engineering and model optimization. Utilizing Azure AI’s comprehensive toolkit, they build reliable and highly efficient LLM applications. They fine-tune models like GPT-4, Llama 2, and Falcon for specific requirements and set up intricate RAG patterns, enhancing query understanding and retrieval, thus making LLM outputs more logical and relevant. They continuously perform large-scale evaluations with sophisticated metrics assessing quality, cost, and latency, ensuring thorough evaluation of LLM applications. Developers can even use an LLM-powered simulator to generate synthetic data, such as conversational datasets, to evaluate and improve the accuracy and groundedness. These evaluations, conducted at various stages, embed a culture of continuous enhancement.
For monitoring and maintenance, Contoso adopts comprehensive strategies incorporating predictive analytics, detailed query and response logging, and tracing. These strategies are aimed at improving prompts, RAG implementations, and fine-tuning. They implement A/B testing for updates and automated alerts to identify potential drifts, biases, and quality issues, aligning their LLM applications with current industry standards and ethical norms.
The deployment process at this stage is streamlined and efficient. Contoso manages the entire lifecycle of LLMOps applications, encompassing versioning and auto-approval processes based on predefined criteria. They consistently apply advanced CI/CD practices with robust rollback capabilities, ensuring seamless updates to their LLM applications.
At this phase, Contoso stands as a model of LLMOps maturity, showcasing not only operational excellence but also a steadfast dedication to continuous innovation and enhancement in the LLM domain.
Identify where you are in the journey
Each level of the LLMOps maturity model represents a strategic step in the journey toward production-level LLM applications. The progression from basic understanding to sophisticated integration and optimization encapsulates the dynamic nature of the field. It acknowledges the need for continuous learning and adaptation, ensuring that organizations can harness the transformative power of LLMs effectively and sustainably.
The LLMOps maturity model offers a structured pathway for organizations to navigate the complexities of implementing and scaling LLM applications. By understanding the distinction between application sophistication and operational maturity, organizations can make more informed decisions about how to progress through the levels of the model. The introduction of Azure AI Studio that encapsulated prompt flow, model catalog, and the Azure AI Search integration into this framework underscores the importance of both cutting-edge technology and robust operational strategies in achieving success with LLMs.
Learn more
- Take the 45-minute Get Started with prompt flow to develop LLM apps module on Microsoft Learn
- Leverage the solution template to put LLMOps into practice
Explore Azure AI Studio
Build, evaluate, and deploy your AI solutions all within one space
- Contoso is a fictional but representative global organization building generative AI applications.