

Data Lake
En grænseløs datasø danner basis for intelligente handlinger.
- Opbevar og analysér filer i petabyte-størrelsen og billioner af objekter
- Du kan let fejlfinde og optimere dine big data-programmer
- Start på få sekunder, skaler øjeblikkeligt, og betal pr. job
- Skab omfattende parallelle programmer på en enkel måde
- Sikkerhed, overvågning og support i virksomhedsklassen
- Udviklet på YARN, designet til skyen
Azure Data Lake indeholder alle de muligheder, som udviklere, dataloger og analytikere skal bruge til at lagre data uanset størrelse, form og hastighed samt behandling og analyse af alle slags på tværs af platforme og computersprog. Den fjerner kompleksiteten ved at overføre og lagre alle dine data og gør det samtidig hurtigere at komme i gang med batchanalyse, streaminganalyse og interaktiv analyse. Azure Data Lake arbejder sammen med eksisterende it-investeringer i identitet, ledelse og sikkerhed for at forenkle dataadministration og ledelse. Den integreres perfekt i driftslagre og data warehouses, så du kan udbygge dine aktuelle dataprogrammer. Vi har trukket på vores erfaringer fra samarbejdet med virksomhedskunder og driften af nogle af verdens største behandlinger og analyser for Microsoft-virksomheder som Office 365, Xbox Live, Azure, Windows, Bing og Skype. Azure Data Lake løser mange af de udfordringer i forbindelse med produktivitet og skalerbarhed, der forhindrer dig i at maksimere værdien af dine dataaktiver, med en tjeneste, der er klar til at opfylde dine aktuelle og fremtidige forretningsbehov.
Azure Data Lake indeholder alle de muligheder, som udviklere, dataloger og analytikere skal bruge til at lagre data uanset størrelse, form og hastighed samt behandling og analyse af alle slags på tværs af platforme og computersprog. Den fjerner kompleksiteten ved at overføre og lagre alle dine data og gør det samtidig hurtigere at komme i gang med batchanalyse, streaminganalyse og interaktiv analyse. Azure Data Lake arbejder sammen med eksisterende it-investeringer i identitet, ledelse og sikkerhed for at forenkle dataadministration og ledelse. Den integreres perfekt i driftslagre og data warehouses, så du kan udbygge dine aktuelle dataprogrammer. Vi har trukket på vores erfaringer fra samarbejdet med virksomhedskunder og driften af nogle af verdens største behandlinger og analyser for Microsoft-virksomheder som Office 365, Xbox Live, Azure, Windows, Bing og Skype. Azure Data Lake løser mange af de udfordringer i forbindelse med produktivitet og skalerbarhed, der forhindrer dig i at maksimere værdien af dine dataaktiver, med en tjeneste, der er klar til at opfylde dine aktuelle og fremtidige forretningsbehov.
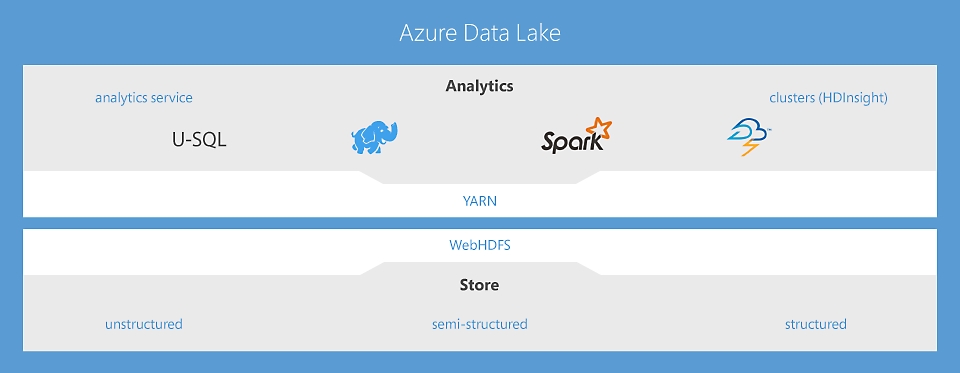
Data Lake Analytics – en analysejobtjeneste, der fremmer intelligente handlinger
Den første cloudanalysetjeneste hvor du let kan udvikle og køre omfattende parallel datatransformation og behandlingsprogrammer i U-SQL, R, Python og .NET over petabytes af data. Der er ingen infrastruktur, der skal administreres, så du kan behandle data efter behov, skalere øjeblikkeligt og kun betale pr. job. Få mere at vide

HDInsight – cloudbaseret Apache Spark- og Hadoop®-tjeneste til virksomheden
HDInsight er det eneste fuldt administrerede Cloud Hadoop-tilbud, der har optimerede analyseklynger med åben kildekode til Spark, Hive, Map Reduce, HBase, Storm, Kafka og R-Server, og det understøttes af en SLA på 99,9 %. Hver af disse Big Data-teknologier samt ISV-programmer kan let udrulles som administrerede klynger med professionel sikkerhed og overvågning. Få mere at vide

Data Lake Store – en datasø uden grænser, der driver analyser af Big Data
Den første datasø i cloudmiljøet til virksomheder, der er sikker, yderst skalerbar og opbygget efter den åbne HDFS-standard. Der er ingen begrænsninger af datastørrelsen, og da du har mulighed for at køre omfattende parallelle analyser, kan du nu få adgang til i dine ustrukturerede, delvist strukturerede og strukturerede data. Få mere at vide

Du kan let udvikle, fejlfinde og optimere big data-programmer
Det kan være svært at finde de rigtige værktøjer til at designe og indstille dine big data-forespørgsler. Det er nemt med Data Lake og dens dybe integration med Visual Studio, Eclipse og IntelliJ, så du kan bruge velkendte værktøjer til at køre, fejlfinde og justere din kode. Visualiseringer af dine U-SQL-, Apache Spark-, Apache Hive- og Apache Storm-jobs lader dig se, hvor meget af din kode, der kører efter skala, og finde flaskehalse for ydelse samt optimeringer af omkostninger, så du nemmere kan tilpasse dine forespørgsler. Vores udførelsesmiljø analyserer aktivt dine programmer, mens de kører, og kommer med forslag til forbedring af ydeevnen og reduktion af omkostningerne. Dataingeniører, DBA'er og dataarkitekter kan bruge eksisterende kompetencer, f.eks. SQL, Apache Hadoop, Apache Spark, R, Python, Java og .NET, og være produktive fra dag ét.

Integreres uden problemer med dine eksisterende it-investeringer
En af de største udfordringer ved big data er integrationen med eksisterende it-investeringer. Data Lake er en vigtig del af Cortana Intelligence, hvilket betyder, at det arbejder sammen med Azure Synapse Analytics, Power BI og Data Factory på en komplet platform i cloudmiljøet til big data og avanceret analyse, der hjælper dig med alt fra dataforberedelse til at udføre interaktive analyser af datasæt i stor skala. Data Lake Analytics giver dig magten til at reagere på alle dine data med optimeret datavirtualisering af din relationskilder, f.eks. Azure SQL Server på virtuelle maskiner, Azure SQL Database og Azure Synapse Analytics. Forespørgsler optimeres automatisk ved at flytte behandlingen tættere på kildedataene, uden flytning af data, og derved maksimeres ydeevnen, og ventetiden minimeres. Og endelig, da Data Lake er i Azure, kan du oprette forbindelse til alle data, der er genereret af programmer eller indtaget af enheder i IoT-scenarier (Internet of Things).
Opbevar og analysér filer i petabyte-størrelsen og billioner af objekter
Data Lake blev udviklet fra bunden med henblik på skalering og ydelse i cloudmiljøet. Med Azure Data Lake Store kan din organisation analysere alle sine data på et enkelt sted og uden kunstige begrænsninger. Din Data Lake Store kan lagre billioner af filer, hvor en enkelt fil kan være større end en petabyte, hvilket er 200 gange større end i andre lagerløsninger i cloudmiljøet. Det betyder, at du ikke behøver at omskrive koden, efterhånden som du øger eller reducerer mængden af lagrede data eller mængden af beregningsressourcer, du har brugt. Dermed kan du fokusere fuldt ud på din forretningslogik og ikke på, hvordan du skal behandle og lagre store datasæt. Data Lake fjerner også den kompleksitet, der som regel er forbundet med big data i cloudmiljøet, og kan således imødekomme dine aktuelle og fremtidige virksomhedsbehov.

Økonomisk og omkostningseffektiv
Data Lake er en rentabel løsning til kørsel af big data-arbejdsmængder. Når du behandler data, kan du vælge mellem klynger on-demand eller en model, hvor du betaler pr. job. Der kræves ingen hardware, licenser eller tjenestespecifikke supportaftaler, uanset hvad du vælger. Systemet skalerer op eller ned i takt med dine virksomhedsbehov, så du aldrig betaler for mere, end du har brug for. Du kan også uafhængigt skalere lager og udføre beregninger, hvilket giver dig en større økonomisk fleksibilitet i forhold til traditionelle big data-løsninger. Endelig reducerer det behovet for at ansætte et specialteam, hvilket ellers ofte kræves ved drift af en big data-infrastruktur. Data Lake minimerer dine omkostninger og maksimerer samtidig dit dataafkast. I en undersøgelse, der er foretaget for nylig, viste det sig, at HDInsight giver 63 % lavere samlede ejeromkostninger end en udrulning af Hadoop i det lokale miljø over fem år.

Sikkerhed, overvågning og support i virksomhedsklassen
Data Lake er fuldt styret og understøttes af Microsoft, og den suppleres af en professionel SLA og support. Kundesupport 24/7 betyder, at du kan kontakte os med de udfordringer, du står overfor med hele din big data-løsning. Vores team overvåger din installation, så du ikke selv behøver at gøre det, og vi garanterer, at den kører konstant. Data Lake beskytter dine dataaktiver og udvider på en let måde sikkerheden i det lokale miljø og styringen af cloudmiljøet. Data krypteres altid. Når de flyttes, sker det ved hjælp af SSL, og når de er i ro, sker det ved hjælp af en tjeneste eller brugeradministrerede HSM-baserede nøgler i Azure Key Vault. Funktioner som enkeltlogon (SSO), multifaktorgodkendelse og problemfri administration af millioner af identiteter er indbygget via Azure Active Directory. Du kan godkende brugere og grupper med detaljerede POSIX-baserede ACL'er til alle data i lageret, så der er mulighed for rollebaseret adgangskontrol. Endeligt kan du opfylde behovene for overholdelse af sikkerhedsmæssige og lovmæssige krav ved at overvåge hver adgang til og konfigurationsændring af systemet.
Skab Data Lake-løsninger ved hjælp af disse effektive løsninger

HDInsight
Klargør Hadoop-, Spark-, R Server-, HBase- og Storm-klynger i cloudmiljøet.

Data Lake Analytics
Distribueret analysetjeneste til nem håndtering af big data.
Azure Data Lake Storage
Skalerbar og sikker datasø til højtydende analyse.