
Azure AI Services
Créez des applications d’intelligence artificielle de pointe prêtes à la commercialisation avec des API et des modèles prêts à l’emploi et personnalisables
Déployez rapidement une IA approuvée avec un portefeuille de services IA

Vue d’ensemble
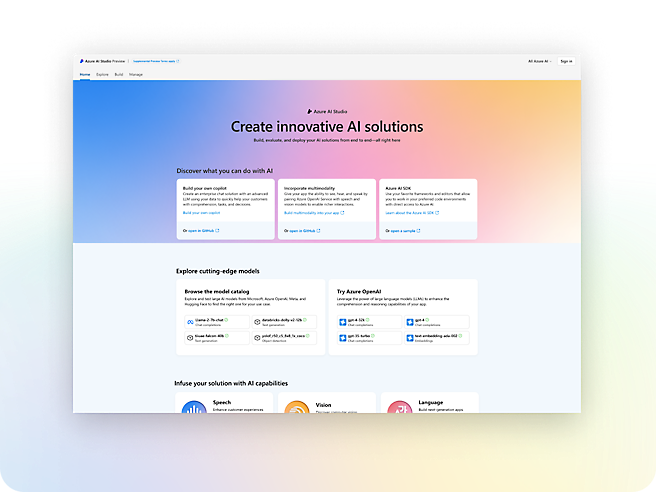
Créez des applications intelligentes avec une IA de pointe
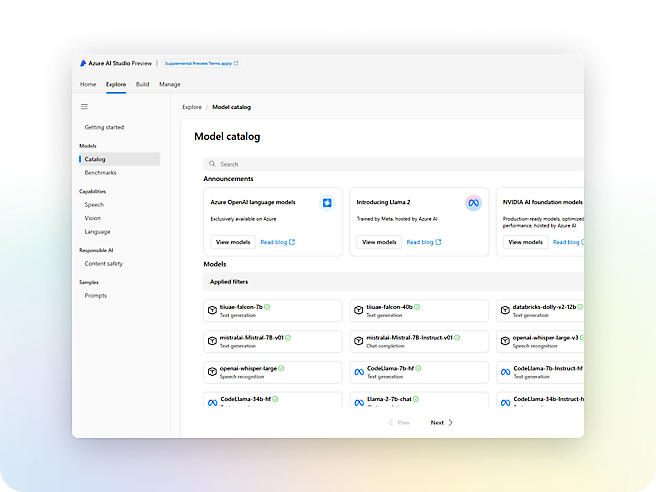
- Intégrez rapidement l’IA générative dans les charges de travail de production à l’aide de studios, de kits de développement logiciel (SDK) et d’API.Gagnez un avantage concurrentiel en créant des applications d’IA basées sur des modèles de fondation, notamment ceux d’OpenAI, de Meta et de Microsoft.Détectez et atténuez les utilisations dangereuses avec une IA responsable intégrée, une sécurité Azure de classe Entreprise et des outils d’intelligence artificielle responsables.

Services
Créez avec des API et des modèles personnalisables
Azure OpenAI Service
Créez vos propres applications de copilote et d’IA générative avec des modèles de langage et de vision de pointe.
Recherche Azure AI
Récupérez les données les plus pertinentes à l’aide d’un mot clé, d’un vecteur et d’une recherche hybride.
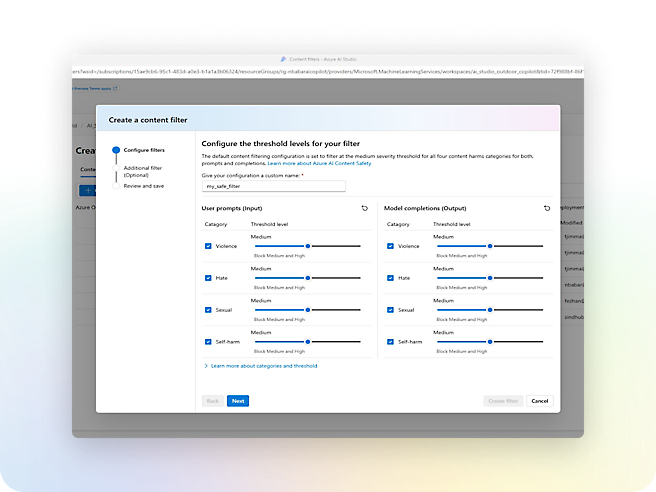
Azure AI Sécurité du Contenu
Analysez le texte et les images pour détecter le contenu choquant ou inapproprié.
Azure AI Traducteur
Traduisez des documents et du texte en temps réel dans plus de 100 langues.
Azure AI Speech
Utilisez des services IA de pointe tels que la reconnaissance vocale, la synthèse vocale, la traduction vocale et la reconnaissance de l'orateur.
Azure AI Vision
Lisez du texte, analysez des images et détectez des visages avec la reconnaissance optique de caractères (OCR) et le machine learning.
Azure AI Language
Créez des interfaces de conversation, synthétisez des documents et analysez du texte à l’aide de fonctionnalités prédéfinies basées sur l’IA.
Azure AI Intelligence documentaire
Appliquez le Machine Learning avancé pour extraire du texte, des paires clé-valeur, des tables et des structures à partir de documents.
Sécurité et conformité intégrées
Microsoft s’est engagé à investir 20 milliards de dollars USD dans la cybersécurité sur 5 ans.
Nous employons plus de 8 500 experts en sécurité et en renseignement sur les menaces dans 77 pays.
Azure dispose de l’un des plus grands portefeuilles de certification de conformité dans le secteur.

Tarification
Tarification Azure AI Services
Explorez des tarifs flexibles basés sur la consommation pour la famille de services IA. Chaque service propose différentes options de tarification pour répondre à vos besoins.

Trouvez votre solution d'IA
Découvrez Azure AI, portefeuille de services d’intelligence artificielle conçus pour les développeurs et les scientifiques des données.
Témoignages clients
Découvrez comment nos clients utilisent Azure






RESSOURCES
En savoir plus sur les Azure AI services






INSCRIPTION AU COMPTE
Démarrage avec un compte gratuit
Commencez par un crédit Azure de 200 USD.

INSCRIPTION AU COMPTE
Démarrer avec la tarification du paiement à l’utilisation
Pas d’engagement initial. Annulation possible à tout moment.