

데이터 레이크
지능형 작업을 위한 무제한 데이터 레이크.
- 페타바이트급 파일과 방대한 규모의 개체를 저장하고 분석
- 빅 데이터 프로그램을 간편하게 디버그하고 최적화
- 수초 내에 시작, 즉시 확장, 각 작업에 사용한 만큼만 비용 지불
- 간단하게 대규모 병렬 프로그램 개발
- 엔터프라이즈급 보안, 감사 및 지원
- 클라우드용으로 설계된 YARN을 기반으로 설계
Azure Data Lake에는 개발자, 데이터 과학자 및 분석가들이 보다 쉽게 다양한 크기, 형태 및 속도의 데이터를 저장하고, 플랫폼 및 언어에 관계없이 모든 유형의 처리 및 분석을 수행할 수 있도록 하는 데 필요한 모든 기능이 포함되어 있습니다. 이 서비스는 배치, 스트리밍 및 대화식 분석을 사용하여 보다 빠르게 작업을 실행하도록 하면서 모든 데이터의 수집 및 저장에 따른 복잡성을 없애 줍니다. Azure Data Lake는 데이터 관리 및 거버넌스의 간소화를 위해 ID, 관리 및 보안에 대한 기존 IT 투자를 활용합니다. 그뿐 아니라 작업 스토리지 및 데이터 웨어하우스와 원활하게 통합되므로 현재의 데이터 애플리케이션을 확장할 수 있습니다. Microsoft는 엔터프라이즈 고객과 함께 작업하며, Office 365, Xbox Live, Azure, Windows, Bing 및 Skype와 같은 Microsoft 비즈니스 분야에서 최대 규모의 처리 및 분석을 실행하던 풍부한 경험을 갖고 있습니다. Azure Data Lake는 현재 및 미래의 비즈니스 요구를 충족하는 데 도움이 되는 다양한 서비스를 토대로 데이터 자산의 가치를 극대화하는 데 걸림돌로 작용하고 있는 많은 생산성 및 확장성 문제를 해결해 줍니다.
Azure Data Lake에는 개발자, 데이터 과학자 및 분석가들이 보다 쉽게 다양한 크기, 형태 및 속도의 데이터를 저장하고, 플랫폼 및 언어에 관계없이 모든 유형의 처리 및 분석을 수행할 수 있도록 하는 데 필요한 모든 기능이 포함되어 있습니다. 이 서비스는 배치, 스트리밍 및 대화식 분석을 사용하여 보다 빠르게 작업을 실행하도록 하면서 모든 데이터의 수집 및 저장에 따른 복잡성을 없애 줍니다. Azure Data Lake는 데이터 관리 및 거버넌스의 간소화를 위해 ID, 관리 및 보안에 대한 기존 IT 투자를 활용합니다. 그뿐 아니라 작업 스토리지 및 데이터 웨어하우스와 원활하게 통합되므로 현재의 데이터 애플리케이션을 확장할 수 있습니다. Microsoft는 엔터프라이즈 고객과 함께 작업하며, Office 365, Xbox Live, Azure, Windows, Bing 및 Skype와 같은 Microsoft 비즈니스 분야에서 최대 규모의 처리 및 분석을 실행하던 풍부한 경험을 갖고 있습니다. Azure Data Lake는 현재 및 미래의 비즈니스 요구를 충족하는 데 도움이 되는 다양한 서비스를 토대로 데이터 자산의 가치를 극대화하는 데 걸림돌로 작용하고 있는 많은 생산성 및 확장성 문제를 해결해 줍니다.
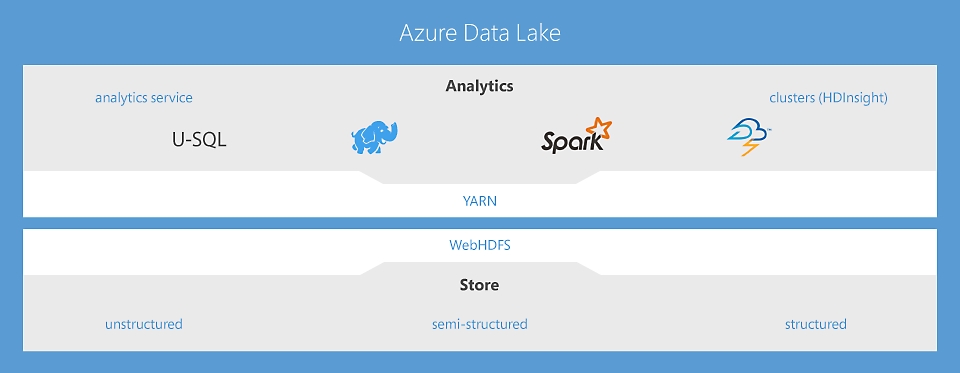
Data Lake Analytics - 지능형 작업을 위한 무제한 분석 작업 서비스
페타바이트급 데이터를 대상으로 대규모 병렬 데이터 변환과 처리 프로그램을 U-SQL, R, Python, .Net에서 손쉽게 개발하고 실행할 수 있는 최초의 클라우드 분석 서비스입니다. 관리할 인프라를 별도로 둘 필요 없이 데이터를 언제든지 처리하고 즉시 확장할 수 있으며 작업별 비용만 지불하면 됩니다. 자세한 정보

HDInsight - 기업을 위한 클라우드 Apache Spark와 Hadoop® 서비스
HDInsight는 유일한 완전 관리형 클라우드 Hadoop 솔루션으로, Spark, Hive, Map Reduce, HBase, Storm, Kafka, R Server에 최적화된 오픈 소스 기반의 분석 클러스터를 제공하고 99.9% SLA를 보장합니다. 이러한 각 빅 데이터 기술과 ISV 애플리케이션은 엔터프라이즈급 보안과 모니터링으로 관리 클러스터 형태로 쉽게 배포 가능합니다. 자세한 정보

Data Lake Store - 빅 데이터 분석을 위한 무제한 데이터 레이크
기업을 위한 최초의 클라우드 Data Lake로, 개방형 HDFS 표준에 따라 구축되어 안전하고 대규모로 확장 가능합니다. 데이터 크기 제한이 없으며 대규모 병렬 분석 실행이 가능하기 때문에 데이터가 비정형 데이터든 반정형 데이터든 정형 데이터든 상관없이 데이터의 가치를 끌어낼 수 있습니다. 자세한 정보

손쉽게 빅 데이터 프로그램 개발, 디버그, 최적화
빅 데이터 쿼리를 설계하고 조정하기 위한 적절한 도구를 찾는 일은 어려울 수 있습니다. Data Lake는 Visual Studio, Eclipse 및 IntelliJ에 쉽게 통합되므로 친숙한 도구로 코드를 실행, 디버그 및 조정할 수 있습니다. U-SQL, Apache Spark, Apache Hive 및 Apache Storm 작업의 시각화를 통해 코드가 실행되는 방식을 전체적으로 확인할 수 있으므로 성능 병목 현상을 식별하고 비용을 최적화함으로써 쿼리를 보다 쉽게 조정할 수 있습니다. 프로그램이 실행되면 Microsoft의 실행 환경에서 프로그램을 활발히 분석하여 성능은 높이고 비용은 줄일 수 있는 다양한 사항을 권장해 줍니다. 데이터 엔지니어, DBA 및 데이터 설계자는 SQL, Apache Hadoop, Apache Spark, R, Python, Java 및 .NET과 같은 기존 기술을 사용하여 최고의 생산성을 얻을 수 있습니다.

기존 IT 투자에 원활하게 통합
빅 데이터와 관련된 가장 큰 문제 중 하나는 기존 IT 투자와의 통합입니다. Data Lake는 Cortana Intelligence의 핵심 부분으로, Azure Synapse Analytics, Power BI 및 Data Factory와 함께 사용되어 데이터 준비부터 대규모 데이터 세트에 대한 대화형 분석에 이르는 모든 작업을 지원하는 완전한 클라우드 빅 데이터 및 고급 분석 플랫폼을 구현합니다. Data Lake Analytics를 사용하면 가상 머신의 Azure SQL Server, Azure SQL Database 및 Azure Synapse Analytics와 같은 관계형 원본의 최적화된 데이터 가상화를 사용하여 모든 데이터를 처리할 수 있습니다. 또한 데이터를 옮기지 않고 처리 위치를 소스 데이터 근처로 옮겨 쿼리를 자동으로 최적화하므로 성능은 최대화되고 대기 시간은 최소화할 수 있습니다. 마지막으로, Data Lake는 Azure에 포함되어 있으므로 IoT(사물 인터넷) 시나리오의 디바이스가 수집하거나 애플리케이션이 생성하는 모든 데이터에 연결할 수 있습니다.
페타바이트급 파일과 방대한 규모의 개체를 저장하고 분석
Data Lake는 클라우드 규모 및 성능에 맞게 처음부터 새롭게 설계되었습니다. 조직은 Azure Data Lake Store를 사용하여 어떤 인위적인 제약 없이 한곳에서 모든 데이터를 분석할 수 있습니다. Data Lake Store에서 저장할 수 있는 파일 개수는 방대하며, 저장 가능한 단일 파일 크기는 1페타바이트 이상으로 다른 클라우드 저장소보다 200배 더 큽니다. 즉, 저장된 데이터 크기 또는 사용되는 컴퓨팅 용량을 늘리거나 줄일 때 코드를 다시 작성할 필요가 없습니다. 따라서 대용량 데이터 세트를 처리하고 저장하는 방식이 아닌 비즈니스 논리에만 집중할 수 있습니다. 또한 Data Lake는 클라우드의 빅 데이터와 관련된 복잡성을 해소하며 현재 및 미래의 비즈니스 요구를 충족할 수 있습니다.

저렴하고 경제적
Data Lake는 빅 데이터 작업을 실행하기 위한 비용 효과적인 솔루션입니다. 데이터가 처리될 때 주문형 클러스터와 작업 기준 지급 모델 중에서 선택할 수 있습니다. 두 경우 모두 하드웨어, 라이선스 또는 서비스별 지원 계약이 필요하지 않습니다. 시스템은 비즈니스 요구에 따라 확장되거나 축소되므로 필요한 규모 이상으로 비용을 들일 필요가 없습니다. 또한 이 서비스를 사용하면 스토리지와 컴퓨팅 작업을 따로 확장할 수 있으므로 경제적인 측면에서 기존의 빅 데이터 솔루션보다 훨씬 더 유연합니다. 마지막으로, 이 서비스는 일반적으로 빅 데이터 인프라 실행과 관련된 특별 업무 팀을 유지할 필요를 최소화합니다. Data Lake는 데이터 투자 수익을 극대화하면서 비용을 최소화합니다. 최근 연구에 따르면, HDInsight를 사용하면 Hadoop을 온-프레미스로 배포하는 것보다 5년간 TCO가 63% 감소하는 것으로 나타났습니다.

엔터프라이즈급 보안, 감사 및 지원
Data Lake는 Microsoft에서 전적으로 관리 및 지원하고, 엔터프라이즈급 SLA 및 지원을 통해 지원을 받을 수 있습니다. 고객 지원 서비스가 연중무휴로 제공되므로 빅 데이터 솔루션 전반에서 발생하는 문제를 해결하기 위해 도움을 요청할 수 있습니다. Microsoft 팀에서는 사용자의 배포를 모니터링하며 지속적으로 실행될 수 있도록 보장하므로 사용자가 직접 모니터링하지 않아도 됩니다. Data Lake는 데이터 자산을 보호하고 온-프레미스 보안과 거버넌스 통제를 클라우드로 쉽게 확장해 줍니다. 데이터는 늘 암호화되는데, 동적 데이터는 SSL을 사용하여 암호화되고 정적 데이터는 Azure Key Vault의 서비스나 사용자 관리형 HSM 백업 키를 사용하여 암호화됩니다. SSO(Single Sign-On)와 다단계 인증을 제공하는 것은 물론, 수백만 개 ID를 원활하게 관리할 수 있는 기능이 Azure Active Directory를 통해 기본으로 제공됩니다. Store에 저장된 모든 데이터에 대해 POSIX 기반으로 세부 조정된 ACL로 사용자와 그룹에 권한을 부여할 수 있으므로 역할 기반 액세스 제어가 가능합니다. 마지막으로, 모든 액세스나 시스템 구성 변경을 감사하기 때문에 보안 요건과 규정 준수 요건을 충족할 수 있습니다.
다음의 강력한 솔루션을 사용하여 Data Lake 솔루션 구축

HDInsight
클라우드 Hadoop, Spark, R Server, HBase 및 Storm 클러스터를 프로비전합니다.

Data Lake Analytics
빅 데이터를 쉽게 만드는 분산 분석 서비스
Azure Data Lake Storage
고성능 분석을 위한 확장 가능하고 안전한 데이터 레이크.