Announcements, Azure Kubernetes Service (AKS), Containers, Networking
Améliorer la résolution des problèmes Kubernetes avec le module complémentaire Network Observability dans AKS
Posted on
5 min read
À mesure que les environnements conteneurisés continuent de croître en complexité, il peut être de plus en plus difficile d’identifier la cause racine des problèmes réseau au sein d’un cluster Kubernetes. Les défaillances intermittentes et les goulots d’étranglement des performances peuvent être particulièrement frustrants et obtenir une visibilité complète de l’infrastructure réseau peuvent souvent sembler une tâche intimidante. De nombreuses organisations se retrouvent à la recherche de ces défis, qui ont du mal à trouver des solutions efficaces pour les résoudre.
Pour répondre à ces problèmes, nous sommes heureux d’annoncer la disponibilité d’Azure Kubernetes Service (AKS) : Observabilité réseau. Cette fonctionnalité offre aux clients des fonctionnalités puissantes pour bénéficier d’une meilleure visibilité sur leur trafic réseau de conteneurs. En fournissant des insights en temps réel et des métriques de mise en réseau complètes, cette fonctionnalité permet aux administrateurs et aux développeurs de résoudre efficacement les problèmes réseau et d’optimiser les performances de leurs applications conteneurisées.
Dans ce billet de blog, nous allons examiner les détails de cette nouvelle fonctionnalité d’observabilité réseau passionnante dans AKS. Nous allons explorer ses fonctionnalités, ses cas d’usage et discuter des avantages de cette fonctionnalité.
Qu’est-ce que l’observabilité réseau pour AKS
La fonctionnalité d’observabilité réseau dans AKS est une solution de supervision distribuée qui fonctionne à la fois pour les environnements d’hébergement Linux et Windows. Ce module complémentaire permet d’obtenir des insights sur l’infrastructure de mise en réseau en collectant des points de données en temps réel tirant parti de l’eBPF dans Linux, de la plateforme de filtrage virtuel (VFP) et du service de mise en réseau hôte (HNS) dans Windows et de les fournir à consommer dans Prometheus et Grafana.
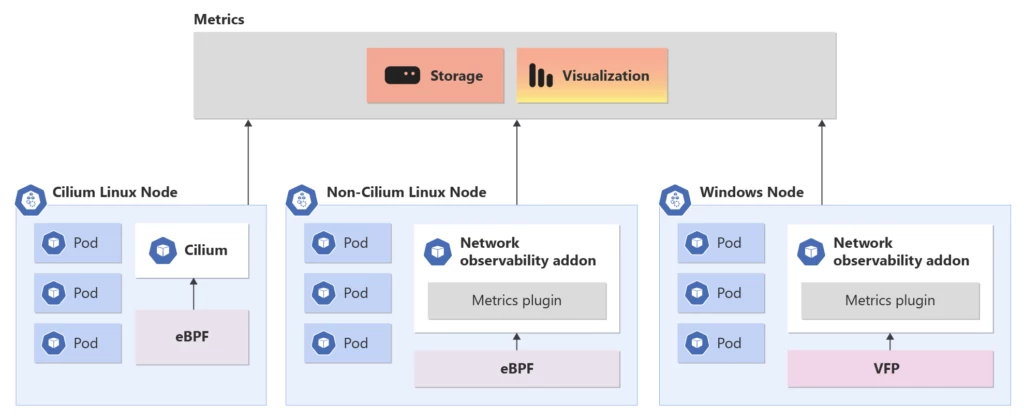
Visualisation des données d’observabilité réseau
Azure Managed Prometheus et Grafana :
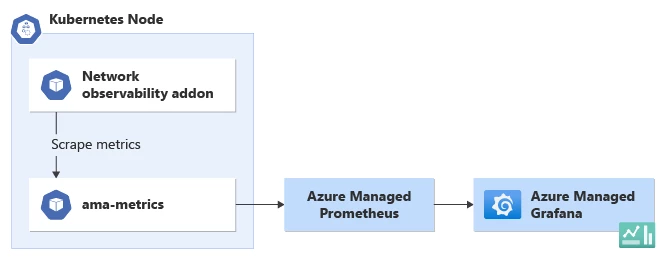
Avec l’approche Prometheus et Grafana gérée par Azure, Microsoft Azure offre des services intégrés qui simplifient l’installation et la gestion de la supervision et de la visualisation. Azure Monitor fournit une instance managée de Prometheus, qui collecte et stocke les métriques à partir de différentes sources, y compris le module complémentaire d’observabilité réseau. Grafana, une plateforme open source populaire pour la visualisation des données, est intégrée en toute transparence à Azure Monitor. Les utilisateurs peuvent tirer parti des tableaux de bord et modèles préconfigurés spécifiquement conçus pour AKS et le module complémentaire d’observabilité réseau. Ces tableaux de bord fournissent une vue complète des métriques réseau, ce qui permet aux utilisateurs de surveiller et d’analyser les données de manière visuellement attrayante et intuitive.
Pour configurer l’observabilité réseau à l’aide de l’approche Prometheus et Grafana managée par Azure, les utilisateurs peuvent suivre la documentation Azure. Une fois configurés, ils peuvent accéder à l’interface Grafana pour explorer les tableaux de bord prédéfinis ou créer des visualisations personnalisées adaptées à leurs besoins spécifiques. L’intégration entre Azure Monitor, Prometheus et Grafana simplifie le processus de visualisation des données d’observabilité réseau, ce qui permet aux utilisateurs d’obtenir des insights précieux sur les performances réseau de leur cluster AKS.
Apportez votre propre prometheus (BYO) et Grafana :
(Pour les utilisateurs avancés à l’aise avec une surcharge de gestion accrue)
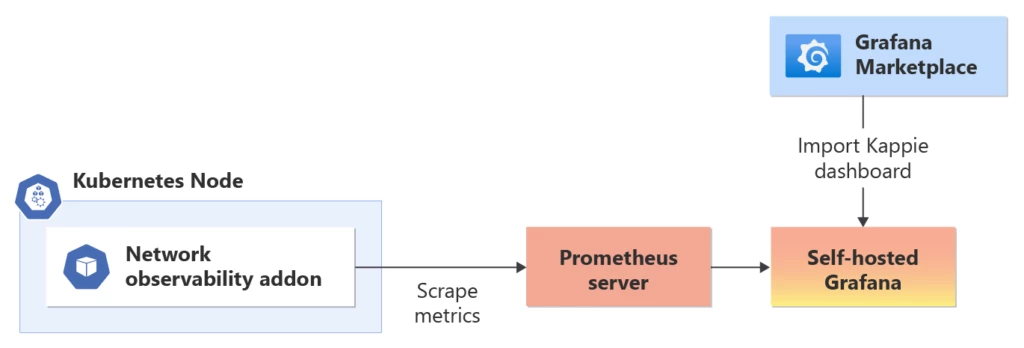
Vous pouvez également configurer et gérer leurs propres instances Prometheus et Grafana. Cette approche offre plus de flexibilité et de contrôle sur la configuration et la personnalisation de la pile de surveillance et de visualisation. Les utilisateurs peuvent déployer Prometheus et Grafana en tant que composants distincts au sein de leur infrastructure ou utiliser des versions conteneurisées s’exécutant en même temps que leur cluster AKS.
La configuration d’un byO Prometheus implique la configuration de Prometheus pour récupérer les métriques exposées par le module complémentaire d’observabilité réseau. Les utilisateurs peuvent définir des configurations de récupération pour collecter les métriques pertinentes et les stocker dans la base de données de série chronologique de Prometheus. Grafana peut ensuite être connecté à Prometheus pour créer des tableaux de bord et des visualisations personnalisés. Les utilisateurs peuvent concevoir leurs propres tableaux de bord Grafana ou importer des modèles fournis par la communauté pour visualiser les métriques d’observabilité réseau en fonction de leurs besoins et préférences de surveillance spécifiques. Les utilisateurs peuvent suivre la documentation Azure pour activer le module complémentaire d’observabilité réseau pour et visualiser à l’aide de BYO Prometheus et de Grafana.
En utilisant BYO Prometheus et Grafana, les utilisateurs contrôlent complètement le déploiement, la configuration et la personnalisation de leur pile de surveillance et de visualisation. Cette approche permet des visualisations plus avancées et personnalisées des données d’observabilité réseau, ce qui permet aux utilisateurs de concevoir des tableaux de bord perspicaces qui s’alignent sur leurs exigences de surveillance uniques.
Cas d’utilisation
Scénario client 1 : Suppression de la stratégie réseau
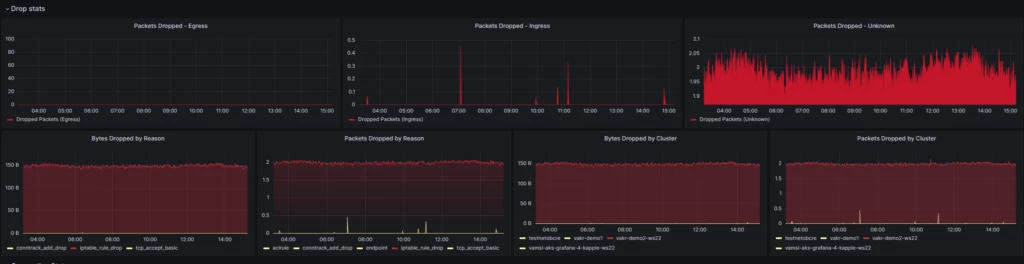
Le débogage de stratégies réseau dans de grands clusters complexes avec plusieurs espaces de noms peut être une tâche intimidante, en particulier lorsqu’il existe de nombreuses stratégies réseau par espace de noms. Pour relever ce défi, le module complémentaire de stratégie réseau utilise eBPF dans Linux pour collecter des informations cruciales sur les paquets supprimés. En attachant des kprobes à différents emplacements critiques dans le noyau Linux, comme la fonction de suppression netfilter et la fonction nat netfilter, le module complémentaire de stratégie réseau détermine efficacement si un paquet est supprimé.
Lorsqu’un paquet supprimé est détecté, les programmes eBPF associés génèrent un événement qui inclut des métadonnées de paquets, ainsi que la raison de suppression et l’emplacement. Cet événement est ensuite traité par un programme userspace, qui analyse les données et les convertit en métriques Prometheus. Ces métriques fournissent des insights précieux sur les paquets supprimés, ce qui facilite l’identification et la résolution des problèmes de configuration de stratégie réseau.
Dans Windows, le VFP et HNS fournissent des compteurs pour la liste de contrôle d’accès (ACL) ou les suppressions de règles de point de terminaison. Notre module complémentaire d’observabilité réseau récupère ces compteurs et convertit les données en métriques Prometheus, ce qui garantit une surveillance cohérente et complète sur différentes plateformes.
Pour illustrer les fonctionnalités de notre solution, tenez compte de l’exemple suivant, présentant des paquets supprimés avec différentes raisons, telles que les iptables ou la liste de contrôle d’accès :
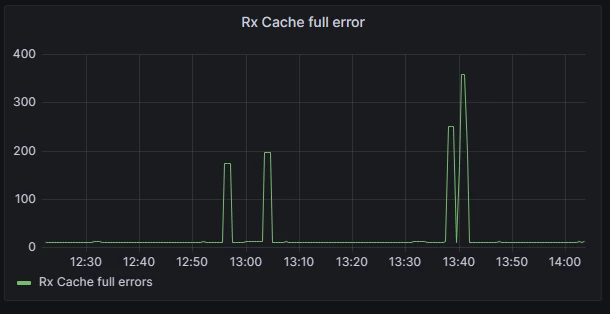
Scénario client 2 : Recevoir le cache complet
Dans Azure, la mise en réseau accélérée est activée par défaut pour presque toutes les machines virtuelles Linux. Avec l’introduction de la mise en réseau accélérée, chaque interface réseau est allouée à un espace mémoire dédié pour la réception de paquets. Le module complémentaire d’observabilité réseau joue un rôle crucial dans la surveillance de cette allocation de mémoire en examinant la statistique complète du cache Rx sur chaque interface et en la convertissant en métriques Prometheus. En procédant ainsi, les utilisateurs obtiennent des insights précieux sur les performances de leurs interfaces réseau.
Le diagramme ci-dessous illustre un scénario spécifique dans lequel une machine virtuelle fonctionne à sa capacité maximale, recevant des paquets au débit de ligne. Dans ce cas, les utilisateurs peuvent rencontrer des pics de latence intermittents ou des chutes de paquets. En corrélisant rapidement ces informations avec le graphique fourni, il devient évident que lorsque les pics de métriques « Mémoire tampon Rx complète », la mémoire tampon de réception de l’interface réseau devient saturée, ce qui peut entraîner des chutes de paquets ou une augmentation de la latence des paquets en attente de traitement.
Avantages
Visibilité réseau améliorée : le module complémentaire d’observabilité réseau permet aux utilisateurs d’obtenir une visibilité approfondie de leur infrastructure réseau, ce qui leur permet d’identifier et de résoudre les problèmes liés aux stratégies réseau, aux chutes de paquets, aux pics de latence et aux autres problèmes liés aux performances.
Fonctionnalités de débogage améliorées : en tirant parti d’eBPF et d’autres mécanismes de surveillance, le module complémentaire fournit des insights précieux sur les configurations de stratégie réseau, ce qui permet un débogage et une résolution des problèmes efficaces. Les utilisateurs peuvent rapidement identifier les stratégies réseau mal configurées et les résoudre rapidement.
Surveillance et alertes en temps réel : avec la conversion des métriques d’observabilité réseau en métriques Prometheus, les utilisateurs peuvent surveiller leurs performances réseau en temps réel. Ils peuvent configurer des alertes et des notifications pour résoudre de manière proactive toutes les anomalies, ce qui garantit une haute disponibilité et des performances optimales de leur infrastructure réseau.
Compatibilité de la plateforme : le module complémentaire d’observabilité réseau est conçu pour fonctionner en toute transparence sur différentes plateformes, notamment Linux et Windows. Cette compatibilité permet aux utilisateurs de maintenir une expérience de supervision cohérente sur l’ensemble de leur infrastructure, quel que soit le système d’exploitation sous-jacent.
Vue historique de plusieurs clusters : l’activation de plusieurs clusters avec un module complémentaire d’observabilité réseau et leur connexion au même Prametheus et Grafana gérés par Azure facilitent dans un seul volet de verre pour visualiser les performances réseau de tous vos clusters au fil du temps.
En savoir plus
Lisez-en davantage dans la documentation du module complémentaire d’observabilité réseau et vous pouvez également regarder une démonstration sur la chaîne YouTube De Microsoft.
- En savoir plus sur Azure Kubernete Service.
- Explorez Azure Linux pour obtenir plus d’informations.
- Découvrez plus d’informations sur Azure Monitor.