
Kubernetes: Kom i gang
Få mere at vide om, hvordan du begynder at udrulle og administrere programmer, der er placeret i objektbeholdere.
En begynderbog om objektbeholdere
Før du begynder at bruge Kubernetes, er det vigtigt at forstå, hvordan placering i objektbeholdere fungerer.
På samme måde, som shippingindustrien bruger fysiske containere til at isolere forskelligt gods til transport på skibe, toge, lastbiler og fly, bruger teknologier til softwareudvikling i stigende grad et koncept, der kaldes for placering i objektbeholdere.
En enkelt pakke med software – kendt som en objektbeholder – bundter en programkode sammen med de relaterede konfigurationsfiler, biblioteker og de afhængigheder, der kræves for at programmet kan køre. Det giver udviklere og it-teknikere mulighed for at oprette og udrulle programmer hurtigere og mere sikkert.
Placering i objektbeholdere giver fordelene ved isolation, bevægelighed, fleksibilitet, skalerbarhed og kontrol af adgang på tværs af hele arbejdsprocessen for et programs levetid. En objektbeholder, som befinder sig væk fra værtsoperativsystemet, står alene og bliver mere bærbar, dvs. at den kan køre på tværs af en hvilken som helst platform eller et hvilket som helst cloudmiljø på en ensartet måde på en hvilken som helst infrastruktur.
Kubernetes-komponenter og -koncepter
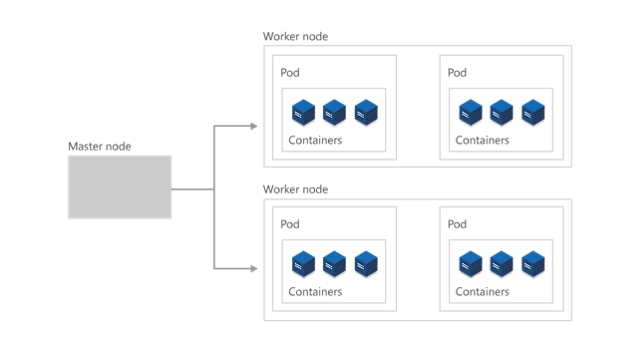
Klyngen
På højeste niveau er Kubernetes organiseret som en klynge af virtuelle maskiner eller maskiner i det lokale miljø. Disse maskiner, som kaldes for noder, deler beregnings-, netværks- og lagerressourcer. Hver klynge har én masternode, som er forbundet til en eller flere arbejdsnoder. Arbejdsnoderne er ansvarlige for at køre grupper af programmer og arbejdsbelastninger, som er placeret i objektbeholdere, hvilket er kendt som pods, og masternoden administrerer, hvilke pods der kører på hvilke arbejdsnoder.
Kontrolniveauet
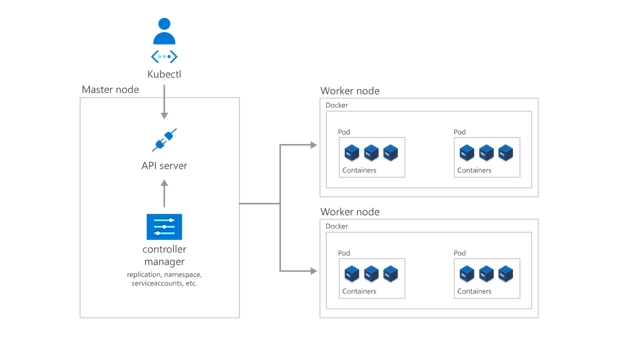
Kubernetes indeholder en række objekter, som samlet udgør kontrolniveauet, hvilket gør, at masternoden kan kommunikere med arbejdsnoden – og at en person kan kommunikere med masternoden.
Udviklere og operatorer interagerer primært med klyngen gennem masternoden ved hjælp af kommandolinjegrænsefladen kubectl, som installeres på det lokale operativsystem. Kommandoer, der udstedes til klyngen via kubectl, modtages af Kubernetes-API'en, kube-apiserver, som er placeret på masternoden. Kube-apiserver kommunikerer derefter anmodninger til kube-controller-manager i masternoden, der til gengæld er ansvarlig for at håndtere handlinger for arbejdsnoder. Kommandoer fra masternoden modtages af kubelet på arbejdsnoderne.
Udrulning af programmer og arbejdsbelastninger
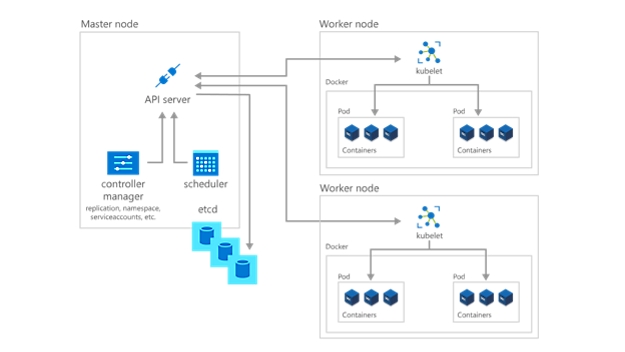
Det næste trin til at komme i gang med Kubernetes er at udrulle programmer og arbejdsbelastninger. Masternoden opretholder konstant den aktuelle tilstand for Kubernetes-klyngen og -konfigurationen i databasen til lagring af nøgleværdier, etcd. Hvis du vil køre pods med dine programmer og arbejdsbelastninger, som er placeret i objektbeholdere, skal du beskrive en ny ønsket tilstand til klyngen i form af en YAML-fil. Kube-controller-manager bruger YAML-filen og giver kube-scheduler til opgave at beslutte, hvilke arbejdsnoder programmet eller arbejdsbelastningen skal køre ud fra forudbestemte begrænsninger. Når man arbejder samlet med hver arbejdsnodes kubelet, starter kube-scheduler de pågældende pods, observerer maskinernes tilstand og er overordnet ansvarlig for administrationen af ressourcer.
I en Kubernetes-udrulning bliver den ønskede tilstand, som du beskriver, den aktuelle tilstand i etcd, men den forrige tilstand går ikke tabt. Kubernetes understøtter annullering af opdateringer og udrulning af opdateringer samt muligheden for at sætte udrulninger på pause. Udrulninger bruger desuden ReplicaSets i baggrunden for at sikre, at det angivne antal identisk konfigurerede pods kører. Hvis der skulle opstå fejl på en eller flere pods, erstatter ReplicaSet dem. Derfor kan man sige, at Kubernetes er selvreparerende.
Strukturering og beskyttelse af Kubernetes-miljøer
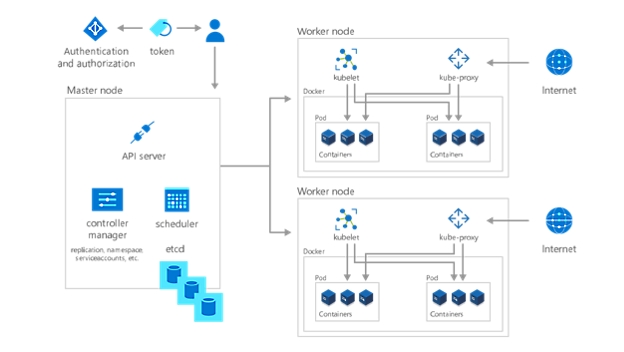
Når du har udrullet dit program eller din arbejdsbelastning, er det sidste trin til at komme i gang med Kubernetes at organisere dem – og beslutte, hvem eller hvad der har adgang til dem. Ved at oprette et navneområde, som er en grupperingsmetode i Kubernetes, giver du tjenester, pods, controllere og enheder mulighed for at arbejde nemt sammen, mens du isolerer dem fra andre dele af klyngen. Brug også Kubernetes-konceptet om navneområder til at anvende ensartede konfigurationer til ressourcer.
Hver arbejdsnode indeholder desuden en kube-proxy, der bestemmer, hvordan forskellige aspekter af klyngen kan tilgås udefra. Gem følsomme oplysninger, som ikke er offentlige, f.eks. tokens, certifikater og adgangskoder i hemmeligheder – et andet Kubernetes-objekt – der kodes, indtil det køres.
Sidst men ikke mindst kan du angive, hvem der kan se og interagere med hvilke dele af klyngen – og på hvilken måde de må interagere med den – ved hjælp af rollebaseret adgangskontrol.
Implementer en fuldt administreret Kubernetes-løsning
Administrer dit hostede Kubernetes-miljø med Azure Kubernetes Service (AKS). Udrul og vedligehold programmer, der er placeret i objektbeholdere, uden oplevelsen til orkestrering af objektbeholdere. Klargør, opgrader og skaler ressourcer efter behov – uden at programmerne skal være offline.
Hurtig start til Kubernetes: Kom i gang på 50 dage
Brug denne trinvise vejledning til at komme i gang med Kubernetes, og få praktisk erfaring med Kubernetes-komponenter, -egenskaber og -løsninger.
Deltag i Kubernetes-læringsforløbet