

Data Lake
Data Lake sans limites pour agir en connaissance de cause.
- Stockez et analysez des fichiers dont la taille est de plusieurs pétaoctets, ainsi que des billions d’objets
- Déboguez et optimisez facilement vos programmes Big Data
- Démarrez en quelques secondes, adaptez la taille instantanément, payez à la tâche
- Développez des programmes hautement parallèles en toute simplicité
- Support, audit et sécurité à l’échelle de l’entreprise
- Basé sur YARN, conçu pour le nuage
Azure Data Lake inclut toutes les fonctionnalités permettant aux développeurs, scientifiques des données et analystes de stocker les données, quelles que soient leur taille, leur forme ou leur vitesse, et d’effectuer tous types de traitement et d’analyse sur les différents langages et plateformes. Il élimine la complexité liée à la réception et au stockage de l’ensemble de vos données, tout en accélérant la mise en route du traitement par lots, du streaming ou des analyses interactives. Azure Data Lake fonctionne avec les investissements informatiques existants relatifs à l’identité, à la gestion et à la sécurité pour une gouvernance et une gestion des données simplifiées. Il s’intègre également en toute transparence avec les magasins et les entrepôts de données opérationnels afin que vous puissiez étendre vos applications de données actuelles. Nous avons tiré parti de l’expérience acquise grâce à la collaboration avec des entreprises clientes et à l’exécution de certains des plus importants traitements et analyses du monde pour des produits Microsoft, tels que Office 365, Xbox Live, Azure, Windows, Bing et Skype. Azure Data Lake répond aux nombreux défis en matière de productivité et d’extensibilité qui vous empêchent d’accroître la valeur de vos actifs données en cours avec un service prêt à répondre aux besoins actuels et futurs de votre entreprise.
Azure Data Lake inclut toutes les fonctionnalités permettant aux développeurs, scientifiques des données et analystes de stocker les données, quelles que soient leur taille, leur forme ou leur vitesse, et d’effectuer tous types de traitement et d’analyse sur les différents langages et plateformes. Il élimine la complexité liée à la réception et au stockage de l’ensemble de vos données, tout en accélérant la mise en route du traitement par lots, du streaming ou des analyses interactives. Azure Data Lake fonctionne avec les investissements informatiques existants relatifs à l’identité, à la gestion et à la sécurité pour une gouvernance et une gestion des données simplifiées. Il s’intègre également en toute transparence avec les magasins et les entrepôts de données opérationnels afin que vous puissiez étendre vos applications de données actuelles. Nous avons tiré parti de l’expérience acquise grâce à la collaboration avec des entreprises clientes et à l’exécution de certains des plus importants traitements et analyses du monde pour des produits Microsoft, tels que Office 365, Xbox Live, Azure, Windows, Bing et Skype. Azure Data Lake répond aux nombreux défis en matière de productivité et d’extensibilité qui vous empêchent d’accroître la valeur de vos actifs données en cours avec un service prêt à répondre aux besoins actuels et futurs de votre entreprise.
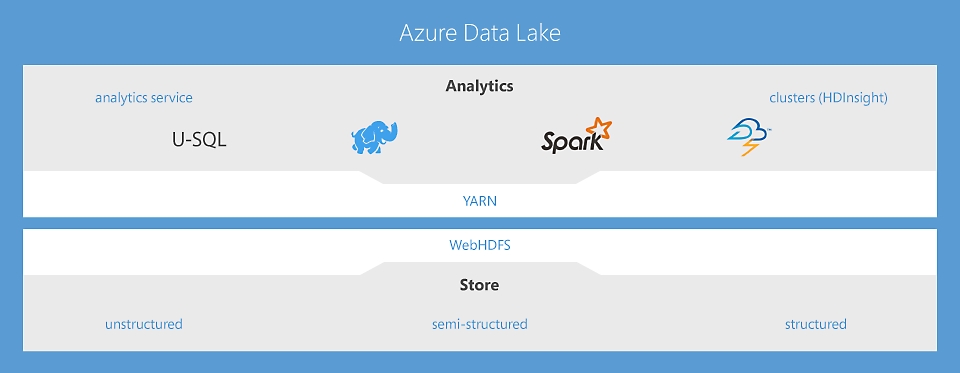
Data Lake Analytics, service de travail d’analyse sans limites pour agir en connaissance de cause
Le premier service d’analyse nuage dans lequel vous pouvez facilement développer et exécuter des programmes écrits en U-SQL, R, Python et .Net pour transformer et traiter plusieurs pétaoctets de données. Sans aucune infrastructure à gérer, vous pouvez traiter les données à la demande, vous adapter rapidement au volume à gérer et payer uniquement en fonction des travaux effectués. En savoir plus

HDInsight : service Hadoop® et Apache Spark dans le nuage pour l’entreprise
HDInsight est la seule offre nuage Hadoop complètement managée qui fournit des clusters d’analyse open source optimisés pour Spark, Hive, Map Reduce, HBase, Storm, Kafka et R-Server, avec un contrat SLA proposant une disponibilité de 99,9 %. Chacune de ces technologies Big Data ainsi que les applications d’éditeurs de logiciels indépendants (ISV) sont facilement déployables sous forme de clusters gérés, avec une surveillance et une sécurité à l’échelle de l’entreprise. En savoir plus

Data Lake Store sans limites pour l’analyse Big Data
Le premier Data Lake nuage pour entreprises qui est sécurisé, hautement scalable et conçu pour utiliser la norme ouverte HDFS. Avec l’absence de limite à la taille des données et la possibilité de lancer des analyses hautement parallèles, vous tirez un maximum de valeur de vos données, qu’elles soient structurées, semi-structurées ou non structurées. En savoir plus

Développez , déboguez et optimisez facilement les programmes Big Data
Il peut s’avérer difficile de trouver les bons outils pour concevoir et configurer vos requêtes concernant les Big Data. L’étroite intégration de Data Lake avec Visual Studio, Eclipse et IntelliJ vous permet d’utiliser des outils familiers pour exécuter, déboguer et optimiser votre code. Les visualisations de vos travaux U-SQL, Apache Spark, Apache Hive et Apache Storm vous permettent de voir la façon dont votre code est exécuté à l’échelle. Vous pouvez ainsi identifier les goulots d’étranglement en matière de performances et les optimisations de coûts, ce qui facilite la configuration de vos requêtes. Notre environnement d’exécution analyse de façon proactive vos programmes lors de leur exécution et propose des recommandations visant à améliorer les performances et à réduire les coûts. Les ingénieurs de données, les administrateurs de bases de données et les architectes de données peuvent utiliser les compétences existantes, telles que SQL, Apache Hadoop, Apache Spark, R, Python, Java et .NET pour gagner en productivité dès le premier jour.

S’intègre de façon transparente avec vos investissements informatiques existants
Un des plus gros défis posés par les fonctionnalités Big Data est l’intégration avec les investissements informatiques existants. Le service Data Lake est un composant clé de Cortana Intelligence. Il fonctionne avec Azure Synapse Analytics, Power BI et Data Factory pour fournir une plateforme nuage complète dotée de fonctionnalités Big Data et d’analytique avancée qui vous permet d’effectuer de nombreuses opérations, de la préparation des données à l’analytique interactive de jeux de données à grande échelle. Data Lake Analytics vous permet d’agir sur l’ensemble de vos données, avec la virtualisation optimisée pour les données de vos sources relationnelles, comme Azure SQL Server sur les machines virtuelles, Azure SQL Database et Azure Synapse Analytics. Les requêtes sont automatiquement optimisées en déplaçant le calcul au plus près de la source de données, sans déplacement de ces données, ce qui permet d’optimiser les performances et de réduire la latence. Enfin, comme Data Lake est situé dans Azure, vous pouvez vous connecter aux données générées par les applications ou reçues par les appareils dans des scénarios IoT (Internet of Things).
Stockez et analysez des fichiers dont la taille est de plusieurs pétaoctets, ainsi que des billions d’objets
Data Lake a été conçu pour fournir des performances et une mise à l’échelle dans le nuage. Avec Azure Data Lake Store, votre organisation est en mesure d’analyser toutes ses données en un seul et même emplacement, sans aucune contrainte artificielle. Votre Data Lake Store peut stocker des billions de fichiers, chaque fichier pouvant être de plus d’un pétaoctet, ce qui représente 200 fois la taille permise par les autres services nuage. Cela signifie que vous n’avez pas besoin de réécrire le code à mesure que vous augmentez ou diminuez la taille des données stockées ou le volume de calcul utilisé. Vous pouvez ainsi vous concentrer uniquement sur votre logique métier, et non sur la manière dont vous traitez et stockez les jeux de données volumineux. Data Lake élimine la complexité normalement associée aux Big Data dans le nuage et s’assure de répondre aux besoins actuels et futurs de votre entreprise.

Abordable et économique
Data Lake est une solution économique permettant d’exécuter des charges de travail Big Data. Vous pouvez choisir entre des clusters à la demande ou un modèle de paiement basé sur les travaux impliquant un traitement des données. Dans les deux cas, aucun matériel, aucune licence ni aucun contrat de support technique propre au service ne sont requis. Le système est mis à l’échelle selon les besoins de votre entreprise. Vous payez donc uniquement ce dont vous avez besoin. Il vous permet également de mettre à l’échelle indépendamment le stockage et le calcul, fournissant ainsi une flexibilité plus rentable que celle des solutions Big Data classiques. Enfin, il réduit au minimum le besoin d’embaucher les équipes des opérations spécialisées généralement associées à l’exécution d’une infrastructure Big Data. Data Lake réduit vos coûts tout en optimisant le retour sur investissement de vos données. Une récente étude a démontré que HDInsight offre un coût total de possession inférieur de 63 % à celui d’un déploiement Hadoop en local sur cinq ans.

Support, audit et sécurité à l’échelle de l’entreprise
Data Lake est entièrement géré et pris en charge par Microsoft. Il bénéficie d’un contrat SLA d’entreprise et d’un support technique. Le support étant disponible 7 j/7 et 24 h/24, vous pouvez nous contacter si vous avez besoin d’aide concernant votre solution Big Data. Notre équipe surveille votre déploiement à votre place et veille à la continuité de son exécution. Data Lake protège vos données et prolonge de façon simple jusque dans le nuage vos procédures de sécurité et de gouvernance locales. Les données restent chiffrées : par SSL lorsqu’elles sont déplacées et par des services ou clés HSM dans Azure Key Vault, gérés par les utilisateurs lors de leur stockage. Les fonctionnalités d’authentification unique (SSO), d’authentification multifacteur et de gestion transparente de millions d’identités sont intégrées via Azure Active Directory. Vous pouvez autoriser des utilisateurs et des groupes avec des listes de contrôle d’accès POSIX pour toutes les données stockées, avec des contrôles d’accès en fonction du rôle. Enfin, vous pouvez appliquer les mesures de sécurité et de conformité en analysant chaque modification des accès ou de la configuration du système.
Générez des solutions Data Lake à l’aide de ces puissantes solutions

HDInsight
Approvisionnez les clusters Hadoop, Spark, R Server, HBase et Storm dans le nuage.

Data Lake Analytics
Service d’analyse distribué qui facilite l’utilisation du Big Data.
Azure Data Lake Storage
Lac de données évolutif et sécurisé pour des analyses hautes performances.