

Azure Data Lake
Озеро данных без ограничений и безграничные интеллектуальные возможности.
- Хранение и анализ петабайтовых файлов и миллиардов объектов
- Простая отладка и оптимизация программ для работы с большими данными
- Быстрое начало работы, мгновенное масштабирование и оплата за задание
- Простая разработка программ массовых параллельных операций
- Безопасность, аудит и поддержка корпоративного уровня
- Создано на базе YARN, разработано для облака
В Azure Data Lake представлены все возможности, упрощающие хранение данных любых объема, формата и скорости передачи, а также выполнение любых видов обработки и анализа на разных платформах и языках для разработчиков, специалистов по обработке и анализу данных и аналитиков. Azure Data Lake упрощает получение и хранение всех ваших данных, одновременно ускоряя работу пакетной, потоковой и интерактивной аналитики. Azure Data Lake позволяет избежать расходов и использовать существующие удостоверения, системы управления и безопасности, упрощая управление данными. Система легко интегрируется с промежуточными и постоянными хранилищами данных, позволяя расширить текущие приложения для обработки данных. Мы опирались на опыт работы с корпоративными клиентами, а также обработку и анализ больших данных для таких продуктов Майкрософт, как Office 365, Xbox Live, Azure, Windows, Bing и Skype. Azure Data Lake решает многие проблемы производительности и масштабируемости и позволяет извлечь максимальную пользу из накопленных данных, предоставляя службу, способную удовлетворить все текущие и будущие потребности бизнеса.
В Azure Data Lake представлены все возможности, упрощающие хранение данных любых объема, формата и скорости передачи, а также выполнение любых видов обработки и анализа на разных платформах и языках для разработчиков, специалистов по обработке и анализу данных и аналитиков. Azure Data Lake упрощает получение и хранение всех ваших данных, одновременно ускоряя работу пакетной, потоковой и интерактивной аналитики. Azure Data Lake позволяет избежать расходов и использовать существующие удостоверения, системы управления и безопасности, упрощая управление данными. Система легко интегрируется с промежуточными и постоянными хранилищами данных, позволяя расширить текущие приложения для обработки данных. Мы опирались на опыт работы с корпоративными клиентами, а также обработку и анализ больших данных для таких продуктов Майкрософт, как Office 365, Xbox Live, Azure, Windows, Bing и Skype. Azure Data Lake решает многие проблемы производительности и масштабируемости и позволяет извлечь максимальную пользу из накопленных данных, предоставляя службу, способную удовлетворить все текущие и будущие потребности бизнеса.
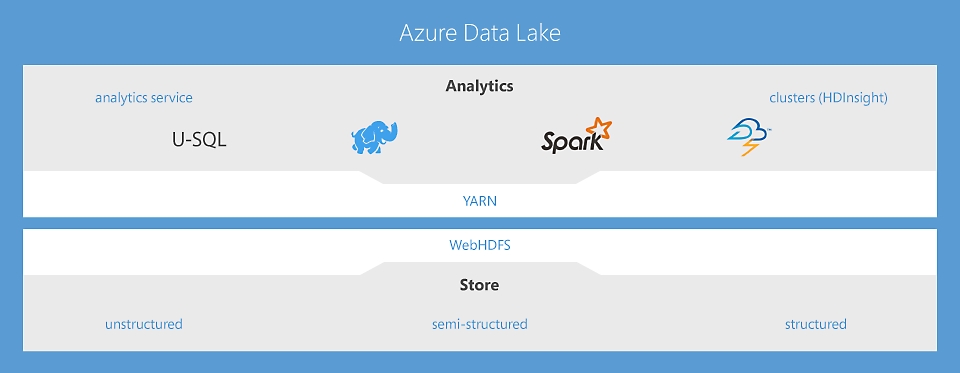
Data Lake Analytics — служба заданий аналитики без ограничений, расширяющая возможности для интеллектуальных действий
Это первая облачная служба аналитики, в которой можно с легкостью разрабатывать и выполнять программы обработки и программы массовых параллельных операций преобразования петабайтов данных на U-SQL, R, Python и .NET. Из-за отсутствия необходимости управлять инфраструктурой можно обрабатывать данные по требованию, мгновенно выполнять масштабирование и при этом платить только за выполненные задания. Подробнее

HDInsight — облачная служба Apache Spark и Hadoop® для предприятий
HDInsight — единственное полностью управляемое облачное предложение Hadoop, предоставляющее оптимизированные аналитические кластеры с открытым кодом для Spark, Hive, MapReduce, HBase, Storm, Kafka и R Server и поддерживающее соглашение об уровне обслуживания, которое гарантирует непрерывную работу в течение 99,9% времени. Каждую из этих технологий работы с большими данными и каждое из этих приложений от независимых поставщиков программного обеспечения можно с легкостью развернуть в качестве управляемого кластера, обеспечивая при этом безопасность и мониторинг корпоративного класса. Подробнее

Data Lake Store: безграничные возможности для анализа больших данных
Это первое защищенное высокомасштабируемое облачное озеро данных, предназначенное для предприятий, создано в соответствии с открытыми стандартами HDFS. При отсутствии ограничений на размер данных и с возможностью выполнять огромное количество параллельных аналитических задач вы можете получить все преимущества неструктурированных, частично структурированных и структурированных данных. Подробнее

Простая разработка, отладка и оптимизация программ для работы с большими данными
Найти необходимые средства для разработки и настройки запросов для больших данных не всегда легко. Data Lake упрощает эту задачу за счет глубокой интеграции с Visual Studio, Eclipse и IntelliJ, предоставляя возможность использовать знакомые средства для запуска, отладки и оптимизации кода. Визуализация заданий U-SQL, Apache Spark, Apache Hive и Apache Storm позволяет визуально контролировать выполнение кода в большом масштабе, выявлять проблемы производительности и оптимизировать затраты, упрощая настройку запросов. Наша среда выполнения активно анализирует программы во время их работы и предусматривает рекомендации по повышению производительности и сокращению затрат. Специалисты по работе с данными, а также администраторы и архитекторы баз данных могут использовать имеющиеся навыки по работе с SQL, Apache Hadoop, Apache Spark, R, Python, Java и .NET и сразу же начать продуктивно работать.

Простая интеграция с существующих ИТ-компонентов
Одна из самых сложных задач обработки больших данных — интеграция с уже приобретенными ИТ-компонентами. Решение Data Lake — важная часть Cortana Intelligence. Оно работает с Azure Synapse Analytics, Power BI и Фабрикой данных, предоставляя полноценную платформу для больших данных и расширенной аналитики в облаке. Эта платформа решает все задачи — от подготовки данных до интерактивного анализа крупных наборов данных. Data Lake Analytics позволяет использовать все данные благодаря оптимизированной виртуализации данных из реляционных источников, таких как Azure SQL Server на виртуальных машинах, База данных SQL Azure и Azure Synapse Analytics. Оптимизация запросов осуществляется автоматически за счет перемещения обработки ближе к данным источника, но без перемещения самых данных. Таким образом производительность повышается, а задержка сводится к минимуму. Наконец, Data Lake входит в Azure, поэтому можно подключаться к любым данным, создаваемым приложениями или получаемым устройствами в сценариях Интернета вещей (IoT).
Хранение и анализ петабайтовых файлов и миллиардов объектов
Служба Data Lake с самого начала разрабатывалась для масштабирования и производительности облачных технологий. Благодаря Azure Data Lake Store ваша организация может использовать единое решение для анализа всех своих данных без искусственных ограничений. В Data Lake Store могут храниться миллиарды файлов, каждый размером больше одного петабайта. Это в 200 раз больше, чем в других облачных хранилищах. Это означает, что не нужно переписывать код при увеличении или уменьшении объема хранимых данных или используемых вычислительных ресурсов. Можно полностью сосредоточиться на бизнес-логике, а не на обработке и хранении больших наборов данных. Больше не нужно беспокоиться о сложностях, обычно связанных с большими данными в облаке. Data Lake сможет удовлетворить все текущие и будущие бизнес-потребности.

Доступное и экономичное решение
Data Lake — это экономичное решение для выполнения рабочих нагрузок с большими данными. При обработке данных можно выбрать между выделением кластеров по запросу и оплатой за каждое задание. В обоих случаях не требуется какого-либо оборудования, лицензий или соглашений об уровне поддержки. Система масштабируется в соответствии с потребностями бизнеса, и вам никогда не придется платить больше, чем необходимо. Система также позволяет независимо масштабировать хранилище и вычислительные ресурсы, обеспечивая больше экономической гибкости, чем традиционные решения для работы с большими данными. Наконец, она минимизирует необходимость нанимать специалистов, которые обычно требуются для обслуживания инфраструктуры для работы с большими данными. Data Lake сводит к минимуму затраты, при этом существенно повышая рентабельность инвестиций. По результатам недавнего исследования совокупная стоимость владения HDInsight за пять лет на 63% ниже, чем при локальном развертывании Hadoop.

Безопасность, аудит и поддержка корпоративного уровня
Корпорация Майкрософт осуществляет управление Data Lake, а также предоставляет соглашение об уровне обслуживания корпоративного класса и поддержку. Мы доступны круглосуточно, и вы можете обращаться по любому вопросу, связанному с решением по обработке больших данных. Наша команда контролирует состояние системы клиента, освобождая его от этой работы, и гарантирует непрерывность всех операций. Data Lake защищает ресурсы с данными и расширяет локальные средства обеспечения безопасности и контроля до уровня облака. Данные всегда шифруются: при перемещении — с использованием SSL, а при хранении — с использованием ключей HSM в Azure Key Vault, которыми управляет пользователь или служба. Azure Active Directory обеспечивает такие встроенные возможности, как единый вход, многофакторная проверка подлинности и свободное управление миллионами удостоверений. Вы можете проверять подлинность пользователей и групп, используя списки управления доступом на базе стандартов POSIX для всех типов данных в Store, что позволяет применять средства управления доступом на основе ролей. Наконец, аудит каждого события доступа или изменения конфигурации в системе позволяет выполнить все требования к безопасности и нормам.
Создайте решения Data Lake с помощью этих широких возможностей

HDInsight
Обеспечьте подготовку облачных кластеров Hadoop, Spark, R Server, HBase и Storm.

Data Lake Analytics
Распределенная служба аналитики упрощает работу с большими данными.
Azure Data Lake Storage
Масштабируемое безопасное озеро данных позволяет повысить производительность аналитики.