
Kubernetes: Introducción
Obtenga información sobre cómo empezar a implementar y administrar aplicaciones en contenedores.
Introducción a los contenedores
Antes de empezar con Kubernetes, es importante entender cómo funciona la creación de contenedores.
Del mismo modo que la industria naviera utiliza contenedores físicos para aislar las distintas cargas que transporta en barcos, trenes, camiones y aviones, las tecnologías de desarrollo de software recurren cada vez más a un concepto llamado "creación de contenedores".
Un único paquete de software conocido como contenedor agrupa el código de una aplicación junto con los archivos de configuración, las bibliotecas y las dependencias necesarias para que la aplicación funcione. Esto permite a los desarrolladores y profesionales de TI crear e implantar aplicaciones de forma más rápida y segura.
La creación de contenedores ofrece las ventajas del aislamiento, la portabilidad, la agilidad, la escalabilidad y el control en todo el flujo de trabajo del ciclo de vida de una aplicación. Un contenedor, separado del sistema operativo anfitrión, es independiente y más portátil, ya que puede ejecutarse en cualquier plataforma o nube, de manera uniforme y coherente en cualquier infraestructura.
Componentes y conceptos de Kubernetes
El clúster
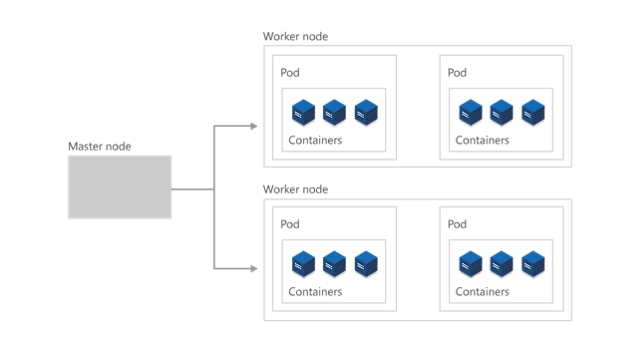
En el nivel más alto, Kubernetes se organiza como un clúster de máquinas virtuales o locales. Estas máquinas, denominadas "nodos", comparten recursos de proceso, red y almacenamiento. Cada clúster tiene un nodo principal conectado a uno o varios nodos de trabajo. Los nodos trabajadores se encargan de ejecutar grupos de aplicaciones y cargas de trabajo en contenedores, conocidos como pods, y el nodo maestro administra qué pods se ejecutan en qué nodos trabajo.
El plano de control
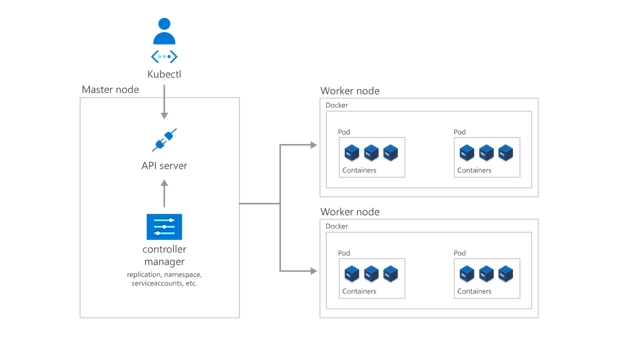
Para que el nodo principal se comunique con los nodos de trabajo y para que una persona se comunique con el nodo principal Kubernetes incluye una serie de objetos que forman colectivamente el plano de control.
Los desarrolladores y los operadores interactúan con el clúster principalmente a través del nodo principal mediante kubectl, una interfaz de la línea de comandos que se instala en su sistema operativo local. Los comandos emitidos al clúster a través de kubectl se envían al registro de kube-apiserver, la API de Kubernetes API que reside en el nodo principal. A continuación, el registro de kube-apiserver comunica las solicitudes al registro de kube-controller-manager en el nodo principal, que también es responsable de controlar las operaciones del nodo de trabajo. Los comandos del nodo principal son recibidos por el kubelet en los nodos de trabajo.
Implementación de aplicaciones y cargas de trabajo
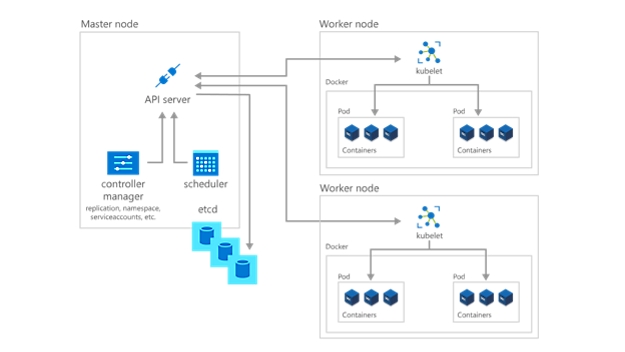
El siguiente paso para empezar a utilizar Kubernetes es implementar aplicaciones y cargas de trabajo. El nodo principal mantiene el estado actual del clúster de Kubernetes y la configuración en el servicio etcd, una base de datos de almacén de valores clave, en todo momento. Para ejecutar pods con sus cargas de trabajo y aplicaciones en contenedores, deberá describir un nuevo estado deseado para el clúster con el formato de un archivo YAML. El registro de kube-controller-manager toma el archivo YAML y encarga al registro de kube-scheduler la decisión sobre los nodos de trabajo que la aplicación o la carga de trabajo deben ejecutar según las restricciones predeterminadas. Trabajando conjuntamente con el kubelet de cada nodo de trabajo, el kube-scheduler inicia los pods, vigila el estado de las máquinas y es el responsable general de la administración de recursos.
En una implementación de Kubernetes, el estado deseado que usted describe se convierte en el estado actual en el etcd, pero el estado anterior no se pierde. Kubernetes admite las reversiones, la acumulación de actualizaciones y la pausa de lanzamientos Además, las implementaciones utilizan ReplicaSets en segundo plano para garantizar la ejecución del número especificado de pods configurados de forma idéntica. Si se producen errores en uno o más pods, el recurso ReplicaSet los reemplaza. De este modo, se dice que Kubernetes es autorreparable.
Estructuración y protección de entornos de Kubernetes
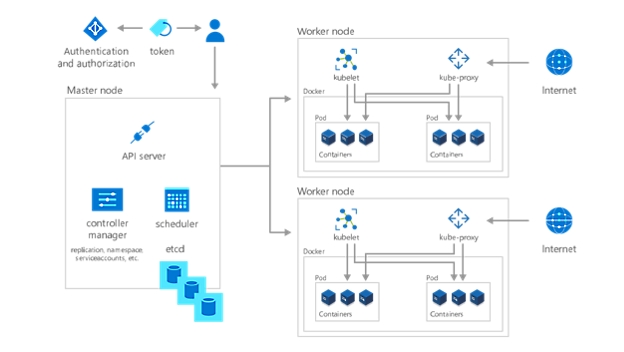
Una vez implementada la aplicación o la carga de trabajo, el último paso para empezar a utilizar Kubernetes es organizarlas y determinar quién o qué tiene acceso a ellas. Al crear un espacio de nombres, un método de agrupación en Kubernetes, permite que servicios, pods, controladores y volúmenes funcionen juntos a la vez que los aísla de otros componentes del clúster. Además, utiliza el concepto de espacios de nombres de Kubernetes para aplicar configuraciones coherentes a los recursos.
Además, cada nodo de trabajo contiene un kube-proxy, que determina cómo se puede acceder desde el exterior a diversos aspectos del clúster. Almacene información confidencial no pública como tokens, certificados y contraseñas en secretos u otro objeto de Kubernetes que se codifique hasta el tiempo de ejecución.
Por último, especifique quién puede ver e interactuar con qué partes del clúster, y cómo se les permite interactuar, mediante el control de acceso basado en roles (RBAC).
Implementación de una solución de Kubernetes completamente administrada
Administre su entorno hospedado de Kubernetes con Azure Kubernetes Service (AKS). Implemente y mantenga aplicaciones en contenedores sin experiencia en la orquestación de contenedores. Aprovisione, actualice y escale recursos a petición, sin tener que usar sus aplicaciones sin conexión.
Inicio rápido de Kubernetes: puesta en marcha en 50 días
Utilice esta guía paso a paso para iniciarse en Kubernetes y adquiera experiencia práctica con los componentes, las capacidades y las soluciones de Kubernetes.
Siga la ruta de aprendizaje de Kubernetes