Anahtar sözcük aramasında ilgi (BM25 puanlama)
Bu makalede, tam metin araması için arama puanlarını hesaplamak için kullanılan BM25 ilgi puanlama algoritması açıklanmaktadır. BM25'in ilgisi, tam metin aramasına özeldir. Filtre sorguları, otomatik tamamlama ve önerilen sorgular, joker karakter arama veya benzer arama sorguları ilgi için puanlanmamış veya derecelendirilmiyor.
Tam metin aramasında kullanılan puanlama algoritmaları
Azure AI Search, tam metin araması için aşağıdaki puanlama algoritmalarını sağlar:
| Algoritma | Kullanım | Aralık |
|---|---|---|
BM25Similarity |
Temmuz 2020'de oluşturulan tüm arama hizmetlerinde algoritma düzeltildi. Bu algoritmayı yapılandırabilirsiniz, ancak eski bir algoritmaya (klasik) geçemezsiniz. | Sınırsız. |
ClassicSimilarity |
Eski arama hizmetlerinde sunum yapma. BM25'i kabul edebilir ve dizin başına bir algoritma seçebilirsiniz. | 0 < 1,00 |
Hem BM25 hem de Klasik, her belge-sorgu çiftinin ilgi puanlarını hesaplamak için değişken olarak sıklık (TF) terimini ve ters belge sıklığını (IDF) kullanan TF-IDF benzeri alma işlevleridir ve bu işlevler daha sonra sonuçları derecelendirmek için kullanılır. Kavramsal olarak klasiklere benzer olsa da BM25, kullanıcı araştırması tarafından ölçülen daha sezgisel eşleşmeler üreten olasılıksal bilgi alımına sahiptir.
BM25, kullanıcının ilgililik puanının eşlenen terimlerin terim sıklığıyla nasıl ölçeklendirileceğine karar vermesine izin verme gibi gelişmiş özelleştirme seçenekleri sunar. Daha fazla bilgi için bkz . Puanlama algoritmasını yapılandırma.
Not
Temmuz 2020'den önce oluşturulmuş bir arama hizmeti kullanıyorsanız, puanlama algoritması büyük olasılıkla dizin başına yükseltebileceğiniz önceki varsayılandır ClassicSimilarity. Ayrıntılar için bkz . Eski hizmetlerde BM25 puanlarını etkinleştirme.
Aşağıdaki video segmenti, Azure AI Search'te kullanılan genel kullanıma açık derecelendirme algoritmalarının açıklamasına hızlı bir şekilde iletmektedir. Daha fazla arka plan için videonun tamamını izleyebilirsiniz.
BM25 derecelendirmesi nasıl çalışır?
İlgi puanı, bir öğenin geçerli sorgu bağlamındaki ilgisine ilişkin bir gösterge olarak hizmet veren bir arama puanının (@search.score) hesaplanması anlamına gelir. Aralık ilişkisiz. Ancak, puan ne kadar yüksek olursa, öğe o kadar ilgili olur.
Arama puanı, dize girişinin istatistiksel özelliklerine ve sorgunun kendisine göre hesaplanır. Azure AI Search, arama terimleriyle (searchMode'a bağlı olarak bazıları veya tümü) eşleşen belgeler bulur ve arama teriminin birçok örneğini içeren belgeleri tercih eder. Terimin veri dizininde nadir, ancak belge içinde yaygın olması durumunda arama puanı daha da yüksek olur. Bilgi işlem ilgisine yönelik bu yaklaşımın temeli TF-IDF veya terim sıklığı ters belge sıklığı olarak bilinir.
Arama puanları bir sonuç kümesi boyunca tekrarlanabilir. Birden çok isabet aynı arama puanına sahip olduğunda, aynı puanlanan öğelerin sıralaması tanımlanmamıştır ve kararlı değildir. Sorguyu yeniden çalıştırdığınızda, özellikle de ücretsiz hizmeti veya birden çok çoğaltması olan faturalanabilir bir hizmeti kullanıyorsanız öğelerin konum değiştirdiğini görebilirsiniz. Aynı puana sahip iki öğe göz önünde bulundurulduğunda, önce birinin görünmesi garanti edilmez.
Eşitliği yinelenen puanlar arasında kesmek için, puana göre ilk sıraya bir $orderby yan tümcesi ekleyebilir ve sonra başka bir sıralanabilir alana göre sıralayabilirsiniz (örneğin, $orderby=search.score() desc,Rating desc). Daha fazla bilgi için bkz . $orderby.
Puanlama için yalnızca dizinde veya searchFields sorguda olarak searchable işaretlenmiş alanlar kullanılır. Yalnızca olarak işaretlenen retrievablealanlar veya sorguda select belirtilen alanlar, arama sonuçlarıyla birlikte arama puanıyla birlikte döndürülür.
Not
A @search.score = 1 , puanlanmamış veya derecelendirilmemiş bir sonuç kümesini gösterir. Puan tüm sonuçlarda tekdüzendir. Puanlanmamış sonuçlar, sorgu formu belirsiz arama, joker karakter veya regex sorguları ya da boş bir arama olduğunda (search=*bazen filtrenin eşleşme döndürmenin birincil aracı olduğu filtrelerle eşleştirildiğinde) oluşur.
Metin sonuçlarındaki puanlar
Sonuçlar derecelendirildiğinde, @search.score özellik sonuçları sıralamak için kullanılan değeri içerir.
Aşağıdaki tablo, her eşleşme, algoritma ve aralıkta döndürülen puanlama özelliğini tanımlar.
| Arama yöntemi | Parametre | Puanlama algoritması | Aralık |
|---|---|---|---|
| tam metin araması | @search.score |
Dizinde belirtilen parametreleri kullanan BM25 algoritması. | Sınırsız. |
Puan varyasyonu
Arama puanları, aynı sonuç kümesindeki diğer belgelere göre eşleşmenin gücünü yansıtan genel ilgi duygusunu ifade eder. Ancak puanlar her zaman bir sorgudan diğerine tutarlı değildir, bu nedenle sorgularla çalışırken arama belgelerinin sıralı olarak küçük tutarsızlıklar olduğunu fark edebilirsiniz. Bunun neden meydana gelebileceğine ilişkin birkaç açıklama vardır.
| Neden | Açıklama |
|---|---|
| Aynı puanlar | Birden çok belge aynı puana sahipse, bunlardan herhangi biri önce görünebilir. |
| Verilerin geçiciliği | Siz belge ekledikçe, değiştirdikçe veya sildikçe dizin içeriği değişir. Dizin güncelleştirmeleri zaman içinde işlendikçe terim sıklıkları değişir ve eşleşen belgelerin arama puanlarını etkiler. |
| Birden çok çoğaltma | Birden çok çoğaltma kullanan hizmetler için, her çoğaltmaya paralel olarak sorgular verilir. Arama puanını hesaplamak için kullanılan dizin istatistikleri, sonuçların sorgu yanıtında birleştirilmesi ve sıralanmasıyla çoğaltma başına temel alınarak hesaplanır. Çoğaltmalar çoğunlukla birbirinin aynalarıdır, ancak durum farklılıkları nedeniyle istatistikler farklılık gösterebilir. Örneğin, bir çoğaltma, istatistiklerine katkıda bulunan ve diğer çoğaltmaların dışında birleştirilen belgeleri silmiş olabilir. Genellikle, çoğaltma başına istatistiklerdeki farklar daha küçük dizinlerde daha belirgindir. Aşağıdaki bölümde bu koşul hakkında daha fazla bilgi sağlanmaktadır. |
Sorgu sonuçları üzerindeki parçalama efektleri
Parça, bir dizinin öbekleridir. Azure AI Search, bölümleri ekleme işlemini daha hızlı hale getirmek için (parçaları yeni arama birimlerine taşıyarak) dizini parçalara ayırır. Bir arama hizmetinde parça yönetimi bir uygulama ayrıntılarıdır ve yapılandırılamaz, ancak bir dizinin parçalandığını bilmek, sıralama ve otomatik tamamlama davranışlarındaki ara sıra anomalileri anlamanıza yardımcı olur:
Anomalileri derecelendirme: Arama puanları önce parça düzeyinde hesaplanır ve ardından tek bir sonuç kümesinde toplanır. Parça içeriğinin özelliklerine bağlı olarak, bir parçadan gelen eşleşmeler, diğer parçadaki eşleşmelerden daha yüksek sıralanabilir. Arama sonuçlarında sezgisel sıralamaların karşıt olduğunu fark ederseniz, bunun nedeni büyük olasılıkla parçalamanın etkileridir, özellikle dizinler küçükse. Tüm dizin genelinde puanları hesaplamayı seçerek bu derecelendirme anomalilerinden kaçınabilirsiniz, ancak bunu yaptığınızda bir performans cezası uygulanır.
Otomatik tamamlama anomalileri: Kısmen girilen bir terimin ilk birkaç karakterinde eşleşmelerin yapıldığı otomatik tamamlama sorguları, yazımda küçük sapmaları affeden benzer bir parametreyi kabul eder. Otomatik tamamlama için, belirsiz eşleştirme geçerli parça içindeki terimler ile kısıtlanır. Örneğin, bir parça "Microsoft" içeriyorsa ve kısmi bir "mikro" terimi girilirse, arama altyapısı bu parçadaki "Microsoft" ile eşleşir, ancak dizinin kalan bölümlerini tutan diğer parçalarda eşleşmez.
Aşağıdaki diyagramda çoğaltmalar, bölümler, parçalar ve arama birimleri arasındaki ilişki gösterilmektedir. İki çoğaltması ve iki bölümü olan bir hizmetteki dört arama birimi arasında tek bir dizinin nasıl yayılımının bir örneğini gösterir. Dört arama biriminin her biri, dizinin parçalarının yalnızca yarısını depolar. Sol sütundaki arama birimleri parçaların ilk yarısını depolar ve sağ sütundakiler ikinci bölümü içeren parçaların ikinci yarısını depolar. İki çoğaltma olduğundan, her dizin parçasının iki kopyası vardır. Üst satırdaki arama birimleri ilk çoğaltmayı içeren bir kopya depolarken, alt satırdakiler ikinci çoğaltmayı içeren başka bir kopya depolar.
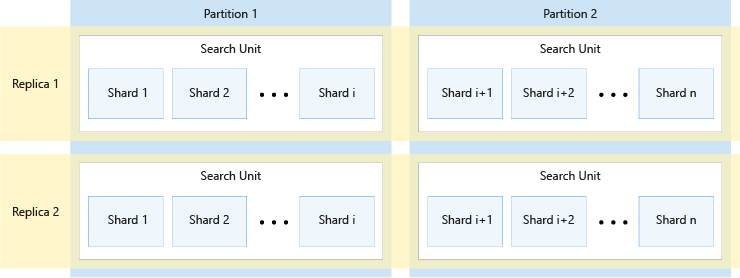
Yukarıdaki diyagram yalnızca bir örnektir. En fazla 36 toplam arama birimi olmak üzere birçok bölüm ve çoğaltma bileşimi mümkündür.
Not
Çoğaltma ve bölüm sayısı eşit olarak 12'ye ayrılır (özellikle, 1, 2, 3, 4, 6, 12). Azure AI Search, tüm bölümlere eşit bölümlere yayılabilmesi için her dizini 12 parçaya önceden böler. Örneğin, hizmetinizin üç bölümü varsa ve bir dizin oluşturursanız, her bölüm dizinin dört parçası içerir. Azure AI Search'ün bir dizini nasıl parçalandıracakları, gelecek sürümlerde değişikliğe tabi olan bir uygulama ayrıntısıdır. Sayı bugün 12 olsa da, gelecekte bu sayın her zaman 12 olmasını beklememelisiniz.
Puanlama istatistikleri ve yapışkan oturumlar
Ölçeklenebilirlik için Azure AI Search, her dizini bir parçalama işlemi aracılığıyla yatay olarak dağıtır ve bu da dizinin bölümlerinin fiziksel olarak ayrı olduğu anlamına gelir.
Varsayılan olarak, bir belgenin puanı bir parça içindeki verilerin istatistiksel özelliklerine göre hesaplanır. Bu yaklaşım genellikle büyük bir veri kolordusu için sorun oluşturmaz ve tüm parçalar genelindeki bilgilere göre puanı hesaplamak zorunda kalmaktan daha iyi performans sağlar. Bununla birlikte, bu performans iyileştirmesini kullanmak, çok benzer iki belgenin (veya hatta aynı belgelerin) farklı parçalar halinde olması durumunda farklı ilgi puanlarına sahip olmasına neden olabilir.
Puanı tüm parçalardaki istatistiksel özelliklere göre hesaplamayı tercih ediyorsanız, bunu sorgu parametresi olarak ekleyerek scoringStatistics=global (veya sorgu isteğinin gövde parametresi olarak ekleyerek"scoringStatistics": "global") yapabilirsiniz.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "<query string>",
"scoringStatistics": "global"
}
kullanmak scoringStatistics , aynı çoğaltmadaki tüm parçaların aynı sonuçları sağladığından emin olur. Bununla birlikte, her zaman dizininizdeki en son değişikliklerle güncelleştirildiğinden farklı çoğaltmalar birbirinden biraz farklı olabilir. Bazı senaryolarda, kullanıcılarınızın "sorgu oturumu" sırasında daha tutarlı sonuçlar elde etmelerini isteyebilirsiniz. Bu tür senaryolarda, sorgularınızın bir parçası olarak bir sessionId sağlayabilirsiniz. sessionId, benzersiz bir kullanıcı oturumuna başvurmak için oluşturduğunuz benzersiz bir dizedir.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2020-06-30
{
"search": "<query string>",
"sessionId": "<string>"
}
Aynı sessionId kullanıldığı sürece, aynı çoğaltmayı hedeflemek için en iyi çaba gösteriliyor ve kullanıcılarınızın göreceği sonuçların tutarlılığı artırılıyor.
Not
Aynı sessionId değerleri tekrar tekrar yeniden kullanma, isteklerin çoğaltmalar arasında yük dengelemesini etkileyebilir ve arama hizmetinin performansını olumsuz etkileyebilir. sessionId olarak kullanılan değer '_' karakteriyle başlayamaz.
İlgi düzeyini ayarlama
Azure AI Search'te BM25 algoritma parametrelerini yapılandırabilir, aramanın ilgi düzeyini ayarlayabilir ve şu mekanizmalar aracılığıyla arama puanlarını artırabilirsiniz:
| Yaklaşım | Uygulama | Açıklama |
|---|---|---|
| Puanlama algoritması yapılandırması | Arama dizini | |
| Puanlama modelleri | Arama dizini | İçerik özelliklerine göre bir eşleşmenin arama puanını artırmak için ölçütler sağlayın. Örneğin, eşleşmeleri gelir potansiyellerine göre artırmak, daha yeni öğeleri tanıtmak veya envanterde çok uzun süre bulunan öğeleri artırmak isteyebilirsiniz. Puanlama profili, ağırlıklı alanlar, işlevler ve parametrelerden oluşan dizin tanımının bir parçasıdır. Mevcut bir dizini, dizin yeniden derlemesi yapmadan puanlama profili değişiklikleriyle güncelleştirebilirsiniz. |
| Anlamsal derecelendirme | Sorgu isteği | Makine okuma kavramasını arama sonuçlarına uygulayarak daha anlamlı olarak ilgili sonuçları en üste yükseltme. |
| featuresMode parametresi | Sorgu isteği | Bu parametre çoğunlukla bir puanın paketini açmak için kullanılır, ancak özel puanlama çözümü sağlayan kodda için kullanılabilir. |
featuresMode parametresi (önizleme)
Arama Belgeleri istekleri, alan düzeyinde ilgi hakkında daha fazla ayrıntı sağlayabilen yeni bir özelliklermode parametresine sahiptir. @searchScore, belgenin tamamı için hesaplanırken (bu belgenin bu sorgu bağlamında ne kadar ilgili olduğu) özelliklerMode aracılığıyla, bir @search.features yapıda ifade edildiği gibi tek tek alanlar hakkında bilgi alabilirsiniz. Yapı, sorguda kullanılan tüm alanları (sorgudaki searchField'ler aracılığıyla belirli alanlar veya dizinde aranabilir olarak özniteliklendirilen tüm alanları) içerir. Her alan için aşağıdaki değerleri alırsınız:
- Alanda bulunan benzersiz belirteçlerin sayısı
- Benzerlik puanı veya sorgu terimine göre alanın içeriğinin ne kadar benzer olduğuna ilişkin bir ölçü
- Terim sıklığı veya sorgu teriminin alanda bulunma sayısı
"Açıklama" ve "başlık" alanlarını hedefleyen bir sorgu için, içeren @search.features bir yanıt şöyle görünebilir:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Bu veri noktalarını özel puanlama çözümlerinde kullanabilir veya aramayla ilgili sorunlarda hata ayıklamak için bu bilgileri kullanabilirsiniz.
Tam metin sorgu yanıtında dereceli sonuç sayısı
Varsayılan olarak, sayfalandırma kullanmıyorsanız, arama altyapısı tam metin araması için en yüksek 50 derecelendirme eşleşmesini döndürür. parametresini top kullanarak daha küçük veya daha fazla sayıda öğe döndürebilirsiniz (tek yanıtta en fazla 1000). Tam metin araması en fazla 1.000 eşleşme sınırına tabidir (bkz . API yanıt sınırları). 1.000 eşleşme bulunduktan sonra arama motoru artık daha fazlasını aramaz.
Daha fazla veya daha az sonuç döndürmek için , skipve nextdisk belleği parametrelerini topkullanın. Sayfalama, her mantıksal sayfadaki sonuç sayısını belirleme ve tam yükte gezinme yöntemidir. Daha fazla bilgi için bkz . Arama sonuçlarıyla çalışma.