Przyrostowe ładowanie danych z wielu tabel w programie SQL Server do usługi Azure SQL Database przy użyciu programu PowerShell
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz usługę Azure Data Factory z potokiem, który ładuje dane różnicowe z wielu tabel w bazie danych programu SQL Server do usługi Azure SQL Database.
Ten samouczek obejmuje następujące procedury:
- Przygotowanie źródłowych i docelowych magazynów danych
- Tworzenie fabryki danych.
- Utwórz własne środowisko Integration Runtime.
- Instalowanie środowiska Integration Runtime.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie, uruchamianie i monitorowanie potoku
- Przejrzyj wyniki.
- Dodawanie lub aktualizowanie danych w tabelach źródłowych.
- Ponowne uruchamianie i monitorowanie potoku.
- Przegląd wyników końcowych.
Omówienie
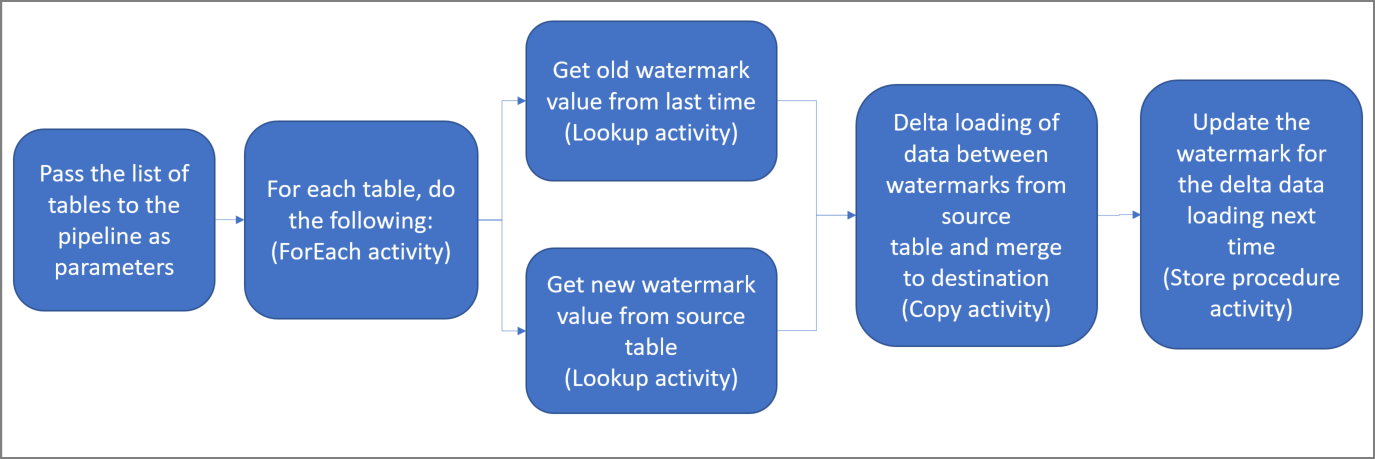
Poniżej przedstawiono ważne czynności związane z tworzeniem tego rozwiązania:
Wybierz kolumnę limitu.
Wybierz jedną kolumnę dla każdej tabeli w magazynie danych źródłowych, które można zidentyfikować nowe lub zaktualizowane rekordy dla każdego przebiegu. Zazwyczaj dane w tej wybranej kolumnie (na przykład last_modify_time lub ID) rosną wraz z tworzeniem i aktualizacją wierszy. Maksymalna wartość w tej kolumnie jest używana jako limit.
Przygotuj magazyn danych do przechowywania wartości limitu.
W tym samouczku wartość limitu jest przechowywana w bazie danych SQL.
Utwórz potok z następującymi działaniami:
Utwórz działanie ForEach służące do przeprowadzania iteracji po liście nazw tabel źródłowych przekazywanych jako parametr do potoku. Dla każdej tabeli źródłowej wywołuje ono następujące działania służące do wykonywania ładowania przyrostowego dla tej tabeli.
Utwórz dwa działania lookup. Użyj pierwszego działania Lookup do pobrania ostatniej wartości limitu. Użyj drugiego działania Lookup do pobrania nowej wartości limitu. Te wartości limitu są przekazywane do działania Copy.
Utwórz działanie Kopiuj, który kopiuje wiersze ze źródłowego magazynu danych z wartością kolumny limitu większej niż stara wartość limitu i mniejsza lub równa nowej wartości limitu. Następnie kopiuje dane różnicowe ze źródłowego magazynu danych do usługi Azure Blob Storage jako nowy plik.
Utwórz działanie StoredProcedure, które aktualizuje wartość limitu dla potoku przy następnym uruchomieniu.
Diagram ogólny rozwiązania wygląda następująco:
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- SQL Server. Baza danych programu SQL Server jest używana jako źródłowy magazyn danych w tym samouczku.
- Usługa Azure SQL Database. Baza danych w usłudze Azure SQL Database jest używana jako magazyn danych ujścia. Jeśli nie masz bazy danych SQL, zobacz Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
Tworzenie tabel źródłowych w bazie danych SQL Server
Otwórz program SQL Server Management Studio (SSMS) lub azure Data Studio i połącz się z bazą danych programu SQL Server.
W Eksploratorze serwera (SSMS) lub w okienku Połączenie ions (Azure Data Studio) kliknij prawym przyciskiem myszy bazę danych i wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych w celu utworzenia tabel o nazwach
customer_tableiproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
Tworzenie tabel docelowych w usłudze Azure SQL Database
Otwórz program SQL Server Management Studio (SSMS) lub azure Data Studio i połącz się z bazą danych programu SQL Server.
W Eksploratorze serwera (SSMS) lub w okienku Połączenie ions (Azure Data Studio) kliknij prawym przyciskiem myszy bazę danych i wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych w celu utworzenia tabel o nazwach
customer_tableiproject_table:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
Tworzenie innej tabeli w usłudze Azure SQL Database w celu przechowywania wysokiej wartości limitu
Uruchom następujące polecenie SQL względem bazy danych, aby utworzyć tabelę o nazwie
watermarktabledo przechowywania wartości limitu:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );Wstaw początkowe wartości limitu dla obu tabel źródłowych w tabeli wartości limitu.
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
Tworzenie procedury składowanej w usłudze Azure SQL Database
Uruchom następujące polecenie, aby utworzyć procedurę składowaną w bazie danych. Ta procedura składowana służy do aktualizowania wartość limitu po każdym uruchomieniu potoku.
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Tworzenie typów danych i dodatkowych procedur składowanych w usłudze Azure SQL Database
Uruchom następujące zapytanie, aby utworzyć dwie procedury składowane i dwa typy danych w bazie danych. Służą one do scalania danych z tabel źródłowych w tabelach docelowych.
Aby ułatwić rozpoczęcie podróży, użyjemy bezpośrednio tych procedur składowanych przekazujących dane różnicowe za pośrednictwem zmiennej tabeli, a następnie scalimy je z magazynem docelowym. Należy zachować ostrożność, że w zmiennej tabeli nie będzie przechowywana "duża" liczba wierszy różnicowych (ponad 100).
Jeśli musisz scalić dużą liczbę wierszy różnicowych z magazynem docelowym, zalecamy użycie działania kopiowania w celu skopiowania wszystkich danych różnicowych do tymczasowej tabeli przejściowej w magazynie docelowym, a następnie skompilowanie własnej procedury składowanej bez użycia zmiennej tabeli tabeli w celu scalenia ich z tabeli "przejściowej" do tabeli "końcowej".
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
Zainstaluj najnowsze moduły programu Azure PowerShell, wykonując instrukcje podane w temacie Instalowanie i konfigurowanie programu Azure PowerShell.
Tworzenie fabryki danych
Zdefiniuj zmienną nazwy grupy zasobów, której użyjesz później w poleceniach programu PowerShell. Skopiuj poniższy tekst polecenia do programu PowerShell, podaj nazwę grupy zasobów platformy Azure w podwójnych cudzysłowach, a następnie uruchom polecenie. Może to być na przykład
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Jeśli grupa zasobów już istnieje, jej zastąpienie może być niewskazane. Przypisz inną wartość do zmiennej
$resourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną lokalizacji fabryki danych.
$location = "East US"Aby utworzyć grupę zasobów platformy Azure, uruchom następujące polecenie:
New-AzResourceGroup $resourceGroupName $locationJeśli grupa zasobów już istnieje, jej zastąpienie może być niewskazane. Przypisz inną wartość do zmiennej
$resourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną nazwy fabryki danych.
Ważne
Zaktualizuj nazwę fabryki danych, aby była unikatowa w skali globalnej. Może to być na przykład ADFIncMultiCopyTutorialFactorySP1127.
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";Aby utworzyć fabrykę danych, uruchom następujące polecenie cmdlet Set-AzDataFactoryV2 :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Należy uwzględnić następujące informacje:
Nazwa fabryki danych musi być globalnie unikatowa. Jeśli zostanie wyświetlony następujący błąd, zmień nazwę i spróbuj ponownie:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się na platformie Azure musi być członkiem roli współautora lub właściciela albo administratorem subskrypcji platformy Azure.
Aby uzyskać listę regionów platformy Azure, w których obecnie jest dostępna usługa Data Factory, wybierz dane regiony na poniższej stronie, a następnie rozwiń węzeł Analiza, aby zlokalizować pozycję Data Factory: Produkty dostępne według regionu. Magazyny danych (Azure Storage, SQL Database, SQL Managed Instance itd.) i obliczenia (Azure HDInsight itp.) używane przez fabrykę danych mogą znajdować się w innych regionach.
Tworzenie własnego środowiska Integration Runtime
W tej sekcji utworzysz własne środowisko Integration Runtime i skojarzysz je z maszyną lokalną za pomocą bazy danych programu SQL Server. Własne środowisko Integration Runtime to składnik, który kopiuje dane z programu SQL Server na maszynie do usługi Azure SQL Database.
Utwórz zmienną dla nazwy środowiska Integration Runtime. Użyj unikatowej nazwy i zanotuj ją. Będziesz jej używać w dalszej części tego samouczka.
$integrationRuntimeName = "ADFTutorialIR"Utwórz własne środowisko Integration Runtime.
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupNameOto przykładowe dane wyjściowe:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIRUruchom następujące polecenie, aby pobrać stan utworzonego środowiska Integration Runtime. Upewnij się, że właściwość State ma ustawioną wartość NeedRegistration.
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusOto przykładowe dane wyjściowe:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>Uruchom następujące polecenie, aby pobrać klucze uwierzytelniania używane do zarejestrowania własnego środowiska Integration Runtime za pomocą usługi Azure Data Factory w chmurze:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonOto przykładowe dane wyjściowe:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }Skopiuj jeden z kluczy (pomijając cudzysłowy) używanych do rejestracji własnego środowiska Integration Runtime, które zainstalujesz na swojej maszynie w kolejnych krokach.
Instalowanie narzędzia Integration Runtime
Jeśli środowisko Integration Runtime jest już zainstalowane na maszynie, odinstaluj je za pomocą apletu Dodaj lub usuń programy.
Pobierz środowisko Integration Runtime (Self-hosted) na lokalną maszynę z systemem Windows. Uruchom instalację.
Na stronie powitalnej instalatora środowiska Microsoft Integration Runtime wybierz przycisk Dalej.
Na stronie Umowa Licencyjna Użytkownika Oprogramowania zaakceptuj warunki i umowę licencyjną, a następnie wybierz przycisk Dalej.
Na stronie Folder docelowy wybierz pozycję Dalej.
Na stronie Gotowe do zainstalowania środowiska Microsoft Integration Runtime wybierz pozycję Zainstaluj.
N astronie zakończenia pracy z Kreatorem instalacji środowiska Microsoft Integration Runtime wybierz pozycję Zakończ.
Na stronie Rejestrowanie środowiska Integration Runtime (Self-hosted) wklej klucz zapisany w poprzedniej sekcji i wybierz pozycję Zarejestruj.
Na stronie Nowy węzeł Integration Runtime (self-hosted) wybierz pozycję Zakończ.
Gdy własne środowisko Integration Runtime zostanie pomyślnie zarejestrowane, zostanie wyświetlony następujący komunikat:
Na stronie Rejestrowanie produktu Integration Runtime (Self-hosted) kliknij pozycję Uruchom program Configuration Manager.
Gdy węzeł zostanie połączony z usługą w chmurze, zostanie wyświetlona następująca strona:
Teraz przetestuj łączność z bazą danych programu SQL Server.
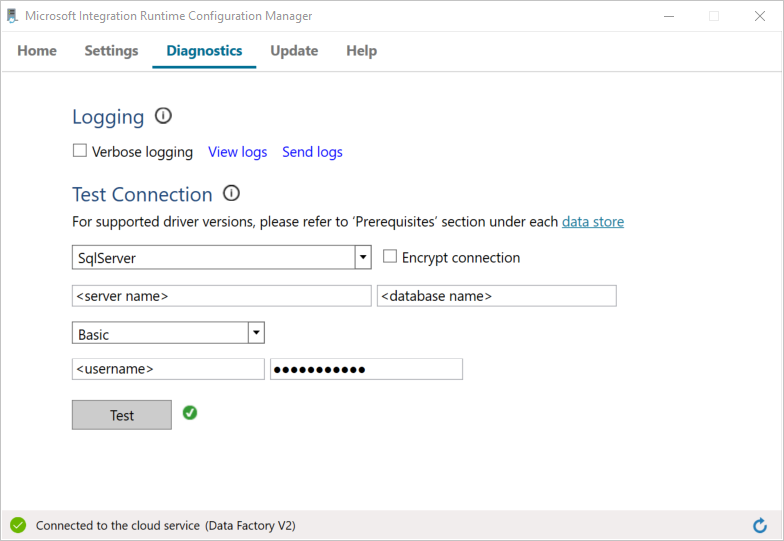
a. Na stronie programu Configuration Manager przejdź na kartę Diagnostyka.
b. Wybierz typ źródła danych SqlServer.
c. Wprowadź nazwę serwera.
d. Wprowadź nazwę bazy danych.
e. Wybierz tryb uwierzytelniania.
f. Wprowadź nazwę użytkownika.
g. Wprowadź hasło skojarzone z nazwą użytkownika.
h. Wybierz przycisk Testuj, aby upewnić się, że środowisko Integration Runtime może połączyć się z wystąpieniem programu SQL Server. Jeśli połączenie zostanie pomyślnie nawiązane, zostanie wyświetlony zielony znacznik wyboru. Jeśli nawiązywanie połączenia nie powiedzie się, zostanie wyświetlony komunikat o błędzie. Rozwiąż wszelkie problemy i upewnij się, że środowisko Integration Runtime może połączyć się z programem SQL Server.
Uwaga
Zapisz wartości: typ uwierzytelniania, serwer, baza danych, użytkownik i hasło. Będziesz ich używać w dalszej części tego samouczka.
Tworzenie połączonych usług
Połączone usługi tworzy się w fabryce danych w celu połączenia magazynów danych i usług obliczeniowych z fabryką danych. W tej sekcji utworzysz połączone usługi z bazą danych programu SQL Server i bazą danych w usłudze Azure SQL Database.
Tworzenie usługi połączonej z serwerem SQL Server
W tym kroku połączysz bazę danych programu SQL Server z fabryką danych.
Utwórz plik JSON o nazwie SqlServerLinkedService.json w folderze C:\ADFTutorials\IncCopyMultiTableTutorial (utwórz foldery lokalne, jeśli jeszcze nie istnieją) z następującą zawartością. Wybierz właściwą sekcję na podstawie uwierzytelniania używanego do nawiązywania połączenia z programem SQL Server.
Ważne
Wybierz właściwą sekcję na podstawie uwierzytelniania używanego do nawiązywania połączenia z programem SQL Server.
Jeśli używasz uwierzytelniania SQL, skopiuj następującą definicję JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Jeśli używasz uwierzytelniania systemu Windows, skopiuj następującą definicję JSON:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Ważne
- Wybierz właściwą sekcję na podstawie uwierzytelniania używanego do nawiązywania połączenia z programem SQL Server.
- Zastąp <nazwę środowiska Integration Runtime nazwą> środowiska Integration Runtime.
- Przed zapisaniem pliku zastąp wartość <servername, <databasename>>, <username> i <password> wartościami bazy danych programu SQL Server.
- Jeśli musisz użyć znaku ukośnika (
\) w nazwie konta użytkownika lub nazwie serwera, użyj znaku ucieczki (\). Może to być na przykładmydomain\\myuser.
W programie PowerShell uruchom następujące polecenie cmdlet, aby przełączyć się do folderu C:\ADFTutorials\IncCopyMultiTableTutorial.
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'Uruchom polecenie cmdlet Set-AzDataFactoryV2LinkedService, aby utworzyć połączoną usługę AzureStorageLinkedService. W poniższym przykładzie przekazujesz wartości dla parametrów ResourceGroupName i DataFactoryName:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
Tworzenie połączonej usługi SQL Database
Utwórz plik JSON o nazwie AzureSQLDatabaseLinkedService.json w folderze C:\ADFTutorials\IncCopyMultiTableTutorial o następującej zawartości. (Utwórz folder ADF, jeśli jeszcze nie istnieje). Przed zapisaniem pliku zastąp <wartości servername>, <<database name>, user name> i <password> nazwą bazy danych programu SQL Server, nazwą bazy danych, nazwą użytkownika i hasłem.
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.windows.net;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }W programie PowerShell uruchom polecenie cmdlet Set-AzDataFactoryV2LinkedService , aby utworzyć połączoną usługę AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Tworzenie zestawów danych
W tym kroku utworzysz zestawy danych reprezentujące źródło danych, docelową lokalizację danych i lokalizację, w której będzie przechowywana wartość limitu.
Tworzenie zestawu danych źródłowych
Utwórz plik JSON o nazwie SourceDataset.json w tym samym folderze o następującej zawartości:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }Działanie Copy w potoku korzysta z zapytania SQL do załadowania danych, a nie całej tabeli.
Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych SourceDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Tworzenie ujścia zestawu danych
Utwórz plik JSON o nazwie SinkDataset.json w tym samym folderze o następującej zawartości. Element tableName jest dynamicznie ustawiany przez potok w czasie wykonywania. Działanie ForEach w potoku przeprowadza iterację po liście nazw i przekazuje nazwę tabeli do tego zestawu danych w każdej iteracji.
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych SinkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Tworzenie zestawu danych dla limitu
W tym kroku utworzysz zestaw danych do przechowywania wartości górnego limitu.
Utwórz plik JSON o nazwie WatermarkDataset.json w tym samym folderze o następującej zawartości:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych WatermarkDataset.
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Tworzenie potoku
Potok przyjmuje listę nazw tabel jako parametr. Działanie ForEach iteruje za pośrednictwem listy nazw tabel i wykonuje następujące operacje:
Użyj działania Lookup, aby pobrać starą wartość limitu (początkową wartość lub wartość użytą w ostatniej iteracji).
Użyj działania Lookup, aby pobrać nową wartość limitu (maksymalną wartość kolumny limitu w tabeli źródłowej).
Użyj działanie Kopiuj, aby skopiować dane między tymi dwiema wartościami limitu z źródłowej bazy danych do docelowej bazy danych.
Użyj działania StoredProcedure, aby zaktualizować starą wartość limitu do użycia w pierwszym kroku następnej iteracji.
Tworzenie potoku
Utwórz plik JSON o nazwie IncrementalCopyPipeline.json w tym samym folderze o następującej zawartości:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Pipeline, aby utworzyć potok IncrementalCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Oto przykładowe dane wyjściowe:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
Uruchamianie potoku
Utwórz plik parametrów o nazwie Parameters.json w tym samym folderze o następującej zawartości:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }Uruchom potok IncrementalCopyPipeline przy użyciu polecenia cmdlet Invoke-AzDataFactoryV2Pipeline . Zastąp symbole zastępcze własną nazwą grupy zasobów i fabryki danych.
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
Monitor the pipeline (Monitorowanie potoku)
Zaloguj się w witrynie Azure Portal.
Wybierz pozycję Wszystkie usługi, przeprowadź wyszukiwanie za pomocą słowa kluczowego Fabryki danych, a następnie wybierz pozycję Fabryki danych.
Wyszukaj używaną fabrykę danych na liście fabryk danych, a następnie wybierz ją, aby otworzyć stronę Fabryka danych.
Na stronie Fabryka danych wybierz pozycję Otwórz na kafelku Otwórz usługę Azure Data Factory Studio, aby uruchomić usługę Azure Data Factory na osobnej karcie.
Na stronie głównej usługi Azure Data Factory wybierz pozycję Monitoruj po lewej stronie.
Wyświetlone zostaną wszystkie uruchomienia potoków wraz z ich stanami. Zwróć uwagę, że w poniższym przykładzie stan uruchomienia potoku to Powodzenie. Wybierz link w kolumnie Parametry, aby sprawdzić parametry przekazywane do potoku. Jeśli wystąpił błąd, w kolumnie Błąd zostanie wyświetlony link.

Po wybraniu linku w kolumnie Akcje zobaczysz wszystkie uruchomienia działań dla potoku.
Aby wrócić do widoku Uruchomienia potoku, wybierz pozycję Wszystkie uruchomienia potoku.
Sprawdzanie wyników
W programu SQL Server Management Studio uruchom następujące zapytania względem docelowej bazy danych Azure SQL Database, aby sprawdzić, czy dane zostały skopiowane z tabel źródłowych do tabel docelowych:
Zapytanie
select * from customer_table
Wyjście
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Zapytanie
select * from project_table
Wyjście
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
Zapytanie
select * from watermarktable
Wyjście
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
Należy zauważyć, że wartości limitu dla obu tabel zostały zaktualizowane.
Dodawanie większej ilości danych do tabel źródłowych
Uruchom następujące zapytanie względem źródłowej bazy danych programu SQL Server, aby zaktualizować istniejący wiersz w tabeli customer_table. Wstaw nowy wiersz do tabeli project_table.
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
Ponowne uruchamianie potoku
Teraz ponownie uruchom proces, wykonując następujące polecenie programu PowerShell:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"Monitoruj uruchomienia potoków, postępując zgodnie z instrukcjami w sekcji Monitorowanie potoku. Gdy stan potoku to W toku, w obszarze Akcje zostanie wyświetlony kolejny link akcji, aby anulować uruchomienie potoku.
Wybierz pozycję Odśwież, aby odświeżać listę do momentu, aż uruchomienie potoku zakończy się pomyślnie.
Opcjonalnie wybierz link Wyświetl uruchomienia działań w kolumnie Akcje, aby wyświetlić wszystkie uruchomienia działań skojarzone z tym uruchomieniem potoku.
Przegląd wyników końcowych
W programie SQL Server Management Studio uruchom następujące zapytania względem docelowej bazy danych, aby sprawdzić, czy zaktualizowane lub nowe dane zostały skopiowane z tabel źródłowych do tabel docelowych.
Zapytanie
select * from customer_table
Wyjście
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
Zwróć uwagę na nowe wartości właściwości Name i LastModifytime dla identyfikatora PersonID numeru 3.
Zapytanie
select * from project_table
Wyjście
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
Zwróć uwagę, że do tabeli project_table dodano pozycję NewProject.
Zapytanie
select * from watermarktable
Wyjście
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
Należy zauważyć, że wartości limitu dla obu tabel zostały zaktualizowane.
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Przygotowanie źródłowych i docelowych magazynów danych
- Tworzenie fabryki danych.
- Tworzenie własnego środowiska Integration Runtime.
- Instalowanie środowiska Integration Runtime.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i limitu.
- Tworzenie, uruchamianie i monitorowanie potoku
- Przejrzyj wyniki.
- Dodawanie lub aktualizowanie danych w tabelach źródłowych.
- Ponowne uruchamianie i monitorowanie potoku.
- Przegląd wyników końcowych.
Przejdź do następującego samouczka, aby dowiedzieć się więcej o przekształcaniu danych za pomocą klastra Spark na platformie Azure: