Przyrostowe ładowanie danych z usługi Azure SQL Database do usługi Azure Blob Storage przy użyciu informacji śledzenia zmian przy użyciu programu PowerShell
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku utworzysz fabrykę danych Platformy Azure z potokiem, który ładuje dane różnicowe na podstawie informacji śledzenia zmian w źródłowej bazie danych w usłudze Azure SQL Database do magazynu obiektów blob platformy Azure.
Ten samouczek obejmuje następujące procedury:
- Przygotowywanie magazynu danych źródłowych
- Tworzenie fabryki danych.
- Tworzenie połączonych usług.
- Tworzenie zestawów danych źródła, ujścia i śledzenia zmian.
- Tworzenie, uruchamianie i monitorowanie potoku pełnego kopiowania
- Dodawanie lub aktualizowanie danych w tabeli źródłowej
- Tworzenie, uruchamianie i monitorowanie potoku kopiowania przyrostowego
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Zobacz Instalowanie programu Azure PowerShell, aby rozpocząć. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Omówienie
W rozwiązaniu integracji danych przyrostowe ładowanie danych po początkowych operacjach ładowania danych to powszechnie używany scenariusz. W niektórych przypadkach dane zmienione w określonym czasie w magazynie danych źródła można łatwo podzielić (na przykład na podstawie właściwości LastModifyTime i CreationTime). W niektórych przypadkach nie można jednak w jednoznaczny sposób zidentyfikować danych różnicowych pochodzących z ostatniej operacji przetwarzania danych. Technologia Change Tracking obsługiwana przez magazyny danych, takie jak baza danych Azure SQL Database i serwer SQL Server, może służyć do identyfikowania danych różnicowych. W tym samouczku opisano sposób używania usługi Azure Data Factory do pracy z technologią Change Tracking w bazie danych SQL w celu przyrostowego ładowania danych różnicowych z bazy danych Azure SQL Database do magazynu Azure Blob Storage. Aby uzyskać bardziej konkretne informacje na temat technologii Change Tracking w bazie danych SQL, zobacz Technologia Change Tracking w programie SQL Server.
Kompletny przepływ pracy
Poniżej przedstawiono kroki kompleksowego przepływu pracy służące do przyrostowego ładowania danych przy użyciu technologii Change Tracking.
Uwaga
Technologia Change Tracking jest obsługiwana zarówno przez bazę danych Azure SQL Database, jak i serwer SQL Server. W tym samouczku baza danych Azure SQL Database jest używana jako magazyn danych źródłowych. Możesz również użyć wystąpienia programu SQL Server.
- Początkowe ładowanie danych historycznych (uruchom raz):
- Włącz technologię Change Tracking w źródłowej bazie danych w usłudze Azure SQL Database.
- Pobierz początkową wartość SYS_CHANGE_VERSION w bazie danych jako punkt odniesienia w celu przechwycenia zmienionych danych.
- Załaduj pełne dane ze źródłowej bazy danych do usługi Azure Blob Storage.
- Przyrostowe ładowanie danych różnicowych zgodnie z harmonogramem (jest uruchamiane okresowo po początkowym załadowaniu danych):
- Pobierz starą i nową wartość parametru SYS_CHANGE_VERSION.
- Załaduj dane różnicowe, łącząc klucze podstawowe zmienionych wierszy (między dwiema wartościami parametru SYS_CHANGE_VERSION) z tabeli sys.change_tracking_tables z danymi w tabeli źródłowej, a następnie przenieś dane różnicowe do lokalizacji docelowej.
- Zaktualizuj wartość parametru SYS_CHANGE_VERSION na potrzeby następnego ładowania danych różnicowych.
Rozwiązanie ogólne
W tym samouczku utworzysz dwa potoki, za pomocą których zostaną wykonane następujące dwie operacje:
Ładowanie początkowe: utworzysz potok z działaniem kopiowania, które kopiuje wszystkie dane z magazynu danych źródłowych (baza danych Azure SQL Database) do docelowego magazynu danych (magazyn Azure Blob Storage).

Ładowanie przyrostowe: utworzysz potok z następującymi działaniami, który będzie okresowo uruchamiany.
- Utwórz dwa działania wyszukiwania, aby pobrać starą i nową wartość parametru SYS_CHANGE_VERSION z bazy danych Azure SQL Database i przekazać ją do działania kopiowania.
- Utwórz jedno działanie kopiowania, aby skopiować wstawione, zaktualizowane lub usunięte dane między dwiema wartościami parametru SYS_CHANGE_VERSION z bazy danych Azure SQL Database do magazynu Azure Blob Storage.
- Utwórz jedno działanie procedury składowanej, aby zaktualizować wartość parametru SYS_CHANGE_VERSION na potrzeby następnego uruchomienia potoku.

Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Azure PowerShell. Zainstaluj najnowsze moduły programu Azure PowerShell, wykonując instrukcje podane w temacie Instalowanie i konfigurowanie programu Azure PowerShell.
- Usługa Azure SQL Database. Baza danych jest używana jako magazyn danych źródłowych. Jeśli nie masz bazy danych w usłudze Azure SQL Database, zobacz artykuł Tworzenie bazy danych w usłudze Azure SQL Database , aby uzyskać instrukcje tworzenia bazy danych.
- Konto usługi Azure Storage. Magazyn obiektów blob jest używany jako magazyn danych źródłowych. Jeśli nie masz konta usługi Azure Storage, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu. Utwórz kontener o nazwie adftutorial.
Tworzenie tabeli źródła danych w bazie danych
Uruchom program SQL Server Management Studio i połącz się z usługą SQL Database.
W Eksploratorze serwera kliknij prawym przyciskiem używaną bazę danych, a następnie wybierz pozycję Nowe zapytanie.
Uruchom następujące polecenie SQL względem bazy danych, aby utworzyć tabelę o nazwie
data_source_tablejako magazyn źródeł danych.create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Włącz mechanizm Change Tracking w bazie danych i tabeli źródłowej (data_source_table), uruchamiając następujące zapytanie SQL:
Uwaga
- Zastąp <nazwę bazy danych nazwą> bazy danych, która ma data_source_table.
- W bieżącym przykładzie zmienione dane są przechowywane przez dwa dni. W przypadku ładowania zmienionych danych nie rzadziej niż co trzy dni niektóre zmienione dane nie zostaną uwzględnione. Jednym rozwiązaniem jest zmiana wartości parametru CHANGE_RETENTION na większą. Alternatywnie należy zapewnić, że okres ładowania zmienionych danych będzie wynosił maksymalnie dwa dni. Aby uzyskać więcej informacji, zobacz Włącz śledzenie zmian dla bazy danych zmian
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)Utwórz nową tabelę i ustaw wartość parametru ChangeTracking_version na wartość domyślną, uruchamiając następujące zapytanie:
create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Uwaga
Jeśli dane nie ulegną zmianie po włączeniu śledzenia zmian dla bazy danych SQL Database, wartość wersji śledzenia zmian to 0.
Uruchom następujące zapytanie, aby utworzyć procedurę składowaną w bazie danych. Potok wywołuje tę procedurę składowaną w celu zaktualizowania wersji śledzenia zmian w tabeli utworzonej w poprzednim kroku.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Azure PowerShell
Zainstaluj najnowsze moduły programu Azure PowerShell, wykonując instrukcje podane w temacie Instalowanie i konfigurowanie programu Azure PowerShell.
Tworzenie fabryki danych
Zdefiniuj zmienną nazwy grupy zasobów, której użyjesz później w poleceniach programu PowerShell. Skopiuj poniższy tekst polecenia do programu PowerShell, podaj nazwę grupy zasobów platformy Azure w podwójnych cudzysłowach, a następnie uruchom polecenie. Na przykład:
"adfrg".$resourceGroupName = "ADFTutorialResourceGroup";Jeśli grupa zasobów już istnieje, możesz zrezygnować z jej zastąpienia. Przypisz inną wartość do zmiennej
$resourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną lokalizacji fabryki danych:
$location = "East US"Aby utworzyć grupę zasobów platformy Azure, uruchom następujące polecenie:
New-AzResourceGroup $resourceGroupName $locationJeśli grupa zasobów już istnieje, możesz zrezygnować z jej zastąpienia. Przypisz inną wartość do zmiennej
$resourceGroupNamei ponownie uruchom polecenie.Zdefiniuj zmienną nazwy fabryki danych.
Ważne
Zaktualizuj nazwę fabryki danych, aby była unikatowa w skali globalnej,
$dataFactoryName = "IncCopyChgTrackingDF";Aby utworzyć fabrykę danych, uruchom następujące polecenie cmdlet Set-AzDataFactoryV2 :
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Należy uwzględnić następujące informacje:
Nazwa fabryki danych platformy Azure musi być globalnie unikatowa. Jeśli zostanie wyświetlony następujący błąd, zmień nazwę i spróbuj ponownie.
The specified Data Factory name 'ADFIncCopyChangeTrackingTestFactory' is already in use. Data Factory names must be globally unique.Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się na platformie Azure musi być członkiem roli współautora lub właściciela albo administratorem subskrypcji platformy Azure.
Aby uzyskać listę regionów platformy Azure, w których obecnie jest dostępna usługa Data Factory, wybierz dane regiony na poniższej stronie, a następnie rozwiń węzeł Analiza, aby zlokalizować pozycję Data Factory: Produkty dostępne według regionu. Magazyny danych (Azure Storage, Azure SQL Database itp.) i jednostki obliczeniowe (HDInsight itp.) używane przez fabrykę danych mogą mieścić się w innych regionach.
Tworzenie połączonych usług
Połączone usługi tworzy się w fabryce danych w celu połączenia magazynów danych i usług obliczeniowych z fabryką danych. W tej sekcji utworzysz połączone usługi z kontem usługi Azure Storage i bazą danych w usłudze Azure SQL Database.
Utwórz połączoną usługę Azure Storage.
W tym kroku opisano łączenie konta usługi Azure Storage z fabryką danych.
Utwórz plik JSON o nazwie AzureStorageLinkedService.json w folderze C:\ADFTutorials\IncCopyChangeTrackingTutorial o następującej zawartości: (utwórz folder, jeśli jeszcze nie istnieje). Przed zapisaniem pliku zastąp
<accountName>ciąg ,<accountKey>nazwą i kluczem konta usługi Azure Storage.{ "name": "AzureStorageLinkedService", "properties": { "type": "AzureStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>" } } }W programie Azure PowerShell przejdź do folderu C:\ADFTutorials\IncCopyChangeTrackingTutorial .
Uruchom polecenie cmdlet Set-AzDataFactoryV2LinkedService, aby utworzyć połączoną usługę: AzureStorageLinkedService. W poniższym przykładzie przekazujesz wartości dla parametrów ResourceGroupName i DataFactoryName.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureStorageLinkedService
Utwórz połączoną usługę Azure SQL Database.
W tym kroku połączysz bazę danych z fabryką danych.
Utwórz plik JSON o nazwie AzureSQLDatabaseLinkedService.json w folderze C:\ADFTutorials\IncCopyChangeTrackingTutorial o następującej zawartości: Zastąp <nazwę> bazy danych serwera><, <identyfikator> użytkownika i <hasło> nazwą serwera, nazwą bazy danych, identyfikatorem użytkownika i hasłem przed zapisaniem pliku.
{ "name": "AzureSQLDatabaseLinkedService", "properties": { "type": "AzureSqlDatabase", "typeProperties": { "connectionString": "Server = tcp:<server>.database.windows.net,1433;Initial Catalog=<database name>; Persist Security Info=False; User ID=<user name>; Password=<password>; MultipleActiveResultSets = False; Encrypt = True; TrustServerCertificate = False; Connection Timeout = 30;" } } }W programie Azure PowerShell uruchom polecenie cmdlet Set-AzDataFactoryV2LinkedService , aby utworzyć połączoną usługę: AzureSQLDatabaseLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"Oto przykładowe dane wyjściowe:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
Tworzenie zestawów danych
W tym kroku utworzysz zestawy danych reprezentujące źródło danych, docelową lokalizację danych i lokalizację, w której będzie przechowywana wartość parametru SYS_CHANGE_VERSION.
Tworzenie zestawu danych źródłowych
W tym kroku utworzysz zestaw danych reprezentujący źródło danych.
Utwórz plik JSON o nazwie SourceDataset.json w tym samym folderze, o następującej zawartości:
{ "name": "SourceDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "data_source_table" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych: SourceDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : SourceDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Tworzenie ujścia zestawu danych
W tym kroku utworzysz zestaw danych reprezentujący dane skopiowane z magazynu danych źródłowych.
Utwórz plik JSON o nazwie SinkDataset.json w tym samym folderze, o następującej zawartości:
{ "name": "SinkDataset", "properties": { "type": "AzureBlob", "typeProperties": { "folderPath": "adftutorial/incchgtracking", "fileName": "@CONCAT('Incremental-', pipeline().RunId, '.txt')", "format": { "type": "TextFormat" } }, "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" } } }Jako jedno z wymagań wstępnych w magazynie Azure Blob Storage zostanie utworzony kontener adftutorial. Utwórz kontener, jeśli nie istnieje, lub zmień nazwę istniejącego kontenera. W tym samouczku nazwa pliku wyjściowego jest generowana dynamicznie przy użyciu wyrażenia: @CONCAT("Incremental-", pipeline(). RunId, '.txt').
Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych: SinkDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : SinkDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobDataset
Tworzenie zestawu danych śledzenia zmian
W tym kroku utworzysz zestaw danych służący do przechowywania wartości wersji śledzenia zmian.
Utwórz plik JSON o nazwie ChangeTrackingDataset.json w tym samym folderze o następującej zawartości:
{ "name": " ChangeTrackingDataset", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "table_store_ChangeTracking_version" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }Możesz utworzyć tabelę table_store_ChangeTracking_version jako część wymagań wstępnych.
Uruchom polecenie cmdlet Set-AzDataFactoryV2Dataset, aby utworzyć zestaw danych: ChangeTrackingDataset
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "ChangeTrackingDataset" -File ".\ChangeTrackingDataset.json"Oto przykładowe dane wyjściowe polecenia cmdlet:
DatasetName : ChangeTrackingDataset ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
Tworzenie potoku na potrzeby pełnego kopiowania
W tym kroku utworzysz potok z działaniem kopiowania, które kopiuje wszystkie dane z magazynu danych źródłowych (baza danych Azure SQL Database) do docelowego magazynu danych (magazyn Azure Blob Storage).
Utwórz plik JSON FullCopyPipeline.json w tym samym folderze o następującej zawartości:
{ "name": "FullCopyPipeline", "properties": { "activities": [{ "name": "FullCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource" }, "sink": { "type": "BlobSink" } }, "inputs": [{ "referenceName": "SourceDataset", "type": "DatasetReference" }], "outputs": [{ "referenceName": "SinkDataset", "type": "DatasetReference" }] }] } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Pipeline, aby utworzyć potok: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "FullCopyPipeline" -File ".\FullCopyPipeline.json"Oto przykładowe dane wyjściowe:
PipelineName : FullCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {FullCopyActivity} Parameters :
Uruchamianie potoku pełnego kopiowania
Uruchom potok: FullCopyPipeline przy użyciu polecenia cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "FullCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorowanie potoku pełnego kopiowania
Zaloguj się do witryny Azure Portal.
Kliknij pozycję Wszystkie usługi, przeprowadź wyszukiwanie za pomocą słowa kluczowego
data factories, a następnie wybierz pozycję Fabryki danych.
Wyszukaj używaną fabrykę danych na liście fabryk danych, a następnie wybierz ją, aby uruchomić stronę Fabryka danych.
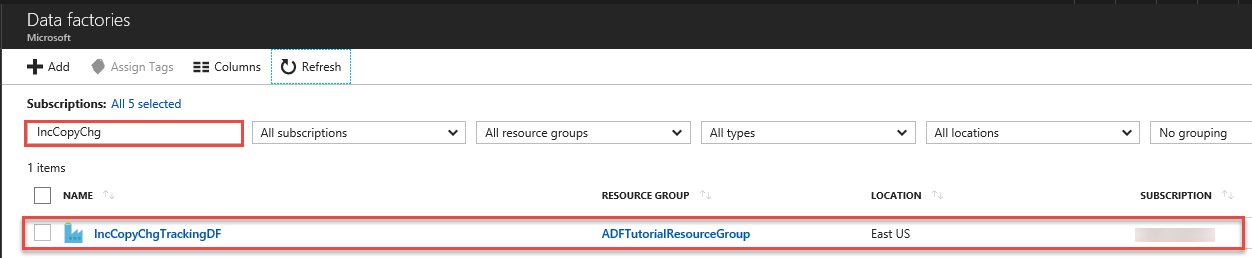
Na stronie fabryki danych kliknij kafelek Monitorowanie i zarządzanie.
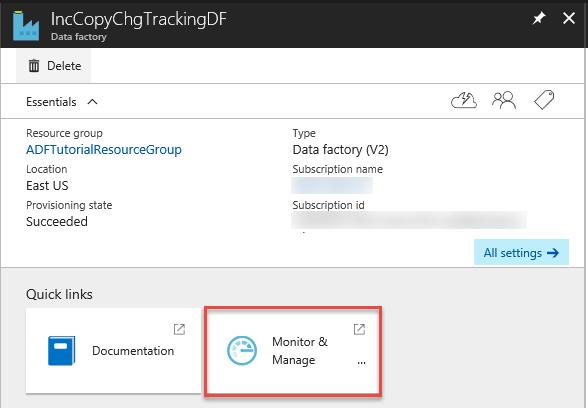
Aplikacja Integracja danych zostanie uruchomiona na osobnej karcie. Zobaczysz wszystkie uruchomienia potoku i ich stany. Zwróć uwagę, że w poniższym przykładzie stan uruchomienia potoku to Powodzenie. Klikając link w kolumnie Parametry, można sprawdzić parametry przekazywane do potoku. Jeśli wystąpił błąd, w kolumnie Błąd zostanie wyświetlony link. Kliknij link w kolumnie Akcje.
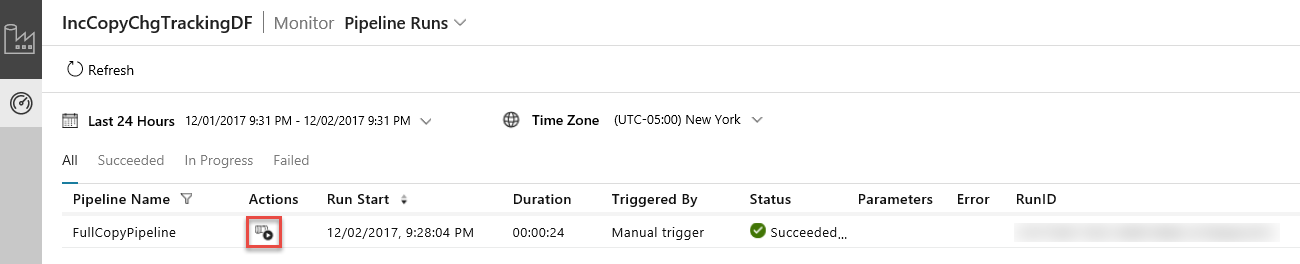
Po kliknięciu linków w kolumnie Akcje zostanie wyświetlona następująca strona, na której będą się znajdować wszystkie uruchomienia działań dla potoku.
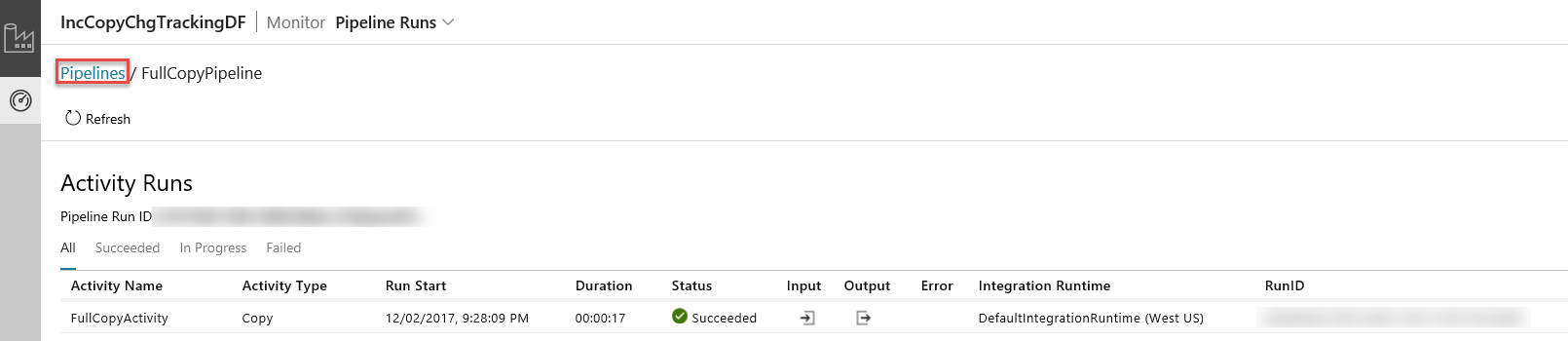
Aby powrócić do widoku Uruchomienia potoków, kliknij pozycję Potoki w sposób przedstawiony na powyższym obrazie.
Sprawdzanie wyników
Zostanie wyświetlony plik o nazwie incremental-<GUID>.txt w folderze incchgtracking kontenera adftutorial.
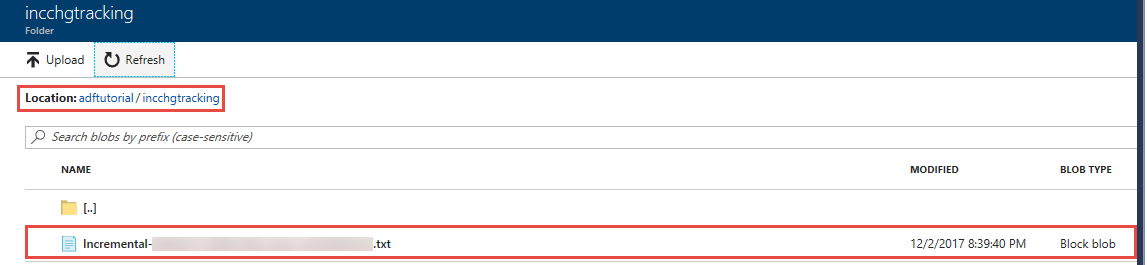
Plik powinien mieć dane z bazy danych:
1,aaaa,21
2,bbbb,24
3,cccc,20
4,dddd,26
5,eeee,22
Dodawanie większej ilości danych do tabeli źródłowej
Uruchom następujące zapytanie względem bazy danych, aby dodać wiersz i zaktualizować wiersz.
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Tworzenie potoku na potrzeby kopii przyrostowej
W tym kroku utworzysz potok z następującymi działaniami, który będzie okresowo uruchamiany. Za pomocą działań wyszukiwania zostanie pobrana stara i nowa wartość parametru SYS_CHANGE_VERSION z bazy danych Azure SQL Database, która zostanie następnie przekazana do działania kopiowania. Za pomocą działania kopiowania zostaną skopiowane wstawione, zaktualizowane lub usunięte dane między dwiema wartościami parametru SYS_CHANGE_VERSION z bazy danych Azure SQL Database do magazynu Azure Blob Storage. Za pomocą działania procedury składowanej zostanie zaktualizowana wartość parametru SYS_CHANGE_VERSION na potrzeby następnego uruchomienia potoku.
Utwórz plik JSON IncrementalCopyPipeline.json w tym samym folderze o następującej zawartości:
{ "name": "IncrementalCopyPipeline", "properties": { "activities": [ { "name": "LookupLastChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select * from table_store_ChangeTracking_version" }, "dataset": { "referenceName": "ChangeTrackingDataset", "type": "DatasetReference" } } }, { "name": "LookupCurrentChangeTrackingVersionActivity", "type": "Lookup", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion" }, "dataset": { "referenceName": "SourceDataset", "type": "DatasetReference" } } }, { "name": "IncrementalCopyActivity", "type": "Copy", "typeProperties": { "source": { "type": "SqlSource", "sqlReaderQuery": "select data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) as CT on data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}" }, "sink": { "type": "BlobSink" } }, "dependsOn": [ { "activity": "LookupLastChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] }, { "activity": "LookupCurrentChangeTrackingVersionActivity", "dependencyConditions": [ "Succeeded" ] } ], "inputs": [ { "referenceName": "SourceDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "SinkDataset", "type": "DatasetReference" } ] }, { "name": "StoredProceduretoUpdateChangeTrackingActivity", "type": "SqlServerStoredProcedure", "typeProperties": { "storedProcedureName": "Update_ChangeTracking_Version", "storedProcedureParameters": { "CurrentTrackingVersion": { "value": "@{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}", "type": "INT64" }, "TableName": { "value": "@{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}", "type": "String" } } }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" }, "dependsOn": [ { "activity": "IncrementalCopyActivity", "dependencyConditions": [ "Succeeded" ] } ] } ] } }Uruchom polecenie cmdlet Set-AzDataFactoryV2Pipeline, aby utworzyć potok: FullCopyPipeline.
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"Oto przykładowe dane wyjściowe:
PipelineName : IncrementalCopyPipeline ResourceGroupName : ADFTutorialResourceGroup DataFactoryName : IncCopyChgTrackingDF Activities : {LookupLastChangeTrackingVersionActivity, LookupCurrentChangeTrackingVersionActivity, IncrementalCopyActivity, StoredProceduretoUpdateChangeTrackingActivity} Parameters :
Uruchamianie potoku kopiowania przyrostowego
Uruchom potok: IncrementalCopyPipeline przy użyciu polecenia cmdlet Invoke-AzDataFactoryV2Pipeline .
Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName
Monitorowanie potoku kopiowania przyrostowego
Na karcie aplikacja Integracja danych odśwież widok Uruchomienia potoków. Upewnij się, że na liście widoczny jest potok IncrementalCopyPipeline. Kliknij link w kolumnie Akcje.
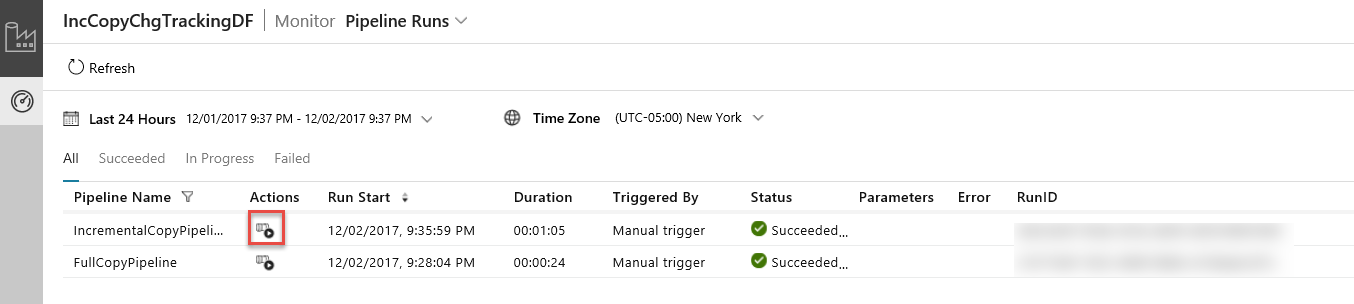
Po kliknięciu linków w kolumnie Akcje zostanie wyświetlona następująca strona, na której będą się znajdować wszystkie uruchomienia działań dla potoku.
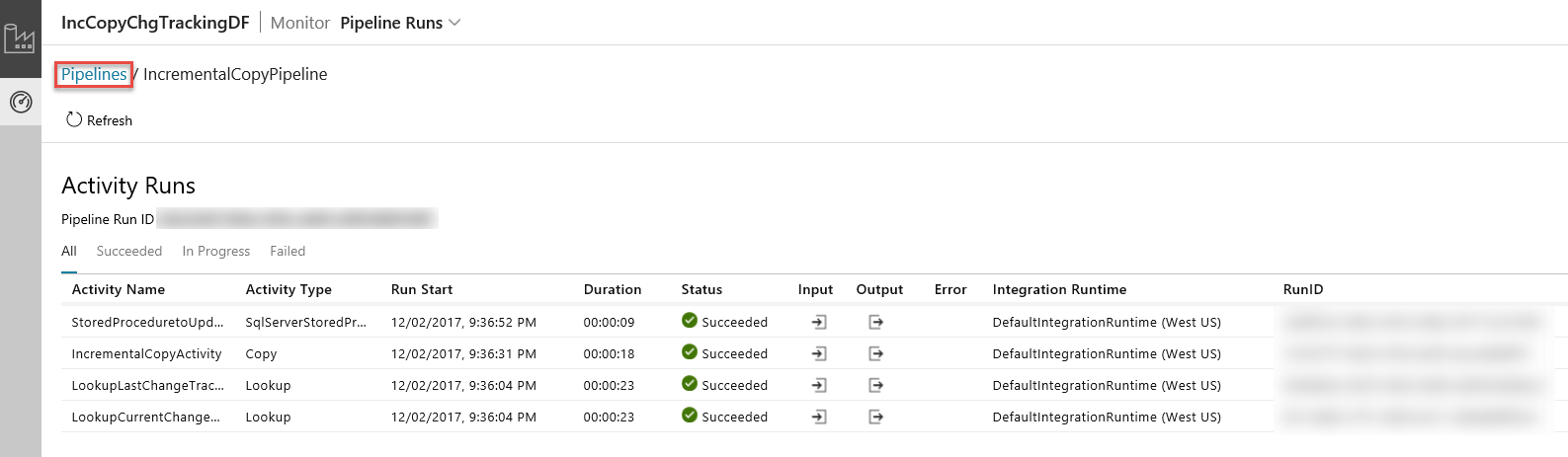
Aby powrócić do widoku Uruchomienia potoków, kliknij pozycję Potoki w sposób przedstawiony na powyższym obrazie.
Sprawdzanie wyników
W folderze incchgtracking kontenera adftutorial widoczny będzie drugi plik.
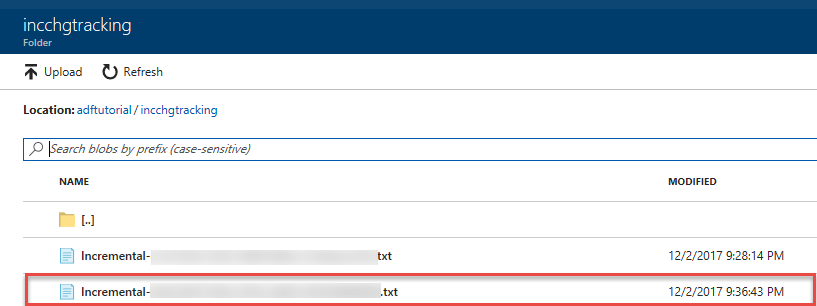
Plik powinien zawierać tylko dane różnicowe z bazy danych. Rekord z wartością U znajduje się w zaktualizowanym wierszu w bazie danych, a rekord z wartością I to jeden dodany wiersz.
1,update,10,2,U
6,new,50,1,I
Pierwsze trzy kolumny to zmienione dane z tabeli data_source_table. Ostatnie dwie kolumny to metadane z tabeli systemowej śledzenia zmian. Czwarta kolumna to wartość parametru SYS_CHANGE_VERSION dla każdego zmienionego wiersza. Piąta kolumna to wartość operacji: U — aktualizacja, I — wstawienie. Aby uzyskać szczegółowe informacje o śledzeniu zmian, zobacz CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Powiązana zawartość
Przejdź do poniższego samouczka, aby dowiedzieć się więcej o kopiowaniu nowych i zmienionych plików tylko na podstawie ich daty ostatniej modyfikacji: