Przekształcanie danych przy użyciu działań platformy Spark w usługach Azure Data Factory i Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Działanie Platformy Spark w fabryce danych i potokach usługi Synapse wykonuje program Spark we własnym klastrze usługi HDInsight lub na żądanie. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania. Gdy używasz połączonej usługi Spark na żądanie, usługa automatycznie tworzy klaster Spark na potrzeby przetwarzania danych w odpowiednim czasie, a następnie usuwa klaster po zakończeniu przetwarzania.
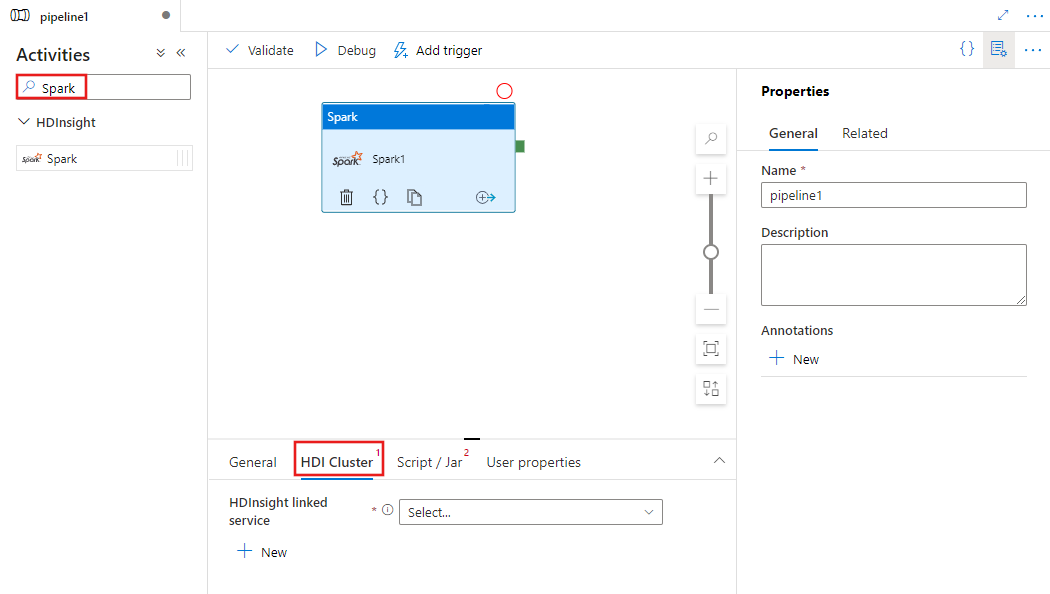
Dodawanie działania platformy Spark do potoku za pomocą interfejsu użytkownika
Aby użyć działania platformy Spark do potoku, wykonaj następujące kroki:
Wyszukaj ciąg Spark w okienku Działania potoku i przeciągnij działanie platformy Spark na kanwę potoku.
Wybierz nowe działanie platformy Spark na kanwie, jeśli nie zostało jeszcze wybrane.
Wybierz kartę Klaster usługi HDI, aby wybrać lub utworzyć nową połączoną usługę z klastrem usługi HDInsight, który będzie używany do wykonywania działania platformy Spark.
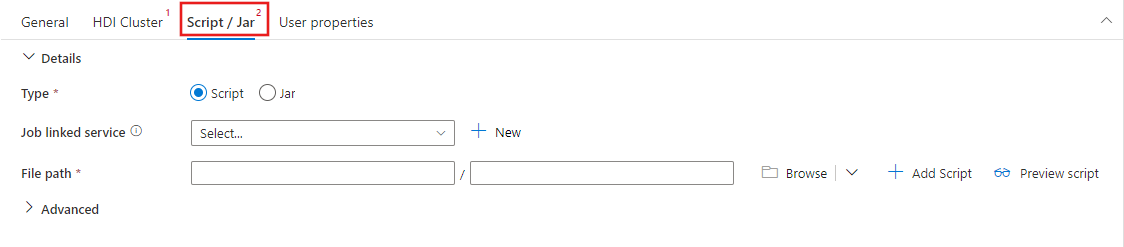
Wybierz kartę Skrypt /Jar , aby wybrać lub utworzyć nową połączoną usługę zadania z kontem usługi Azure Storage, które będzie hostować skrypt. Określ ścieżkę do pliku, który ma zostać tam wykonany. Możesz również skonfigurować zaawansowane szczegóły, w tym użytkownika serwera proxy, konfigurację debugowania i argumenty oraz parametry konfiguracji platformy Spark, które mają zostać przekazane do skryptu.
Właściwości działania platformy Spark
Oto przykładowa definicja JSON działania platformy Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwości | Opis | Wymagania |
|---|---|---|
| name | Nazwa działania w potoku. | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| type | W przypadku działania platformy Spark typ działania to HDInsightSpark. | Tak |
| linkedServiceName | Nazwa połączonej usługi HDInsight Spark, na której działa program Spark. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| SparkJobLinkedService | Połączona usługa Azure Storage, która przechowuje plik zadania platformy Spark, zależności i dzienniki. W tym miejscu obsługiwane są tylko połączone usługi Azure Blob Storage i ADLS Gen2. Jeśli nie określisz wartości dla tej właściwości, zostanie użyty magazyn skojarzony z klastrem usługi HDInsight. Wartość tej właściwości może być tylko połączoną usługą Azure Storage. | Nie. |
| rootPath | Kontener i folder obiektów blob platformy Azure, który zawiera plik Spark. W nazwie pliku jest uwzględniana wielkość liter. Aby uzyskać szczegółowe informacje na temat struktury tego folderu, zapoznaj się z sekcją struktury folderów (następna sekcja). | Tak |
| entryFilePath | Ścieżka względna do folderu głównego kodu/pakietu Spark. Plik wpisu musi być plikiem języka Python lub plikiem jar. | Tak |
| Classname | Klasa główna Java/Spark aplikacji | Nie. |
| Argumenty | Lista argumentów wiersza polecenia programu Spark. | Nie. |
| proxyUser | Konto użytkownika do personifikacji w celu wykonania programu Spark | Nie. |
| sparkConfig | Określ wartości właściwości konfiguracji platformy Spark wymienione w temacie: Konfiguracja platformy Spark — właściwości aplikacji. | Nie. |
| getDebugInfo | Określa, kiedy pliki dziennika platformy Spark są kopiowane do magazynu platformy Azure używanego przez klaster usługi HDInsight (lub) określony przez sparkJobLinkedService. Dozwolone wartości: Brak, Zawsze lub Niepowodzenie. Wartość domyślna: None. | Nie. |
Struktura folderów
Zadania platformy Spark są bardziej rozszerzalne niż zadania Pig/Hive. W przypadku zadań platformy Spark można podać wiele zależności, takich jak pakiety jar (umieszczone w klasie JAVA CLASSPATH), pliki języka Python (umieszczone w języku PYTHONPATH) i inne pliki.
Utwórz następującą strukturę folderów w usłudze Azure Blob Storage, do których odwołuje się połączona usługa HDInsight. Następnie przekaż pliki zależne do odpowiednich podfolderów w folderze głównym reprezentowanym przez entryFilePath. Na przykład przekaż pliki języka Python do podfolderu pyFiles i plików jar do podfolderu plików jar folderu głównego. W czasie wykonywania usługa oczekuje następującej struktury folderów w usłudze Azure Blob Storage:
| Ścieżka | opis | Wymagania | Typ |
|---|---|---|---|
. (katalog główny) |
Ścieżka główna zadania platformy Spark w połączonej usłudze magazynu | Tak | Folder |
| <zdefiniowany przez użytkownika > | Ścieżka wskazująca plik wpisu zadania platformy Spark | Tak | Plik |
| ./Słoiki | Wszystkie pliki w tym folderze są przekazywane i umieszczane na ścieżce klasy Java klastra | Nie. | Folder |
| ./pyFiles | Wszystkie pliki w tym folderze są przekazywane i umieszczane na ścieżce PYTHONPATH klastra | Nie. | Folder |
| ./Pliki | Wszystkie pliki w tym folderze są przekazywane i umieszczane w katalogu roboczym funkcji wykonawczej | Nie. | Folder |
| ./Archiwum | Wszystkie pliki w tym folderze są nieskompresowane | Nie. | Folder |
| ./Dzienniki | Folder zawierający dzienniki z klastra Spark. | Nie. | Folder |
Oto przykład magazynu zawierającego dwa pliki zadań platformy Spark w usłudze Azure Blob Storage, do których odwołuje się połączona usługa HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Powiązana zawartość
Zapoznaj się z następującymi artykułami, które wyjaśniają sposób przekształcania danych na inne sposoby: