你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Apache Spark 迁移到 Azure Managed Instance for Apache Cassandra
我们建议在可能的情况下,使用 Apache Cassandra 本机复制通过配置混合群集将现有群集中的数据迁移到 Azure Managed Instance for Apache Cassandra。 此方法使用 Apache Cassandra 的 gossip 协议将源数据中心的数据复制到新的托管实例数据中心。 但在某些情况下,源数据库版本不兼容,或者混合群集设置不可行。
本教程介绍如何使用 Cassandra Spark 连接器和 Azure Databricks for Apache Spark 以脱机方式将数据迁移到 Azure Managed Instance for Apache Cassandra。
先决条件
使用 Azure 门户或 Azure CLI 预配一个 Azure Managed Instance for Apache Cassandra 群集,并确保可以使用 CQLSH 连接到该群集。
在托管的 Cassandra VNet 中预配一个 Azure Databricks 帐户。 另外请确保该帐户可通过网络访问源 Cassandra 群集。
确保已将密钥空间/表方案从源 Cassandra 数据库迁移到目标 Cassandra 托管实例数据库。
预配 Azure Databricks 群集
建议选择支持 Spark 3.0 的 Databricks 运行时版本 7.5。
添加依赖项
将 Apache Spark Cassandra 连接器库添加到群集,以便连接到本机终结点和 Azure Cosmos DB Cassandra 终结点。 在群集中,选择“库”>“安装新库”>“Maven”,然后在 Maven 坐标中添加 com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 。
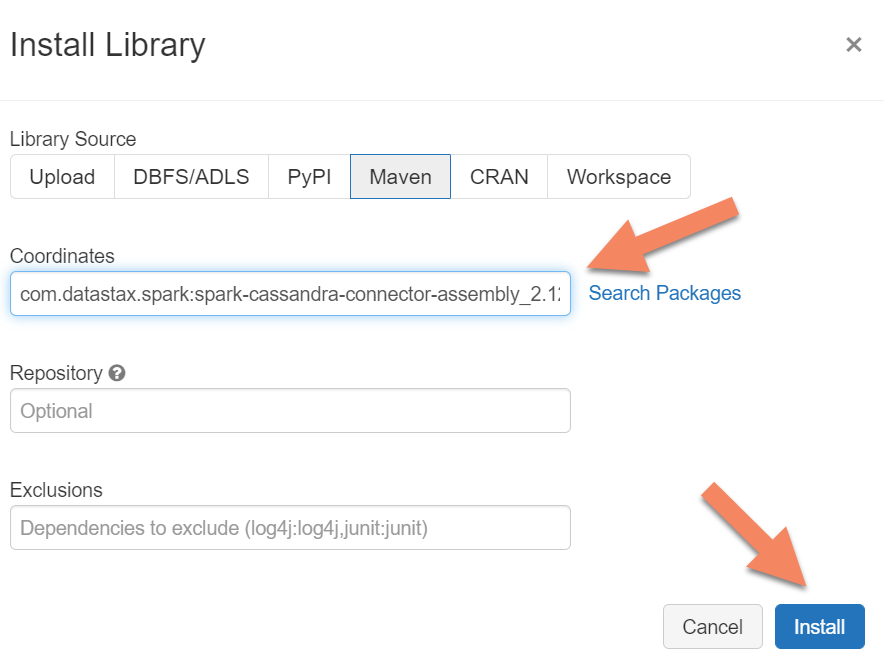
选择“安装”,然后在安装完成后重启群集。
注意
请确保在安装 Cassandra 连接器库之后重启 Databricks 群集。
创建用于迁移的 Scala 笔记本
在 Databricks 中创建 Scala 笔记本。 将源和目标 Cassandra 配置替换为相应的凭据,并替换源和目标密钥空间和表。 然后运行以下代码:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
注意
如果你需要保留每一行的原始 writetime,请参阅 cassandra migrator 示例。