你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Apache Flink® DataStream API 将事件消息写入 Azure Data Lake Storage Gen2
重要
此功能目前以预览版提供。 Microsoft Azure 预览版的补充使用条款包含适用于 beta 版、预览版或其他尚未正式发布的 Azure 功能的更多法律条款。 有关此特定预览版的信息,请参阅 Azure HDInsight on AKS 预览版信息。 如有疑问或功能建议,请在 AskHDInsight 上提交请求并附上详细信息,并关注我们以获取 Azure HDInsight Community 的更多更新。
Apache Flink 通过文件系统使用和持久存储数据,用于应用程序的结果和容错及恢复。 在本文中,了解如何使用 DataStream API 将事件消息写入 Azure Data Lake Storage Gen2。
先决条件
- HDInsight on AKS 上的 Apache Flink 群集
- HDInsight 上的 Apache Kafka 群集
- 需要确保按照如使用 Apache Kafka on HDInsight 中所述处理网络设置。 请确保 AKS 上的 HDInsight 和 HDInsight 群集位于同一虚拟网络中。
- 使用 MSI 访问 ADLS Gen2
- 用于在 AKS 虚拟网络 HDInsight 的 Azure VM 上进行开发的 IntelliJ
Apache Flink FileSystem 连接器
此文件系统连接器为 BATCH 和 STREAMING 提供相同的保证,旨在为 STREAMING 执行提供仅一次的语义。 有关详细信息,请参阅Flink DataStream 文件系统。
Apache Kafka 连接器
Flink 提供 Apache Kafka 连接器,用于从 Kafka 主题读取数据以及将数据写入到 Kafka 主题,并提供一次保证。 有关详细信息,请参阅Apache Kafka 连接器。
为 Apache Flink 生成项目
IntelliJ IDEA 上的 pom.xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
ADLS Gen2 接收器计划
abfsGen2.java
注意
将 Apache Kafka on HDInsight 群集 bootStrapServers 替换为你自己的用于 Kafka 3.2 的中转站
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
打包 jar 并提交到 Apache Flink。
将 jar 上传到 ABFS。

在
AppMode群集创建中传递作业 jar 信息。
注意
请确保将 classloader.resolve-order 添加为“parent-first”,将 hadoop.classpath.enable 添加为
true选择作业日志聚合,将作业日志推送到存储帐户。

可以看到作业正在运行。





在 ADLS Gen2 上验证流数据
我们看到 click_events 流式传输到 ADLS Gen2。

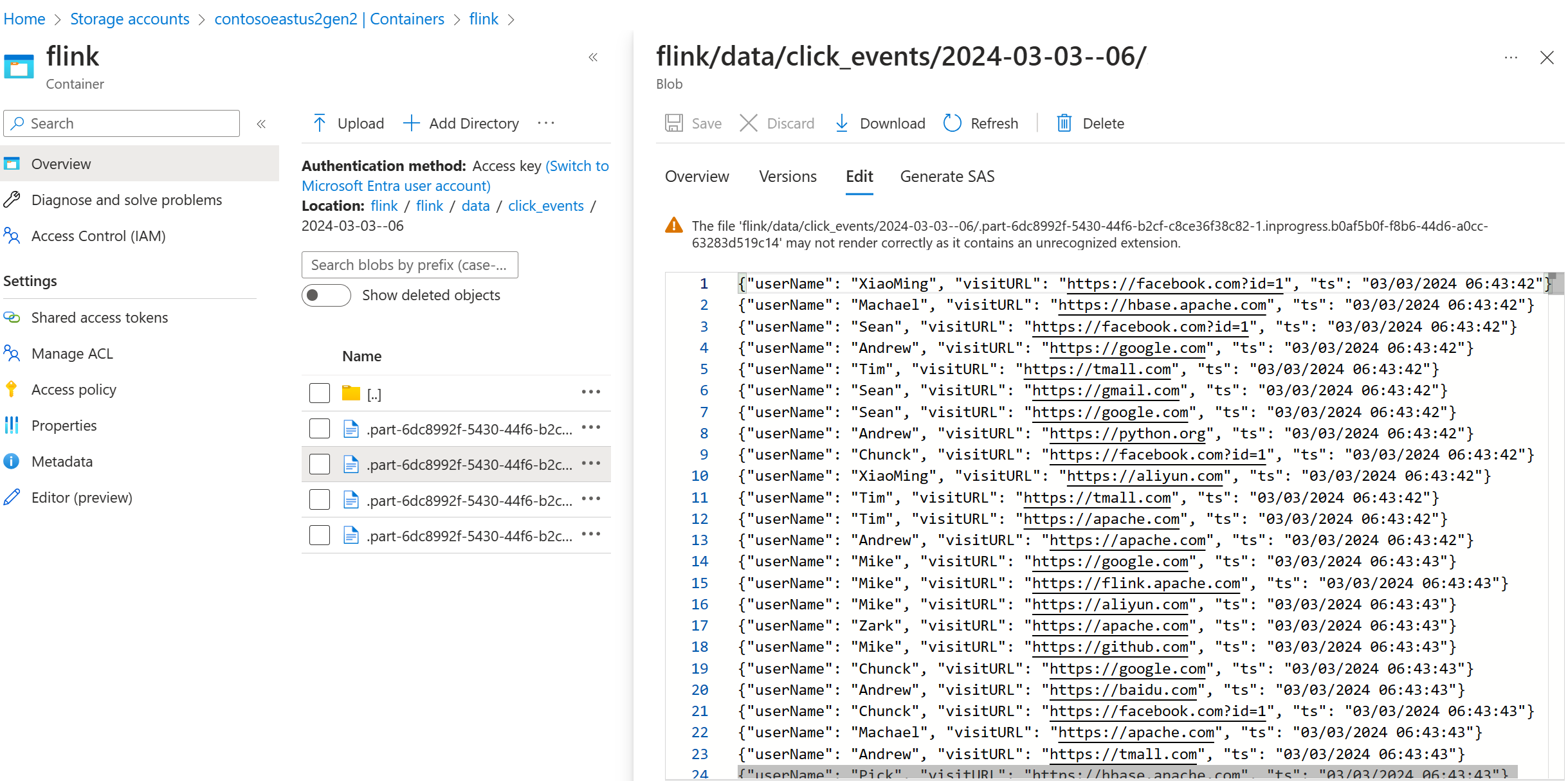
可以指定滚动策略,用于在以下三个条件中的任何一个下滚动正在进行的部件文件:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
参考
- Apache Kafka 连接器
- Flink DataStream 文件系统
- Apache Flink 网站
- Apache、Apache Kafka、Kafka、Apache Flink、Flink 和关联的开源项目名称是 Apache Software Foundation (ASF) 的商标。