你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何改进自定义视觉模型
本指南介绍如何提高自定义视觉模型的质量。 分类器或对象检测器的质量取决于提供的已标记数据的数量、质量和种类,以及整个数据集的平衡程度。 一个好的模型具有平衡的训练数据集,该数据集是将提交到模型的代表数据集。 此类模型的生成过程是迭代性的;通常需要进行几轮训练才能达到预期效果。
下面是帮助训练更准确模型的通用模式:
- 第一轮定型
- 添加更多的图像并平衡数据;重新训练
- 添加具有不同背景、照明、对象大小、相机角度和样式的图像;重新训练
- 使用新图像来测试预测
- 根据预测结果修改现有的训练数据
防止过度拟合
有时,模型将会根据图像中共有的任意特征来学习预测。 例如,创建苹果与柑橘的分类器时,如果使用了手中的苹果和白盘中的柑橘的图像,则分类器可能会过分注重于手与白盘,而不是苹果与柑橘。
要解决此问题,请提供具有不同角度、背景、对象大小、组和其他变化的图像。 下面的部分展开说明了这些概念。
数据数量
训练图像的数量是数据集最重要的因素。 我们建议一开始为每个标签至少使用 50 个图像。 使用更少的图像时,过度拟合的风险会提高,同时,性能数字可能会指出质量良好,但模型可能很难处理实际数据。
数据平衡
考虑训练数据的相对数量也很重要。 例如,对两个不同的标签分别使用 50 和 500 个图像会使训练数据集不平衡。 这使得模型对其中一个标签的预测准确度高于另一个标签。 如果在图像最少的标签与图像最多的标签之间至少保持 1:2 的比例,则可能会看到更好的结果。 例如,如果图像最多的标签有 500 个图像,则图像最少的标签应该至少有 250 个图像用于训练。
数据多样性
请务必使用在正常使用期间提交到分类器的代表性图像。 否则,模型可能会根据图像中共有的任意特征来学习预测。 例如,创建苹果与柑橘的分类器时,如果使用了手中的苹果和白盘中的柑橘的图像,则分类器可能会过分注重于手与白盘,而不是苹果与柑橘。

若要更正此问题,请包含多样化的图像,以确保模型能够适当通用化。 以下是可使定型集更加多样化的一些方法:
背景:在不同背景的前面提供对象的图像。 自然场景中的照片比中性背景前的照片更好,因为前者为分类器提供了更多信息。

照明:提供不同照明下的图像(即在闪光、高曝光等设置下拍摄),尤其是在用于预测的图像具有不同照明的情况下。 使用不同饱和度、色调和亮度的图像也很有帮助。

对象大小:提供具有不同大小和数量的对象的图像(例如,几串香蕉的照片和一根香蕉的特写照片)。 不同的大小有助于分类器涵盖所有方面。

照相机角度:提供以不同照相机角度拍摄的图像。 或者,如果必须使用固定相机(例如监控摄像头)拍摄所有照片,请确保为每个定期出现的对象分配不同的标签,以避免过度拟合,即将不相关的对象(例如灯柱)解释为关键特征。

样式:提供类相同、样式不同的图像(例如,不同品种的同一种水果)。 但是,如果对象的样式有很大的差异(例如,“米老鼠”与现实的老鼠),我们建议将它们标记为单独的类,以更好地表示其独特特征。

负片图像(仅限分类器)
如果在使用图像分类器,则可能需要添加负示例来使分类器更准确。 负样本是与任何其他标记不匹配的图像。 上传这些图像时,请向其添加特殊的负标签。
对象检测器会自动处理负示例,因为绘制的边框之外的任何图像区域都被视为负片。
注意
自定义视觉服务支持某些自动负片图像处理。 例如,如果要生成葡萄与香蕉的分类器并提交一张鞋子图像用于预测,则分类器对于该图像的葡萄与香蕉评分均应接近 0%。
另一方面,如果负片图像仅仅是定型中使用的图像的变量,由于相似性很大,模型很可能将负片图像分类为标记类。 例如,如果具有一个橙子与葡萄柚分类器,并且输入克莱门氏小柑橘的图像,则它可能将克莱门氏小柑橘分类为橙子,因为克莱门氏的许多特征类似于橙子。 如果负片图像具有这种性质,建议在训练期间创建一个或多个单独的标签(例如,“其他”)并使用此标签标记负片图像,使模型更好地区分这些类。
遮蔽和截断(仅限对象检查器)
如果希望对象探测器检测到截断的对象(对象已部分地从图像中剪掉)或遮蔽的对象(对象被图像中的另一个对象部分阻挡),则需要包括涵盖这些情况的训练图像。
注意
其他对象遮蔽的对象的问题不会与重叠阈值(用于对模型性能进行评级的参数)混淆。 自定义视觉网站上的“重叠阈值”滑块用于处理预测的边框必须与真正边框重叠多少,才能视为正确。
使用预测图像进一步训练
通过将图像提交到预测终结点来使用或测试模型时,自定义视觉服务会存储这些图像。 然后,你可以使用这些图像来改进模型。
若要查看提交到模型的图像,请打开自定义视觉网页,转到相应项目,然后选择“预测”选项卡。默认视图显示当前迭代的图像。 可使用“迭代”下拉菜单查看先前迭代期间提交的图像。
将鼠标悬停在图像上可查看模型预测的标记。 图像将会排序,能够为模型带来最大改善的图像列在顶部。 若要使用不同的排序方法,请在“排序”部分做出选择。
若要将某个图像添加到现有训练数据,请选择该图像,设置正确的标记,然后选择“保存并关闭”。 该图像将从“预测”中删除,并添加到训练图像集。 可选择“定型图像”选项卡查看该图像。
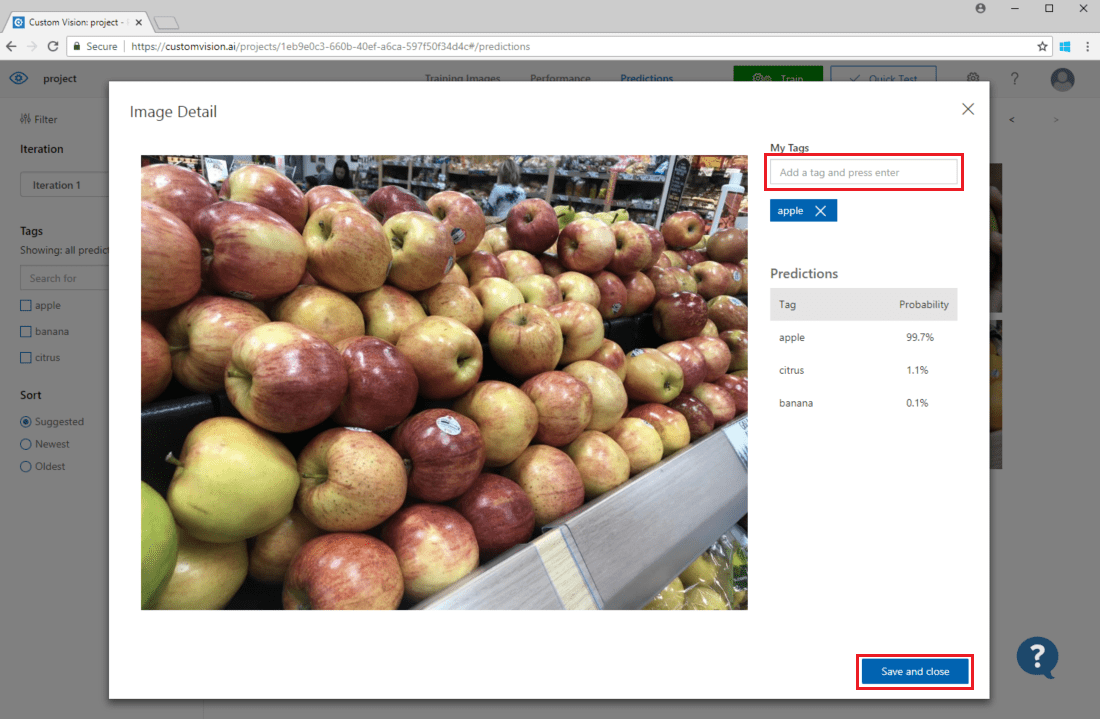
然后使用“训练”按钮重新训练模型。
直观检查预测
若要检查图像预测,请转到“训练图像”选项卡,在“迭代”下拉菜单中选择前一个训练迭代,然后检查“标记”部分下的一个或多个标记。 现在,视图应会围绕其模型未能正确预测给定标记的每个图像显示一个红框。
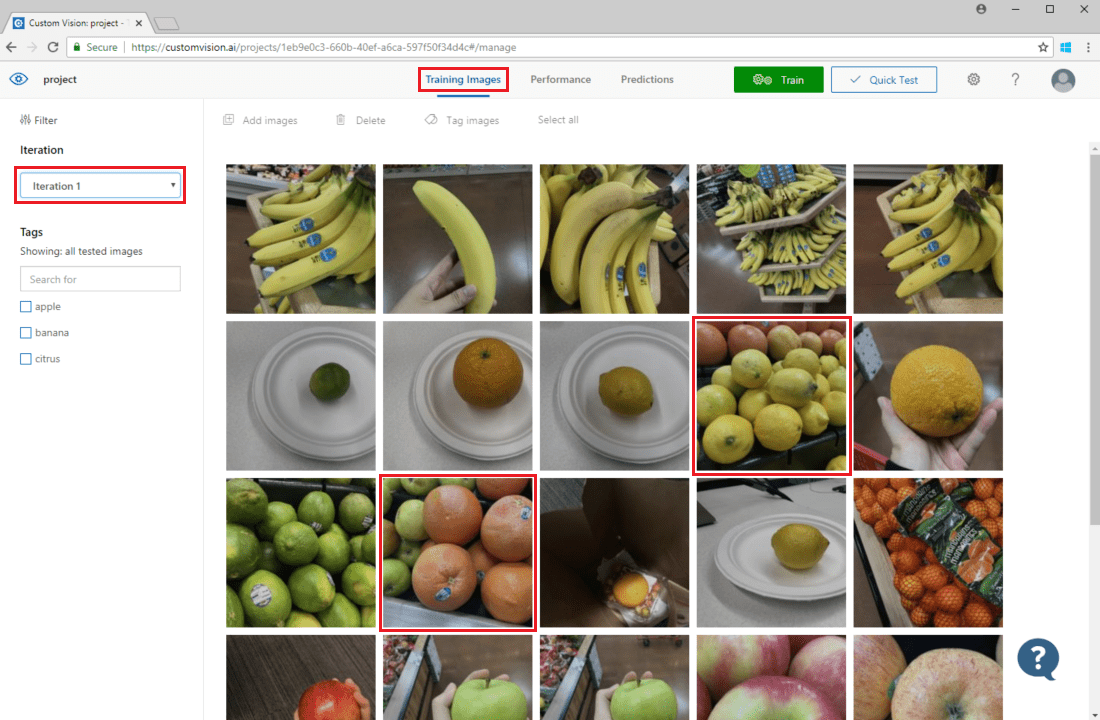
有时,视觉检查可以识别模式,然后,你可通过添加更多训练数据或修改现有训练数据来纠正这些模式。 例如,苹果与酸橙的分类器可能会错误地将所有青苹果标记为酸橙。 可以通过添加并提供包含青苹果的已标记图像的训练数据来纠正此问题。
后续步骤
本指南介绍了使自定义图像分类模型或对象检测器模型变得更准确的几种方法。 接下来,请了解如何通过将图像提交到预测 API 来以编程方式测试这些图像。