Announcements, Azure HPC Cache, Storage
Supercomputing 2020—New MPI heights, joining the Graph500, and 1 TB/s filesystems
Posted on
6 min read
A year ago during SC19, Azure unveiled the HBv2 clusters of virtual machines (VM) for high-performance computing (HPC). At the time, we characterized this uniquely powerful and scalable VM as “rivaling the most advanced supercomputers on the planet.” A bold claim for a cloud provider, to be sure. Since then we’ve endeavored to deliver on this promise. What we’ve been delighted to find is just how much our commitment to scalable HPC as a driver of innovation and creativity has resonated with customers and partners. Better still, they have inspired us to set the bar even higher. Most importantly, in this uniquely challenging year, we have been privileged to support our customers’ and partners’ most mission-critical and impactful work.
As Supercomputing 2020 (SC20) kicks off, we’d like to share some significant updates about Azure’s continued delivery of new supercomputing capabilities on our Azure H-series products. We’d also like to provide a sneak peek at a forthcoming addition to our Azure HPC portfolio.
86,400 cores for critical disease research
Azure is excited to announce it has achieved a new record for Message Passing Interface-based (MPI) HPC scaling on the public cloud. Running Nanoscale Molecular Dynamics (NAMD) across 86,400 central processing unit (CPU) cores, Azure has demonstrated petascale computing truly is at the fingertips of researchers anywhere.
NAMD is widely recognized as one of the most impactful HPC applications of the 21st century for its ability to deliver ultra-realistic biomolecular simulations, earning it the nickname of “the computational microscope.” Through Microsoft’s participation in the COVID-19 HPC Consortium, Azure’s Dr. Jer-Ming Chia teamed up with researchers from the Beckman Institute for Advanced Science and Technology at the University of Illinois to evaluate HBv2 VMs for supporting future simulations of the SARS-CoV-2 virus.
The team found not only could HBv2 clusters meet the researchers’ requirements, but that performance and scalability on Azure rivaled and in some cases surpassed the capabilities of the Frontera supercomputer, ranked 8th on the June 2020 TOP500 list, at the University of Texas at Austin. Frontera is the U.S. National Science Foundation’s leadership-class HPC resource for open science research.
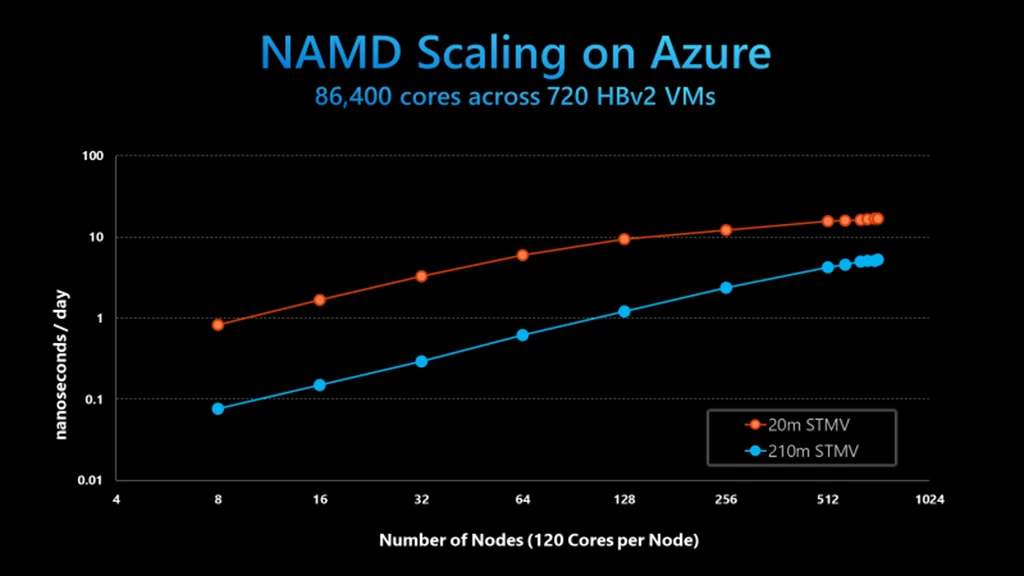
Figure 1: NAMD Speedup from 8 to 720 Azure HBv2 VMs, Tobacco Mosaic Virus model
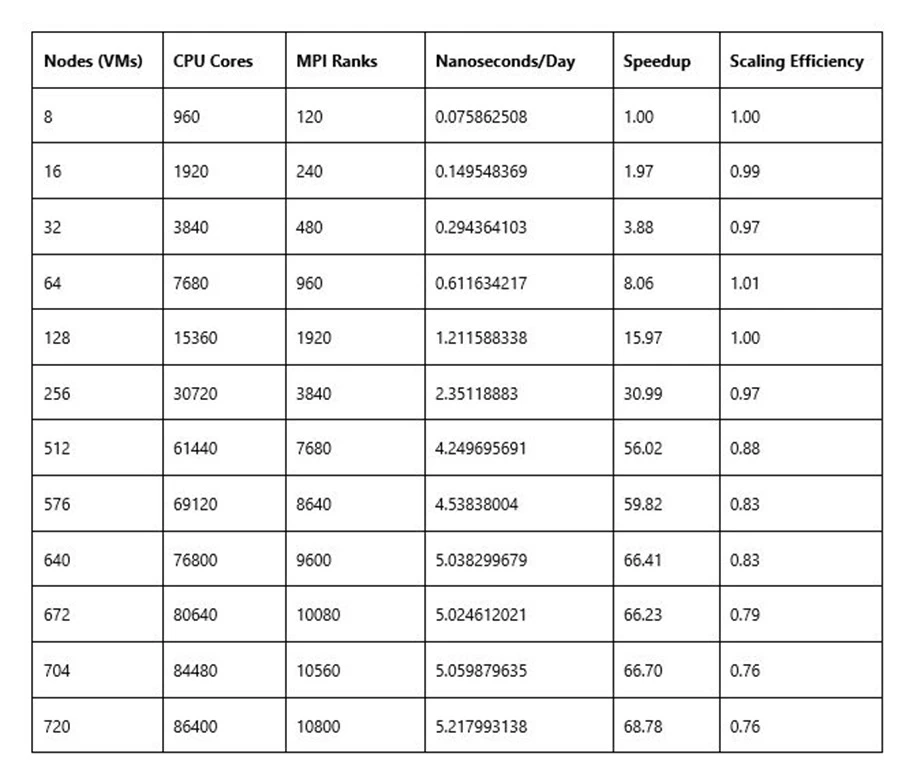
Figure 2: NAMD performance and scaling, 210m atom STMV model
Compared to published benchmarking of NAMD 2.15 on Frontera, at 512 nodes (61,440 parallel processes) using the 210m atom STMV case, HBv2 running NAMD 2.14 yielded:
- 87 percent more performance versus Frontera using AVX2 binaries (4.25ns v. 2.27ns).
- 37 percent more performance versus Frontera using AVX512 binaries (4.25ns v. 3.1ns).
- 8 percent less performance versus Frontera using AVX512-Tiles binaries (4.25ns v. 4.62 ns).
- 7 percent plus scaling efficiency versus Frontera using AVX512-Tiles binaries (87 percent versus 80 percent).
In addition, the team ultimately was able to scale NAMD to 720 HBv2 cluster nodes providing an additional 23 percent application performance and a 13 percent lead over the highest levels of demonstrated performance on Frontera for this model.
Visit Jer-ming’s blog to learn more about Microsoft’s work supporting accelerated drug discovery through supercomputing scale on Azure.
Azure joins the Graph500 with Top 20 showing
At SC20, Azure is proud to join the ranks of the world’s most powerful data-intensive supercomputers by placing 17th on the prestigious Graph500. To our knowledge, this is the first time a public cloud has placed on the Graph500. With HBv2 VMs yielding 1,151 GTEPS (Giga-Traversed Edges Per Second), Azure’s placement on the Graph500 ranks among the top 6 percent all-time for published submissions.
As opposed to the TOP500 Linpack benchmark, the Graph500 focuses on data-intensive workloads. As the work of every sector of government, enterprise, and research becomes increasingly data-centric, the Graph500 serves as a useful barometer for customers and partners looking to migrate challenging data problems to the Cloud.
The breadth-first search (BFS) test within the Graph500 benchmark stresses HPC and supercomputing environments in multiple ways with a consistent emphasis on the ability to move data. It also uses the “popcount” CPU instruction that is particularly useful for customer workloads in the fields of cryptography, molecular fingerprinting, and extremely dense data storage.
Azure H-series VMs for HPC are a particularly compelling platform for this kind of workload because of Azure’s leadership memory bandwidth and InfiniBand networking. HBv2 VMs, for example, feature up to 84 percent more memory bandwidth and 10x lower network latencies compared to other public cloud HPC platforms. In addition, Azure’s InfiniBand-equipped VMs support hardware-accelerated MPI collectives.
Dr. Jithin Jose of the Azure HPC team scaled the BFS test to 640 HBv2 VMs using 64 parallel processes per VM, as the BFS test strongly prefers to use process counts based on power-of-2 configurations. In total, these 640 VMs leveraged more than 287 terabytes of distributed memory, 218 terabytes/s of aggregate memory bandwidth, and 230 terabits/s of bisection network bandwidth.
Visit Jithin’s blog on the Azure Tech Community to learn how to run Graph500 benchmarks on our family of H-series Virtual Machines.
The cloud’s first one TB/s parallel filesystem
In response to significant customer interest, the Azure HPC is pleased to report it has successfully demonstrated the first-ever one terabyte per second cloud-based parallel filesystem.
Using the BeeOND (“BeeGFS On Demand”) filesystem running across 300 HBv2 VMs and more than 250 terabytes of NVMe storage capacity, Azure’s Paul Edwards achieved 1.46 TB/s of read performance and 456 GB/s of write performance.
This is at least 3.6 higher read performance than that demonstrated or claimed elsewhere on the public cloud.
BeeOND is a well-matched HPC filesystem for the cloud due to its on-demand and elastic nature. It can be deployed for just one job all the way up to thousands. BeeOND also leverages remote direct memory access (RDMA) as enabled by Azure’s InfiniBand networking. Finally, it offers a disruptively cost-effective approach to high-performance scratch filesystems on the cloud as it leverages the local storage of Azure VMs included at no additional cost.
Visit our blog on the Azure Tech Community to learn how to deploy and optimize the BeeGFS and BeeOND parallel filesystems on Azure.
Cloud Supercomputing for More Customer Workloads
As Steve Scott, Azure CVP of Hardware Architecture is discussing this year at SC20, Azure is now running serious HPC workloads. As we pull together the announcements today and over the last year, and assess the top-end of HPC elsewhere on the public cloud, we see that Azure is now scaling up to 12 times higher.
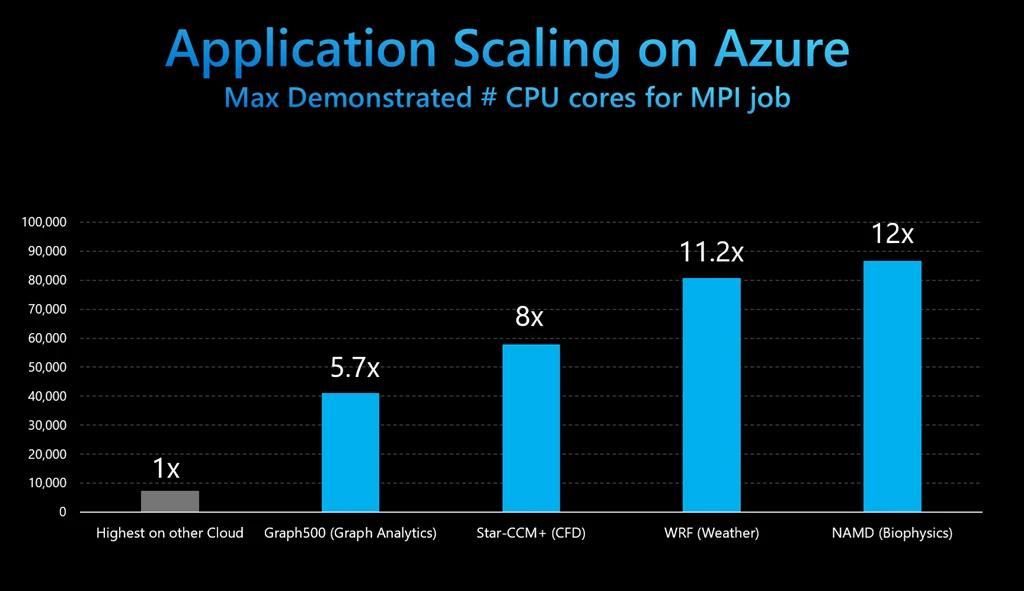
Figure 3: Largest scale Cloud MPI job (86,400 cores with NAMD)
Azure and AMD partner to bring 3rd Gen EPYC CPUs to HPC customers in 2021
The Azure HPC team is excited to share that the 3rd Gen EPYC processors from AMD, code-named “Milan” will join the Azure HPC family of products in 2021. With it will come new capabilities and benefits for Azure HPC customers and partners, including those looking to push the boundaries of supercomputing scale on the cloud. We are also excited to share that AMD, itself, will be a customer of this forthcoming Azure HPC product in support of its own silicon design workloads. We look forward to sharing more about this collaboration with AMD soon.
Unlocking customer innovation and creativity
Microsoft Azure is committed to delivering to our customers a world-class HPC experience, and maximum levels of performance, cost-efficiency, and scale.
“Our NIH center has put in years of programming effort towards developing fast scalable codes in NAMD. These efforts along with the UCX support in Charm++ allowed us to get good performance and scaling for NAMD on the Microsoft Azure Rome cluster without any other modifications to the source code.”—David Hardy, Sr Research Programmer, University of Illinois at Urbana-Champaign
“When critical customers have a unique need, like a challenging sparse graph problem, they no longer have to set up their own system to have world-class performance. Since we are rivaling results of the top ten machines in the world, this demo shows that anyone with a unique mission, including critical government users, can tap into our already existing capabilities. Because this comes without the cost and burden of ownership, this changes how high-performance compute will be accessed by mission users. I see this as greatly democratizing the impact of HPC.” —Dr. William Chappell, VP of Mission Systems at Microsoft
- Find out more about High-performance computing in Azure.
- Accelerating drug discovery with Azure supercomputing scale.
- Running the Graph500 benchmark suite on Azure.
- Tuning BeeGFS and BeeOND on Azure for Specific I/O Patterns.
- Azure HPC on Github.
- Azure HPC CentOS 7.6 and 7.7 images.
- Azure HPC Virtual Machines.