Руководство. Использование структурированной потоковой передачи Apache Spark с Apache Kafka в HDInsight
В этом руководстве показано, как использовать структурированную потоковую передачу Apache Spark, чтобы считывать и записывать данные с использованием Apache Kafka в Azure HDInsight.
Структурированная потоковая передача Spark — это механизм обработки потока, встроенный в Spark SQL. Он позволяет выражать потоковые вычисления так же, как пакетные вычисления статических данных.
В этом руководстве описано следующее:
- Использование шаблона Azure Resource Manager для создания кластеров.
- Использование структурированной потоковой передачи Spark с Kafka.
Выполнив инструкции, не забудьте удалить кластеры, чтобы избежать ненужных расходов.
Необходимые компоненты
jq — обработчик командной строки JSON. См. раздел https://stedolan.github.io/jq/.
Опыт работы с записными книжками Jupyter и Spark в HDInsight. Дополнительные сведения см. в статье Руководство. Загрузка данных и выполнение запросов в кластере Apache Spark в Azure HDInsight.
Опыт работы с языком программирования Scala. Код, используемый в этом руководстве, написан на языке Scala.
Опыт создания разделов Kafka. Дополнительные сведения см. в документе Краткое руководство по созданию Apache Kafka в кластере HDInsight.
Внимание
Чтобы выполнить действия, описанные в этом документе, необходимо иметь группу ресурсов Azure, которая содержит кластеры Spark и Kafka в HDInsight. Оба этих кластера находятся в виртуальной сети Azure, что позволяет кластеру Spark напрямую обмениваться данными с кластером Kafka.
Для удобства в этом документе есть ссылка на шаблон, с помощью которого можно создать все необходимые ресурсы Azure.
Дополнительные сведения об использовании HDInsight в виртуальной сети см. в статье опланирование виртуальной сети для Azure HDInsight.
Структурированная потоковая передача с помощью Apache Kafka
Структурированная потоковая передача Spark — это механизм обработки потока, встроенный в ядро Spark SQL. При использовании структурированной потоковой передачи можно писать запросы потоковой передачи так же, как и пакетные запросы.
В следующих фрагментах кода демонстрируется чтение данных из Kafka и их сохранение в файле. Первый фрагмент кода — это пакетная операция, а второй — операция потоковой передачи.
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
В обоих фрагментах кода данные считываются из Kafka и записываются в файл. Ниже показаны различия в примерах.
| Пакетная служба | Потоковая передача |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Операция потоковой передачи также использует awaitTermination(30000), что останавливает потоковую передачу спустя 30 000 мс.
Чтобы использовать структурированную потоковую передачу с помощью Kafka, ваш проект должен иметь зависимость в пакете org.apache.spark : spark-sql-kafka-0-10_2.11. Версия этого пакета должна соответствовать версии Spark в HDInsight. Для Spark 2.4 (доступно в HDInsight 4.0) можно найти сведения о зависимости для различных типов проектов по адресу https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Для приложения Jupyter Notebook, используемого в рамках этого руководства, следующая ячейка передает зависимость пакета:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Создание кластеров
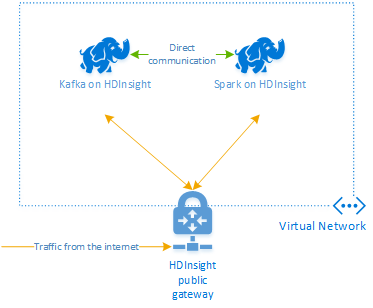
Apache Kafka в HDInsight не предоставляет доступ к брокерам Kafka через общедоступный сегмент Интернета. Все ресурсы, которые использует Kafka, должны находиться в одной виртуальной сети Azure. В рамках этого руководства кластеры Kafka и Spark расположены в одной и той же виртуальной сети Azure.
На следующей схеме показано, как происходит обмен данными между Spark и Kafka:
Примечание.
Служба Kafka ограничена обменом данными в пределах виртуальной сети. Другие службы в кластере, например SSH и Ambari, могут быть доступны через Интернет. Дополнительные сведения об общих портах, доступных в HDInsight, см. в статье Порты и универсальные коды ресурсов (URI), используемые кластерами HDInsight.
Чтобы создать виртуальную сеть Azure, а затем создать кластеры Kafka и Spark в ее пределах, выполните такие действия:
Нажмите эту кнопку, чтобы войти в Azure и открыть шаблон на портале Azure.

Шаблон Azure Resource Manager доступен по адресу https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json.
Этот шаблон создает следующие ресурсы:
Кластер Kafka в HDInsight 4.0 или 5.0.
Кластер SPARK 2.4 или 3.1 в HDInsight 4.0 или 5.0.
виртуальную сеть Azure, содержащую кластеры HDInsight.
Внимание
Структурированная записная книжка потоковой передачи, используемая в этом руководстве, требует Spark 2.4 или 3.1 в HDInsight 4.0 или 5.0. Если используется более ранняя версия Spark в HDInsight, возникнут ошибки при использовании этой записной книжки.
Заполните раздел Настроенный шаблон, используя следующие сведения:
Параметр Значение Отток подписок Ваша подписка Azure Группа ресурсов Группа ресурсов, в которой содержатся ресурсы. Расположение Регион Azure, в котором создаются ресурсы. Spark Cluster Name (Имя кластера Spark) Имя кластера Spark. Первые шесть символов должны отличаться от имени кластера Kafka. Kafka Cluster Name (Имя кластера Kafka) Имя кластера Kafka. Первые шесть символов должны отличаться от имени кластера Spark. Имя пользователя для входа в кластер Имя администратора кластеров. Пароль для входа в кластер Пароль администратора кластеров. Имя пользователя SSH Пользователь SSH, который создается для кластеров. Пароль SSH Пароль пользователя SSH. 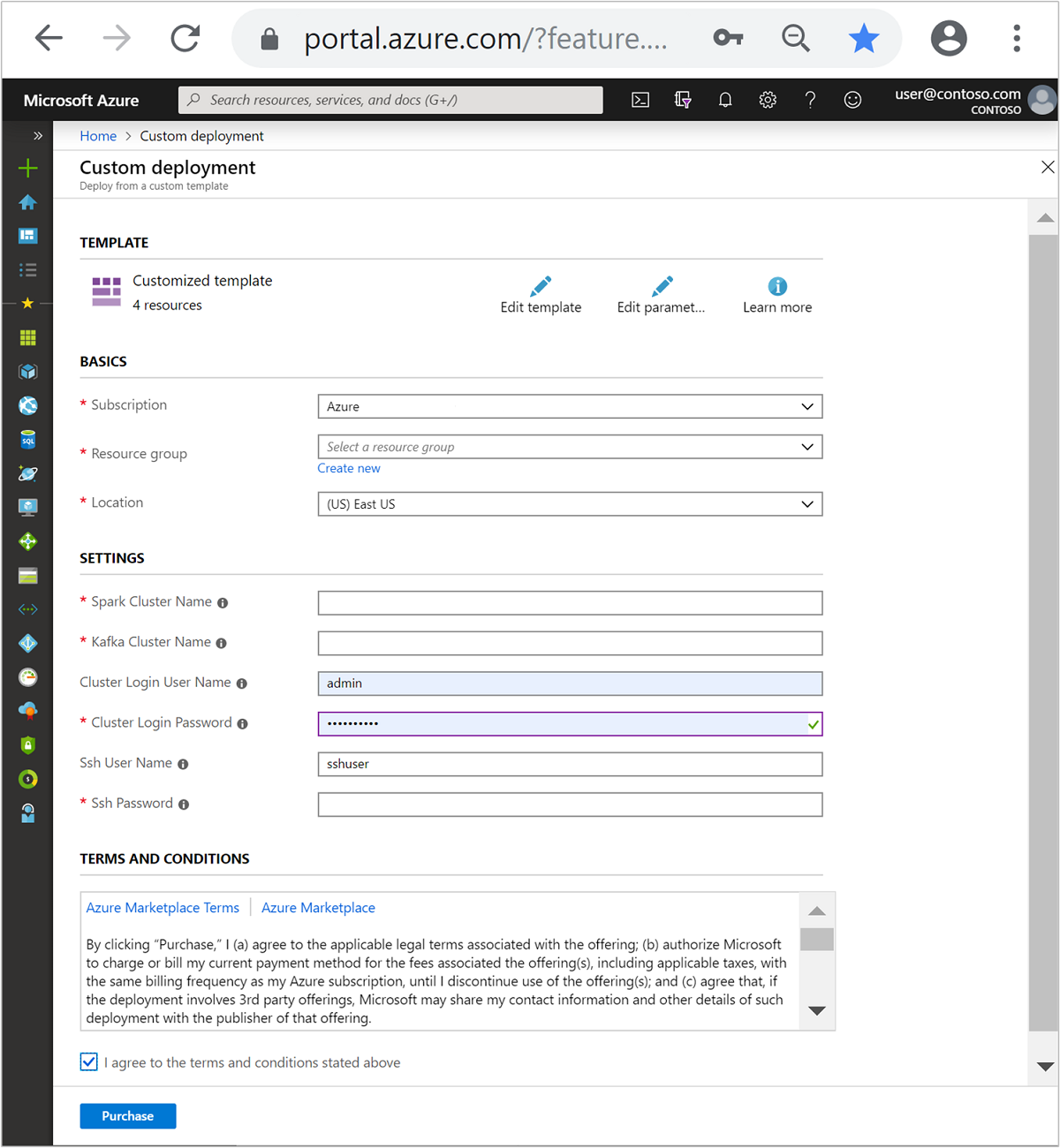
Прочтите условия использования и установите флажок Я принимаю указанные выше условия.
Щелкните Приобрести.
Примечание.
Создание кластеров может занять до 20 минут.
Использование структурированной потоковой передачи Spark
В этом примере показано, как использовать структурированную потоковую передачу Spark с Kafka в HDInsight. Для этого примера используются данные о поездках в такси, предоставленные сайтом города Нью-Йорк. Набор данных, используемых в этой записной книжке, взят на странице 2016 Green Taxi Trip Data.
Выполните сбор информации об узле. Воспользуйтесь приведенными ниже командами curl и jq, чтобы получить сведения об узлах Kafka ZooKeeper и брокера. Эти команды предназначены для командной строки Windows. Команды для других сред будут немного отличаться. Замените
KafkaClusterименем кластера Kafka, аKafkaPassword— паролем для входа в кластер. Также заменитеC:\HDI\jq-win64.exeфактическим путем к папке установки jq. Введите команды в командной строке Windows и сохраните выходные данные для использования в следующих шагах.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, гдеCLUSTERNAME— это имя вашего кластера. При появлении запроса введите имя администратора кластера и пароль, которые использовались при создании кластера.Выберите Создать > Spark, чтобы создать записную книжку.
При потоковой передаче данных Spark использует микропакеты, то есть данные передаются в пакетах, после чего такие пакеты обрабатываются исполнителями. Если время ожидания простоя исполнителя меньше времени, затрачиваемого на обработку пакета, исполнители будут постоянно добавляться и удаляться. Если время ожидания простоя исполнителя превышает длительность передачи пакета, такой исполнитель не будет удаляться. Поэтому мы рекомендуем отключить динамическое распределение, задав для параметра spark.dynamicAllocation.enabled значение false, при запуске приложений с потоковой передачей данных.
Загрузите пакеты, используемые Notebook, указав следующие сведения в ячейке Notebook. Выполните команду, нажав клавиши CTRL+ВВОД.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Создайте раздел Kafka. Измените указанную ниже команду, заменив
YOUR_ZOOKEEPER_HOSTSсведениями об узле Zookeeper, которые вы извлекли на первом шаге. Введите измененную команду в Jupyter Notebook, чтобы создать разделtripdata.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersПолучите данные о поездках в такси. Введите команду в следующей ячейке, чтобы загрузить данные о поездках в такси в Нью-Йорке. Данные загружаются в таблицу данных, которая потом отображается в виде выходных данных ячейки.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Укажите сведения об узлах брокера Kafka. Замените
YOUR_KAFKA_BROKER_HOSTSинформацией об узлах брокера, которую вы извлекли на первом шаге. Введите измененную команду в следующей ячейке Jupyter Notebook.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Отправьте данные в Kafka. В приведенной ниже команде поле
vendoridиспользуется в качестве значения ключа для сообщения Kafka. Kafka использует ключ при секционировании данных. Все поля хранятся в сообщении Kafka в виде строковых значений JSON. Введите следующую команду в Jupyter, чтобы сохранить данные в Kafka с помощью пакетного запроса.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Объявите схему. В приведенной ниже команде показано, как использовать схему при считывании данных JSON из Kafka. Введите команду в следующую ячейку Jupyter.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Выберите данные и начните потоковую передачу. Следующая команда извлекает данные из Kafka с помощью пакетного запроса. Затем запишите результаты в HDFS в кластере Spark. В этом примере
selectполучает сообщение (значение поля) из Kafka и применяет схему к нему. Затем данные записываются в HDFS (WASB или ADL) в формате Parquet. Введите команду в следующую ячейку Jupyter.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Чтобы проверить, созданы ли файлы, введите команду в следующую ячейку Jupyter. Отобразится список файлов из каталога
/example/batchtripdata.%%bash hdfs dfs -ls /example/batchtripdataВ предыдущем примере использовался пакетный запрос. В следующей команде показано, как сделать то же самое, используя запрос потоковой передачи. Введите команду в следующую ячейку Jupyter.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Выполните следующую ячейку, чтобы проверить, записаны ли файлы в ответ на запрос потоковой передачи.
%%bash hdfs dfs -ls /example/streamingtripdata
Очистка ресурсов
Чтобы очистить ресурсы, созданные при работе с этим руководством, удалите группу ресурсов. При удалении группы ресурсов также удаляются связанные с ней кластер HDInsight и другие ресурсы.
Чтобы удалить группу ресурсов с помощью портала Azure, сделайте следующее:
- На портале Azure разверните меню слева, чтобы открыть меню служб, а затем выберите Группы ресурсов, чтобы просмотреть список групп ресурсов.
- Найдите группу ресурсов, которую нужно удалить, и щелкните правой кнопкой мыши кнопку Дополнительно (…) справа от списка.
- Выберите Удалить группу ресурсов и подтвердите выбор.
Предупреждение
Начисление оплаты начинается после создания кластера HDInsight и прекращается только после его удаления. Кластеры оплачиваются поминутно, поэтому всегда следует удалять кластер, когда он больше не нужен.
При удалении кластера Kafka в HDInsight удаляются все данные, хранящиеся в Kafka.