Announcements, Azure HPC Cache, Compute, Storage
Announcing the general availability of the new Azure HPC Cache service
Posted on
5 min read
If data-access challenges have been keeping you from running high-performance computing (HPC) jobs in Azure, we’ve got great news to report! The now-available Microsoft Azure HPC Cache service lets you run your most demanding workloads in Azure without the time and cost of rewriting applications and while storing data where you want to—in Azure or on your on-premises storage. By minimizing latency between compute and storage, the HPC Cache service seamlessly delivers the high-speed data access required to run your HPC applications in Azure.
Use Azure to expand analytic capacity—without worrying about data access
Most HPC teams recognize the potential for cloud bursting to expand analytic capacity. While many organizations would benefit from the capacity and scale advantages of running compute jobs in the cloud, users have been held back by the size of their datasets and the complexity of providing access to those datasets, typically stored on long-deployed network-attached storage (NAS) assets. These NAS environments often hold petabytes of data collected over a long period of time and represent significant infrastructure investment.
Here’s where the HPC Cache service can help. Think of the service as an edge cache that provides low-latency access to POSIX file data sourced from one or more locations, including on-premises NAS and data archived to Azure Blob storage. The HPC Cache makes it easy to use Azure to increase analytic throughput, even as the size and scope of your actionable data expands.
Keep up with the expanding size and scope of actionable data
The rate of new data acquisition in certain industries such as life sciences continues to drive up the size and scope of actionable data. Actionable data, in this case, could be datasets that require post-collection analysis and interpretation that in turn drive upstream activity. A sequenced genome can approach hundreds of gigabytes, for example. As the rate of sequencing activity increases and becomes more parallel, the amount of data to store and interpret also increases—and your infrastructure has to keep up. Your power to collect, process, and interpret actionable data—your analytic capacity—directly impacts your organization’s ability to meet the needs of customers and to take advantage of new business opportunities.
Some organizations address expanding analytic throughput requirements by continuing to deploy more robust on-premises HPC environment with high-speed networking and performant storage. But for many companies, expanding on-premises environments presents increasingly daunting and costly challenges. For example, how can you accurately forecast and more economically address new capacity requirements? How do you best juggle equipment lifecycles with bursts in demand? How can you ensure that storage keeps up (in terms of latency and throughput) with compute demands? And how can you manage all of it with limited budget and staffing resources?
Azure services can help you more easily and cost-effectively expand your analytic throughput beyond the capacity of existing HPC infrastructure. You can use tools like Azure CycleCloud and Azure Batch to orchestrate and schedule compute jobs on Azure virtual machines (VMs). More effectively manage cost and scale by using low-priority VMs, as well as Azure Virtual Machine Scale Sets. Use Azure’s latest H- and N-series Virtual Machines to meet performance requirements for your most complex workloads.
So how do you start? It’s straightforward. Connect your network to Azure via ExpressRoute, determine which VMs you will use, and coordinate processes using CycleCloud or Batch—voila, your burstable HPC environment is ready to go. All you need to do is feed it data. Ok, that’s the stickler. This is where you need the HPC Cache service.
Use HPC Cache to ensure fast, consistent data access
Most organizations recognize the benefits of using cloud: a burstable HPC environment can give you more analytic capacity without forcing new capital investments. And Azure offers additional pluses, letting you take advantage of your current schedulers and other toolsets to ensure deployment consistency with your on-premises environment.
But here’s the catch when it comes to data. Your libraries, applications, and location of data may require the same consistency. In some circumstances, a local analytic pipeline may rely on POSIX paths that must be the same whether running in Azure or locally. Data may be linked between directories, and those links may need to be deployed in the same way in the cloud. The data itself may reside in multiple locations and must be aggregated. Above all else, the latency of access must be consistent with what can be realized in the local HPC environment.
To understand how the HPC Cache works to address these requirements, consider it an edge cache that provides low-latency access to POSIX file data sourced from one or more locations. For example, a local environment may contain a large HPC cluster connected to a commercial NAS solution. HPC Cache enables access from that NAS solution to Azure Virtual Machines, containers, or machine learning routines operating across a WAN link. The service accomplishes this by caching client requests (including from the virtual machines), and ensuring that subsequent accesses of that data are serviced by the cache rather than by re-accessing the on-premises NAS environment. This lets you run your HPC jobs at a similar performance level as you could in your own data center. HPC Cache also lets you build a namespace consisting of data located in multiple exports across multiple sources while displaying a single directory structure to client machines.
HPC Cache provides a Blob-backed cache (we call it Blob-as-POSIX) in Azure as well, facilitating migration of file-based pipelines without requiring that you rewrite applications. For example, a genetic research team can load reference genome data into the Blob environment to further optimize the performance of secondary-analysis workflows. This helps mitigate any latency concerns when you launch new jobs that rely on a static set of reference libraries or tools.
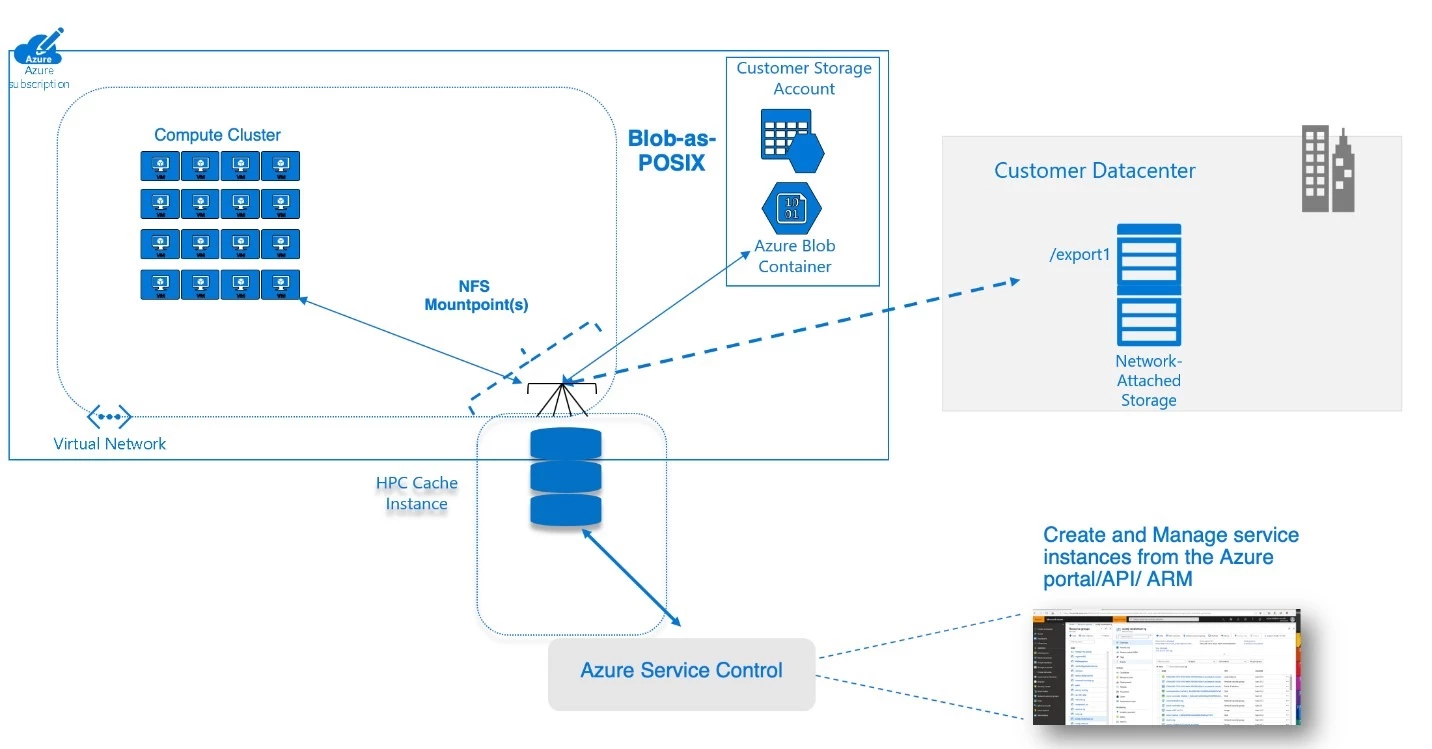
Azure HPC Cache Architecture
HPC Cache Benefits
Caching throughput to match workload requirements
HPC Cache offers three SKUs: up to 2 gigabytes per second (GB/s), up to 4 GB/s, and up to 8 GB/s throughput. Each of these SKUs can service requests from tens to thousands of VMs, containers, and more. Furthermore, you choose the size of your cache disks to control your costs while ensuring the right capacity is available for caching.
Data bursting from your datacenter
HPC Cache fetches data from your NAS, wherever it is. Run your HPC workload today and figure out your data storage policies over the longer term.
High-availability connectivity
HPC Cache provides high-availability (HA) connectivity to clients, a key requirement for running compute jobs at larger scales.
Aggregated namespace
The HPC Cache aggregated namespace functionality lets you build a namespace out of various sources of data. This abstraction of sources makes it possible to run multiple HPC Cache environments with a consistent view of data.
Lower-cost storage, full POSIX compliance with Blob-as-POSIX
HPC Cache supports Blob-based, fully POSIX-compliant storage. HPC Cache, using the Blob-as-POSIX format, maintains full POSIX support including hard links. If you need this level of compliance, you’ll be able to get full POSIX at Blob price points.
Start here
The Azure HPC Cache Service is available today and can be accessed now. For the very best results, contact your Microsoft team or related partners—they’ll help you build a comprehensive architecture that optimally meets your specific business objectives and desired outcomes.
Our experts will be attending at SC19 in Denver, Colorado, the conference on high-performance computing, ready and eager to help you accelerate your file-based workloads in Azure!