Kubernetes: Introdução
Aprenda a implementar e gerir aplicações contentorizadas.
Noções básicas sobre os contentores
Antes de começar a utilizar o Kubernetes, é importante compreender como funciona a contentorização.
Da mesma forma que as indústrias do transporte utilizam contentores físicos para isolar as diferentes mercadorias que transportam em navios, comboios, camiões e aviões, as tecnologias de desenvolvimento de software recorrem cada vez mais a um conceito chamado "contentorização".
Um pacote individual de software, conhecido como "contentor", agrupa o código de uma aplicação juntamente com os ficheiros de configuração, as bibliotecas e as dependências associadas necessárias à execução da aplicação. Desta forma, os programadores e profissionais de TI podem criar e implementar aplicações de forma mais rápida e segura.
A contentorização oferece as vantagens do isolamento, da portabilidade, da agilidade, da escalabilidade e do controlo ao longo de todo o fluxo de trabalho do ciclo de vida das aplicações. Os contentores, abstraídos do sistema operativo anfitrião, autonomizam-se e tornam-se mais portáteis, podendo ser executados em qualquer plataforma ou na cloud, de forma uniforme e consistente em qualquer infraestrutura.
Componentes e conceitos do Kubernetes
O cluster
No nível mais alto, o Kubernetes está organizado como um cluster de máquinas virtuais ou no local. Essas máquinas, chamadas "nós", partilham recursos de computação, rede e armazenamento. Cada cluster tem um nó principal ligado a um ou mais nós de trabalho. Os nós de trabalho são responsáveis pela execução de grupos de aplicações e cargas de trabalho contentorizadas, conhecidos como "pods", e o nó principal gere os pods que serão executados em cada nó de trabalho.
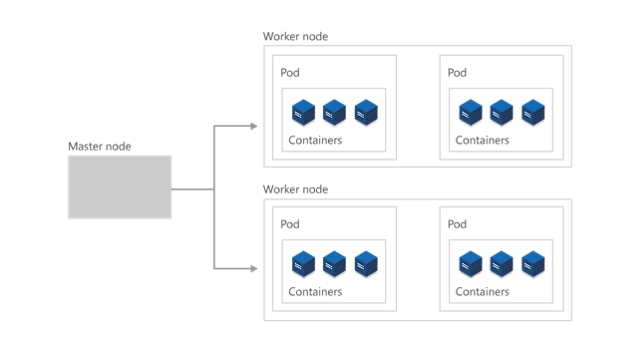
O plano de controlo
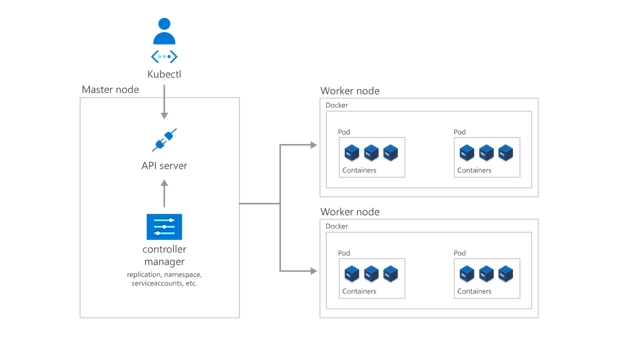
Para que o nó principal comunique com os nós de trabalho, e para que uma pessoa comunique com o nó principal, o Kubernetes inclui vários objetos que, coletivamente, formam o plano de controlo.
Os programadores e operadores interagem com o cluster essencialmente através do nó principal mediante a utilização de kubectl, uma interface de linha de comandos que é instalada no SO local. Os comandos emitidos para o cluster através de kubectl são recebidos pelo kube-apiserver, a API do Kubernetes que reside no nó principal. Posteriormente, o Kube-apiserver comunica os pedidos ao kube-controller-manager no nó principal, que, por sua vez, é responsável por processar as operações dos nós de trabalho. Os comandos do nó principal são recebidos pelo kubelet nos nós de trabalho.
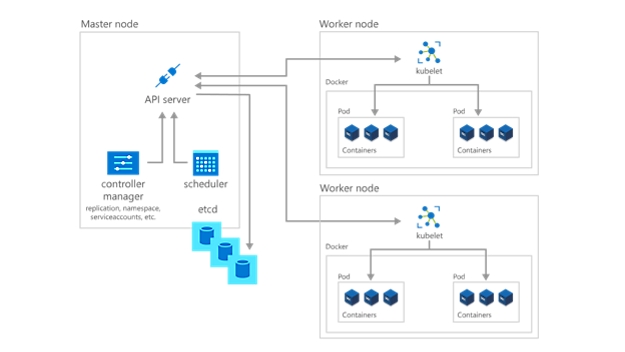
Implementar aplicações e cargas de trabalho
O próximo passo para começar a utilizar o Kubernetes é implementar aplicações e cargas de trabalho. O nó principal mantém sempre o estado atual do cluster e da configuração do Kubernetes no etcd, uma base de dados de arquivo de valores de chaves. Para executar pods com as aplicações e cargas de trabalho contentorizadas, vai descrever um estado pretendido novo para o cluster na forma de um ficheiro YAML. O kube-controller-manager recebe o ficheiro YAML e encarrega o kube-shceduler de decidir que nós de trabalho a aplicação ou carga de trabalho deve executar com base em restrições pré-determinadas. Ao trabalhar em conjunto com o kubelet de cada nó de trabalho, o kube-scheduler inicia os pods, analisa o estado dos computadores e é responsável, de um modo geral, pela gestão dos recursos.
Numa implementação do Kubernetes, o estado pretendido que descrever torna-se o estado atual no etcd, mas o estado anterior não se perde. O Kubernetes suporta reversões, implementação de atualizações e colocação de implementações em pausa. Além disso, as implementações utilizam ReplicaSets em segundo plano para garantir que o número especificado de pods com configuração idêntica são executados. Se um ou mais pods falharem, o Réplica substitui-os. Neste sentido, considera-se que o Kubernetes tem propriedades de autorrecuperação.
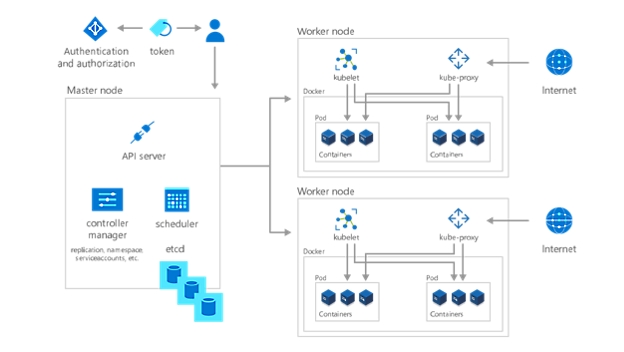
Estruturar e aprovisionar ambientes do Kubernetes
Com a sua aplicação ou carga de trabalho implementada, o último passo para começar a usar o Kubernetes é organizá-las e determinar o que ou quem tem acesso às mesmas. Mediante a criação de um espaço de nomes, um método de agrupamento no Kubernetes, permite que os serviços, os pods, os controladores e os volumes trabalhem facilmente em conjunto ao mesmo tempo que ficam isolados das outras partes do cluster. Do mesmo modo, pode utilizar o conceito de espaços de nomes do Kubernetes para aplicar configurações consistentes aos recursos.
Além disso , cada nó de trabalho contém um kube-proxy, que determina a forma como se pode aceder a vários aspetos do cluster a partir do exterior. Armazene informações privadas confidenciais, como tokens, certificados e palavras-passe em segredos, que é outro objeto do Kubernetes, que são codificados até ao runtime.
Por último, especifique quem pode ver e interagir com as várias partes do cluster, e como lhes é permitido interagir, com o controlo de acesso baseado em funções (RBAC).
Implemente uma solução de Kubernetes totalmente gerida
Faça a gestão do ambiente do Kubernetes alojado com o Azure Kubernetes Service (AKS). Implemente e mantenha aplicações contentorizadas mesmo sem ter experiência na orquestração de contentores. Aprovisione, atualize e dimensione recursos a pedido sem ter de colocar as aplicações offline.
Início rápido do Kubernetes: comece a trabalhar em 50 dias
Utilize este guia passo a passo para começar a utilizar o Kubernetes e obter experiência prática com os componentes, as capacidades e as soluções do Kubernetes.
Seguir o percurso de aprendizagem do Kubernetes