Przewodnik ustalania rozmiaru klastra interakcyjnego zapytań usługi Azure HDInsight (Hive LLAP)
W tym dokumencie opisano ustalanie rozmiaru klastra zapytań interakcyjnych usługi HDInsight (klastra HIVe LLAP) dla typowego obciążenia w celu osiągnięcia rozsądnej wydajności. Należy pamiętać, że zalecenia podane w tym dokumencie są ogólnymi wytycznymi, a określone obciążenia mogą wymagać określonego dostrajania.
Domyślne typy maszyn wirtualnych platformy Azure dla klastra zapytań interakcyjnych usługi HDInsight (LLAP)
| Typ węzła | Wystąpienie | Rozmiar |
|---|---|---|
| Head | D13 v2 | 8 vcpus, 56 GB pamięci RAM, 400 GB SSD |
| Pracownik | D14, wersja 2 | 16 vcpus, 112 GB pamięci RAM, 800 GB SSD |
| ZooKeeper | A4 v2 | 4 vcpus, 8 GB pamięci RAM, 40 GB SSD |
Uwaga: wszystkie zalecane wartości konfiguracji są oparte na węźle roboczym typu D14 v2
Konfiguracja:
| Klucz konfiguracji | Zalecana wartość | opis |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102400 (MB) | Łączna ilość pamięci podanej w MB dla wszystkich kontenerów usługi YARN w węźle |
| yarn.scheduler.maximum-allocation-mb | 102400 (MB) | Maksymalna alokacja dla każdego żądania kontenera w usłudze RM w mb/s. Żądania pamięci wyższe niż ta wartość nie zostaną zastosowane |
| yarn.scheduler.maximum-allocation-vcores | 12 | Maksymalna liczba rdzeni procesora CPU dla każdego żądania kontenera w usłudze Resource Manager. Żądania wyższe niż ta wartość nie zostaną zastosowane. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Liczba rdzeni procesora CPU na węzeł NodeManager, które można przydzielić dla kontenerów. |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | Alokacja pojemności usługi YARN dla kolejki LLAP |
| tez.am.resource.memory.mb | 4096 (MB) | Ilość pamięci w MB do użycia przez tez AppMaster |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | Liczba sesji dla każdej kolejki o nazwie w hive.server2.tez.default.queues. Ta liczba odpowiada liczbie koordynatorów zapytań (Tez AMs) |
| hive.tez.container.size | 4096 (MB) | Określony rozmiar kontenera Tez w MB |
| hive.llap.daemon.num.executors | 19 | Liczba funkcji wykonawczych na demona LLAP |
| hive.llap.io.threadpool.size | 19 | Rozmiar puli wątków dla funkcji wykonawczych |
| hive.llap.daemon.yarn.container.mb | 81920 (MB) | Łączna ilość pamięci w MB używana przez pojedyncze demony LLAP (pamięć na demona) |
| hive.llap.io.memory.size | 242688 (MB) | Rozmiar pamięci podręcznej w MB na demona LLAP, pod warunkiem, że pamięć podręczna SSD jest włączona |
| hive.auto.convert.join.noconditionaltask.size | 2048 (MB) | rozmiar pamięci w MB do wykonania sprzężenia mapy |
Architektura/składniki LLAP:
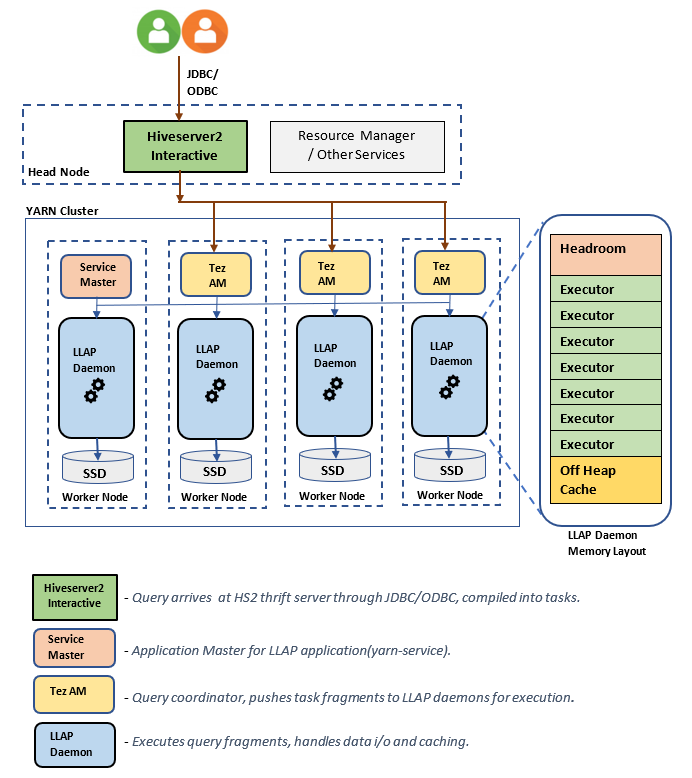
Szacowanie rozmiaru demona LLAP:
1. Określanie całkowitej alokacji pamięci usługi YARN dla wszystkich kontenerów w węźle
Konfiguracja: yarn.nodemanager.resource.memory-mb
Ta wartość wskazuje maksymalną sumę pamięci w MB, która może być używana przez kontenery YARN w każdym węźle. Określona wartość powinna być mniejsza niż łączna ilość pamięci fizycznej w tym węźle.
Łączna ilość pamięci dla wszystkich kontenerów usługi YARN w węźle = (Łączna ilość pamięci fizycznej — pamięć dla systemu operacyjnego + inne usługi)
Ustaw tę wartość na ok. 90% dostępnego rozmiaru pamięci RAM.
W przypadku D14 v2 zalecana wartość to 102400 MB.
2. Określanie maksymalnej ilości pamięci na żądanie kontenera YARN
Konfiguracja: yarn.scheduler.maximum-allocation-mb
Ta wartość wskazuje maksymalną alokację dla każdego żądania kontenera w usłudze Resource Manager, w MB. Żądania pamięci powyżej określonej wartości nie zostaną zastosowane. Usługa Resource Manager może dać pamięć kontenerom w przyrostach yarn.scheduler.minimum-allocation-mb i nie może przekroczyć rozmiaru określonego przez yarn.scheduler.maximum-allocation-mb. Określona wartość nie powinna być większa niż łączna ilość pamięci dla wszystkich kontenerów w węźle określonym przez yarn.nodemanager.resource.memory-mb.
W przypadku węzłów roboczych D14 v2 zalecana wartość to 102400 MB
3. Określanie maksymalnej vcores ilości na żądanie kontenera YARN
Konfiguracja: yarn.scheduler.maximum-allocation-vcores
Ta wartość wskazuje maksymalną liczbę rdzeni procesorów wirtualnych dla każdego żądania kontenera w usłudze Resource Manager. Żądanie większej vcores liczby wartości nie zostanie zastosowane. Jest to globalna właściwość harmonogramu usługi Yarn. W przypadku kontenera demona LLAP tę wartość można ustawić na 75% całkowitej dostępnej wartości vcores. Pozostałe 25% powinno być zarezerwowane dla NodeManager, DataNode i innych usług uruchomionych w węzłach roboczych.
Na maszynach 16 vcores wirtualnych D14 v2 można używać łącznie 16 vcores 75% kontenera demona LLAP.
W przypadku D14 v2 zalecana wartość to 12.
4. Liczba współbieżnych zapytań
Konfiguracja: hive.server2.tez.sessions.per.default.queue
Ta wartość konfiguracji określa liczbę sesji aplikacji Tez, które mogą być uruchomione równolegle. Te sesje tez są uruchamiane dla każdej kolejki określonej przez "hive.server2.tez.default.queues". Odpowiada on liczbie aplikacji Tez AMs (koordynatorów zapytań). Zaleca się, aby była taka sama jak liczba węzłów roboczych. Liczba węzłów demona LLAP może być większa niż liczba węzłów demona LLAP. Główną obowiązkiem serwera Tez AM jest koordynowanie wykonywania zapytania i przypisywanie fragmentów planu zapytania do odpowiednich demonów LLAP na potrzeby wykonywania. Zachowaj tę wartość jako wiele wielu węzłów demona LLAP, aby uzyskać większą przepływność.
Domyślny klaster usługi HDInsight ma cztery demony LLAP uruchomione w czterech węzłach roboczych, więc zalecana wartość to 4.
Suwak interfejsu użytkownika systemu Ambari dla zmiennej hive.server2.tez.sessions.per.default.queuekonfiguracji programu Hive:
5. Rozmiar wzorca aplikacji Tez i kontenera Tez
Konfiguracja: tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb — definiuje rozmiar wzorca aplikacji Tez.
Zalecana wartość to 4096 MB.
hive.tez.container.size — definiuje ilość pamięci podanej dla kontenera Tez. Tę wartość należy ustawić między minimalnym rozmiarem kontenera YARN (yarn.scheduler.minimum-allocation-mb) a maksymalnym rozmiarem kontenera YARN(yarn.scheduler.maximum-allocation-mb). Funkcje wykonawcze demona LLAP używają tej wartości do ograniczania wykorzystania pamięci na każdą funkcję wykonawczą.
Zalecana wartość to 4096 MB.
6. Alokacja pojemności kolejki LLAP
Konfiguracja: yarn.scheduler.capacity.root.llap.capacity
Ta wartość wskazuje procent pojemności przydzielonej do kolejki LLAP. Alokacje pojemności mogą mieć różne wartości dla różnych obciążeń, w zależności od sposobu konfiguracji kolejek usługi Yarn. Jeśli obciążenie stanowią operację tylko do odczytu, należy ustawić ją nawet na 90% pojemności. Jeśli jednak obciążenie jest połączeniem operacji aktualizacji/usuwania/scalania przy użyciu tabel zarządzanych, zaleca się przypisanie 85% pojemności do kolejki LLAP. Pozostałe 15% pojemności może być używane przez inne zadania, takie jak kompaktowanie itp., w celu przydzielenia kontenerów z domyślnej kolejki. Dzięki temu zadania w domyślnej kolejce nie pozbawią usługi Yarn zasobów.
W przypadku węzłów roboczych D14v2 zalecana wartość kolejki LLAP wynosi 85.
(W przypadku obciążeń tylko do odczytu można go zwiększyć do 90 odpowiednio).
7. Rozmiar kontenera demona LLAP
Konfiguracja: hive.llap.daemon.yarn.container.mb
Demon LLAP jest uruchamiany jako kontener YARN w każdym węźle roboczym. Całkowity rozmiar pamięci dla kontenera demona LLAP zależy od następujących czynników,
- Konfiguracje rozmiaru kontenera YARN (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Liczba aplikacji Tez AMs w węźle
- Łączna ilość pamięci skonfigurowanej dla wszystkich kontenerów w węźle i pojemności kolejki LLAP
Pamięć wymagana przez wzorce aplikacji Tez (Tez AM) można obliczyć w następujący sposób.
Tez AM działa jako koordynator zapytań, a liczba maszyn wirtualnych Tez powinna być skonfigurowana na podstawie wielu współbieżnych zapytań do obsłużenia. Teoretycznie możemy rozważyć jeden serwer Tez AM na węzeł roboczy. Istnieje jednak możliwość, że w węźle roboczym może być widocznych więcej niż jeden serwer Tez AM. W celu obliczenia zakładamy jednolitą dystrybucję maszyn wirtualnych Tez we wszystkich węzłach demona LLAP/węzłach procesu roboczego.
Zaleca się posiadanie 4 GB pamięci na tez AM.
Liczba tez Ams = wartość określona przez hive config hive.server2.tez.sessions.per.default.queue.
Liczba węzłów demona LLAP = określona przez zmienną env num_llap_nodes_for_llap_daemons w interfejsie użytkownika systemu Ambari.
Rozmiar kontenera tez AM = wartość określona przez tez config tez.am.resource.memory.mb.
Pamięć tez AM na węzeł = (ceil(Liczba węzłów demona LLAP Tez AMs / Liczba węzłów demona LLAP)x Rozmiar kontenera Tez AM**)**
W przypadku wersji D14 v2 domyślna konfiguracja ma cztery węzły Tez AMs i cztery węzły demona LLAP.
Pamięć tez AM na węzeł = (ceil(4/4) x 4 GB) = 4 GB
Łączna ilość pamięci dostępnej dla kolejki LLAP na węzeł procesu roboczego można obliczyć w następujący sposób:
Ta wartość zależy od całkowitej ilości pamięci dostępnej dla wszystkich kontenerów usługi YARN w węźle (yarn.nodemanager.resource.memory-mb) i wartości procentowej pojemności skonfigurowanej dla kolejki LLAP (yarn.scheduler.capacity.root.llap.capacity).
Łączna ilość pamięci dla kolejki LLAP w węźle procesu roboczego = całkowita ilość pamięci dostępnej dla wszystkich kontenerów usługi YARN w węźle x Procent pojemności dla kolejki LLAP.
W przypadku D14 v2 ta wartość to (100 GB x 0,85) = 85 GB.
Rozmiar kontenera demona LLAP jest obliczany w następujący sposób;
Rozmiar kontenera demona LLAP = (łączna ilość pamięci dla kolejki LLAP w węźle procesu roboczego) — (pamięć Tez AM na węzeł) — (rozmiar kontenera głównego usługi)
W klastrze jest tylko jeden wzorzec usługi (wzorzec aplikacji dla usługi LLAP) zduplikowany w jednym z węzłów procesu roboczego. W celu obliczenia rozważmy jeden wzorzec usługi na węzeł roboczy.
W przypadku węzła roboczego D14 w wersji 2 usługa HDI 4.0 — zalecana wartość to (85 GB – 4 GB – 1 GB)) = 80 GB
8. Określanie liczby funkcji wykonawczych na demona LLAP
Konfiguracja: hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors:
Ta konfiguracja kontroluje liczbę funkcji wykonawczych, które mogą wykonywać zadania równolegle na demona LLAP. Ta wartość zależy od liczby rdzeni wirtualnych, ilości pamięci wykorzystywanej na każdą funkcję wykonawczą oraz całkowitej ilości pamięci dostępnej dla kontenera demona LLAP. Liczba funkcji wykonawczych może być zastępowana do 120% dostępnych rdzeni wirtualnych na węzeł roboczy. Należy go jednak dostosować, jeśli nie spełnia wymagań dotyczących pamięci na podstawie pamięci wymaganej dla funkcji wykonawczej i rozmiaru kontenera demona LLAP.
Każda funkcja wykonawcza odpowiada kontenerowi Tez i może wykorzystywać 4 GB (rozmiar kontenera Tez) pamięci. Wszystkie funkcje wykonawcze w demonie LLAP współdzielą pamięć sterty. Przy założeniu, że nie wszystkie funkcje wykonawcze przeprowadzają operacje intensywnie korzystające z pamięci w tym samym czasie, można przeznaczyć 75% rozmiaru kontenera Tez (4 GB) na każdą funkcję wykonawczą. Pozwoli to zwiększyć liczbę funkcji wykonawczych, dając każdej funkcji mniej pamięci (na przykład 3 GB), aby zwiększyć równoległość. Zaleca się jednak dostosowanie tego ustawienia dla obciążenia docelowego.
Na maszynach wirtualnych D14 v2 jest dostępnych 16 rdzeni wirtualnych. W przypadku D14 v2 zalecaną wartością liczby funkcji wykonawczych jest (16 rdzeni wirtualnych x 120%) ~= 19 w każdym węźle roboczym, biorąc pod uwagę 3 GB na funkcję wykonawcza.
hive.llap.io.threadpool.size:
Ta wartość określa rozmiar puli wątków dla funkcji wykonawczych. A ponieważ — jak określono — funkcje wykonawcze są stałe, jest taka sama jak liczba funkcji wykonawczych na każdego demona LLAP.
W przypadku D14 v2 zalecana wartość to 19.
9. Określanie rozmiaru pamięci podręcznej demona LLAP
Konfiguracja: hive.llap.io.memory.size
Pamięć kontenera demona LLAP składa się z następujących składników;
- Pomieszczenie na głowę
- Pamięć stert używana przez funkcje wykonawcze (Xmx)
- Pamięć podręczna w pamięci na demona (jego rozmiar pamięci poza stertą, nie ma zastosowania, gdy pamięć podręczna SSD jest włączona)
- Rozmiar metadanych pamięci podręcznej w pamięci (dotyczy tylko wtedy, gdy jest włączona pamięć podręczna SSD)
Rozmiar miejsca pracy: ten rozmiar wskazuje część pamięci poza stertą używaną na potrzeby obciążenia maszyny wirtualnej Java (przestrzeń metadanych, stos wątków, gc struktury danych itp.). Ogólnie rzecz biorąc, ta rezerwa to około 6% rozmiaru sterty (Xmx). Aby być po bezpieczniejszej stronie, tę wartość można obliczyć jako 6% całkowitego rozmiaru pamięci demona LLAP.
W przypadku D14 v2 zalecaną wartością jest ceil(80 GB x 0,06) ~= 4 GB.
Rozmiar sterty (Xmx): jest to ilość pamięci sterty dostępnej dla wszystkich funkcji wykonawczych.
Całkowity rozmiar sterty = liczba funkcji wykonawczych × 3 GB
W przypadku D14 v2 ta wartość to 19 x 3 GB = 57 GB
Ambari environment variable for LLAP heap size:

Gdy pamięć podręczna SSD jest wyłączona, pamięć podręczna zlokalizowana w pamięci jest ilością pamięci pozostałej po odjęciu rezerwy i rozmiaru sterty od rozmiaru kontenera demona LLAP.
Obliczanie rozmiaru pamięci podręcznej różni się w przypadku włączenia pamięci podręcznej SSD.
Ustawienie hive.llap.io.allocator.mmap = true włącza buforowanie dysków SSD.
Po włączeniu pamięci podręcznej SSD część pamięci będzie używana do przechowywania metadanych dla pamięci podręcznej SSD. Metadane są przechowywane w pamięci i oczekuje się, że będzie to około 8% rozmiaru pamięci podręcznej SSD.
Wielkość metadanych w pamięci podręcznej SSD zlokalizowanej w pamięci = rozmiar kontenera demona LLAP − (rezerwa i rozmiar sterty)
W przypadku D14 w wersji 2 z funkcją HDI 4.0 rozmiar metadanych pamięci podręcznej SSD = 80 GB — (4 GB + 57 GB) = 19 GB
Biorąc pod uwagę rozmiar dostępnej pamięci do przechowywania metadanych pamięci podręcznej SSD, możemy obliczyć rozmiar pamięci podręcznej SSD, który może być obsługiwany.
Rozmiar metadanych w pamięci dla pamięci podręcznej SSD = rozmiar kontenera demona LLAP — (pokój główny i rozmiar sterty) = 19 GB
Rozmiar pamięci podręcznej SSD = rozmiar metadanych w pamięci dla pamięci podręcznej SSD (19 GB) / 0,08 (8 procent)
W przypadku D14 v2 i HDI 4.0 zalecany rozmiar pamięci podręcznej SSD = 19 GB / 0,08 ~= 237 GB
10. Dostosowywanie pamięci sprzężenia mapy
Konfiguracja: hive.auto.convert.join.noconditionaltask.size
Upewnij się, że dla tego parametru włączono funkcję hive.auto.convert.join.noconditionaltask .
Ta konfiguracja określa próg wyboru MapJoin przez optymalizator hive, który uwzględnia zastąpienie pamięci od innych funkcji wykonawczych, aby mieć więcej miejsca na tabele skrótów w pamięci, aby umożliwić większą liczbę konwersji sprzężenia mapy. Biorąc pod uwagę 3 GB na funkcję wykonawcza, ten rozmiar można przesubskrybować do 3 GB, ale niektóre pamięci sterty mogą być również używane do sortowania buforów, buforów mieszania itp. przez inne operacje.
Dlatego w przypadku D14 v2 z 3 GB pamięci na funkcję wykonawcza zaleca się ustawienie tej wartości na 2048 MB.
(Uwaga: Ta wartość może wymagać korekt odpowiednich dla obciążenia. Ustawienie tej wartości za mało może nie używać funkcji autokonwertuj. Ustawienie tego zbyt wysokiego poziomu może spowodować brak wyjątków pamięci lub wstrzymanie GC, które mogą prowadzić do niekorzystnej wydajności).
11. Liczba demonów LLAP
Zmienne środowiskowe systemu Ambari: num_llap_nodes, num_llap_nodes_for_llap_daemons
num_llap_nodes — określa liczbę węzłów używanych przez usługę HIVe LLAP, obejmuje to węzły z demonem LLAP, wzorcem usługi LLAP i wzorcem aplikacji Tez (Tez AM).
num_llap_nodes_for_llap_daemons — określona liczba węzłów używanych tylko dla demonów LLAP. Rozmiary kontenerów demona LLAP są ustawione na maksymalny rozmiar węzła, więc powoduje to wyświetlenie jednego llap demona w każdym węźle.

Zaleca się zachowanie tych samych wartości co liczba węzłów procesu roboczego w klastrze zapytań interakcyjnych.
Zagadnienia dotyczące zarządzania obciążeniami
Jeśli chcesz włączyć zarządzanie obciążeniami dla protokołu LLAP, upewnij się, że masz wystarczającą pojemność, aby zarządzanie obciążeniami działało zgodnie z oczekiwaniami. Zarządzanie obciążeniami wymaga konfiguracji niestandardowej kolejki YARN, która jest dodatkiem do llap kolejki. Upewnij się, że łączna pojemność zasobów klastra jest podzielona między llap kolejkę i kolejkę zarządzania obciążeniami zgodnie z wymaganiami dotyczącymi obciążenia.
Zarządzanie obciążeniami powoduje zduplikowanie wzorców aplikacji Tez (Tez AMs) po aktywowaniu planu zasobów.
Uwaga:
- Tez AMs zduplikowane przez aktywowanie planu zasobów zużywa zasoby z kolejki zarządzania obciążeniami określone przez
hive.server2.tez.interactive.queue. - Liczba maszyn wirtualnych Tez zależy od wartości
QUERY_PARALLELISMokreślonej w planie zasobów. - Po aktywnym zarządzaniu obciążeniami usługa Tez AMs w kolejce LLAP nie będzie używana. Tylko tez AMs z kolejki zarządzania obciążeniami są używane do koordynacji zapytań. Tez AMs w
llapkolejce są używane, gdy zarządzanie obciążeniami jest wyłączone.
Na przykład: Łączna pojemność klastra = 100 GB pamięci, podzielona między llAP, zarządzanie obciążeniami i kolejki domyślne w następujący sposób:
- Pojemność kolejki LLAP = 70 GB
- Pojemność kolejki zarządzania obciążeniami = 20 GB
- Domyślna pojemność kolejki = 10 GB
W przypadku pojemności kolejki zarządzania obciążeniami 20 GB plan zasobów może określić QUERY_PARALLELISM wartość pięć, co oznacza, że zarządzanie obciążeniami może uruchomić pięć maszyn wirtualnych Tez z rozmiarem kontenera 4 GB każdy. Jeśli QUERY_PARALLELISM pojemność jest wyższa niż pojemność, niektóre maszyny tez AM przestają odpowiadać w ACCEPTED stanie. Interakcyjny serwer Hive 2 nie może przesyłać fragmentów zapytań do maszyn wirtualnych Tez, które nie są w RUNNING stanie.
Następne kroki
Jeśli ustawienie tych wartości nie rozwiązało problemu, odwiedź jedną z następujących opcji...
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Połączenie za pomocą @AzureSupport — oficjalne konto platformy Microsoft Azure w celu poprawy jakości obsługi klienta przez połączenie społeczności platformy Azure z odpowiednimi zasobami: odpowiedziami, pomocą techniczną i ekspertami.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.
Inne odwołania: