
Azure Databricks
Ontwerp AI met analyses op basis van Apache Spark™.

Big data-analyse en AI met geoptimaliseerde Apache Spark
Verkrijg inzichten uit al je gegevens en ontwikkel AI-oplossingen (Artificial Intelligence) met Azure Databricks, stel binnen enkele minuten je Apache Spark™-omgeving in, pas de schaal automatisch aan en werk samen aan gedeelde projecten in een interactieve werkruimte. Azure Databricks biedt ondersteuning voor Python, Scala, R, Java en SQL, alsmede datawetenschapsframeworks en bibliotheken zoals TensorFlow, PyTorch en scikit-learn.
Apache Spark™ is een handelsmerk van de Apache Software Foundation.
Betrouwbare data engineering
Grootschalige gegevensverwerking voor batch- en streamingworkloads.
Analysemogelijkheden voor al je gegevens
Schakel analysemogelijkheden in voor de meest volledige en recente gegevens.
Datawetenschap voor samenwerking
Vereenvoudig en versnel het gebruik van datawetenschap op grote gegevenssets.
Geworteld in open source
Snelle, geoptimaliseerde Apache Spark-omgeving.
Snel aan de slag met een geoptimaliseerde Apache Spark-omgeving
Azure Databricks biedt de nieuwste versies van Apache Spark; hiermee kun je naadloos integreren met opensource-bibliotheken. Creëer snel clusters en ontwikkel snel in een volledig beheerde Apache Spark-omgeving met de wereldwijde schaal en beschikbaarheid van Azure. De clusters worden ingesteld, geconfigureerd en afgestemd om betrouwbaarheid en hoogwaardige prestaties te waarborgen, zonder dat bewaking noodzakelijk is. Profiteer van automatische schaalaanpassing en automatische beëindiging om de totale eigendomskosten (TCO) te verbeteren.
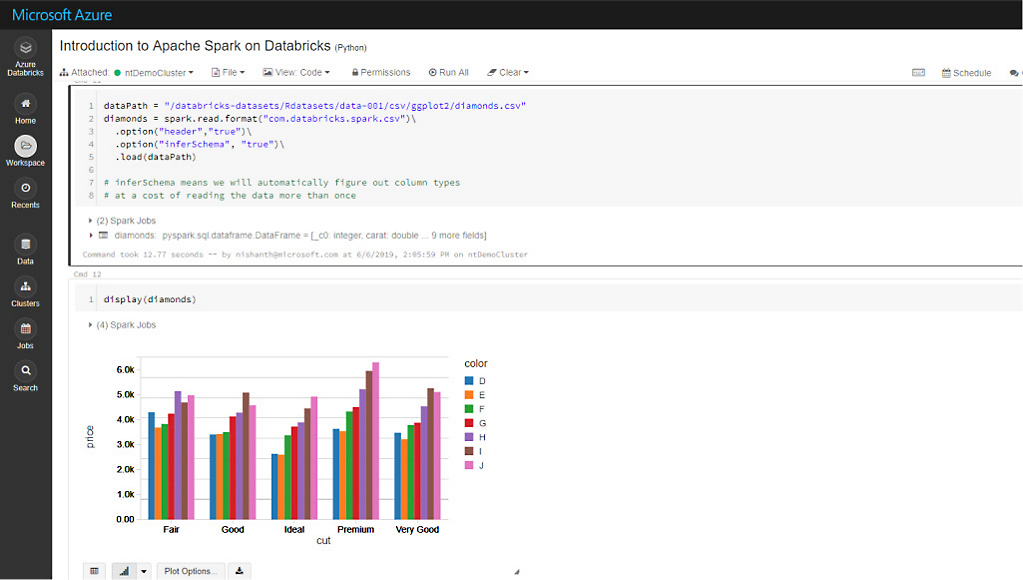
Geef je productiviteit een boost met een gedeelde werkruimte en veelgebruikte programmeertalen
Effectief samenwerken op een open en geïntegreerd platform om alle typen analyseworkloads uit te voeren, of je nu een datawetenschapper, data-engineer of bedrijfsanalist bent. Ontwikkel met je favoriete programmeertaal, zoals Python, Scala, R of SQL. Krijg eenvoudig versiebeheer van notebooks met GitHub en Azure DevOps.
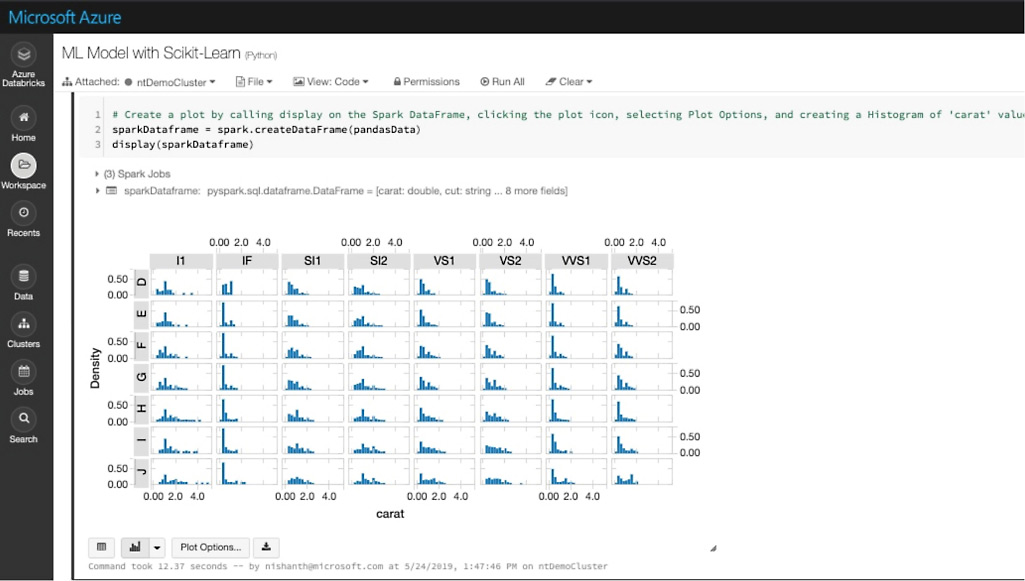
Machine learning over big data een boost geven
Krijg toegang tot geavanceerde geautomatiseerde machine learning-mogelijkheden met behulp van het geïntegreerde Azure Machine Learning om snel geschikte algoritmen en hyperparameters te identificeren. Vereenvoudig het beheren, bewaken en bijwerken van machine learning-modellen die van de cloud naar de rand zijn geïmplementeerd. Azure Machine Learning biedt bovendien een centraal register voor je experimenten, machine learning-pijplijnen en -modellen.
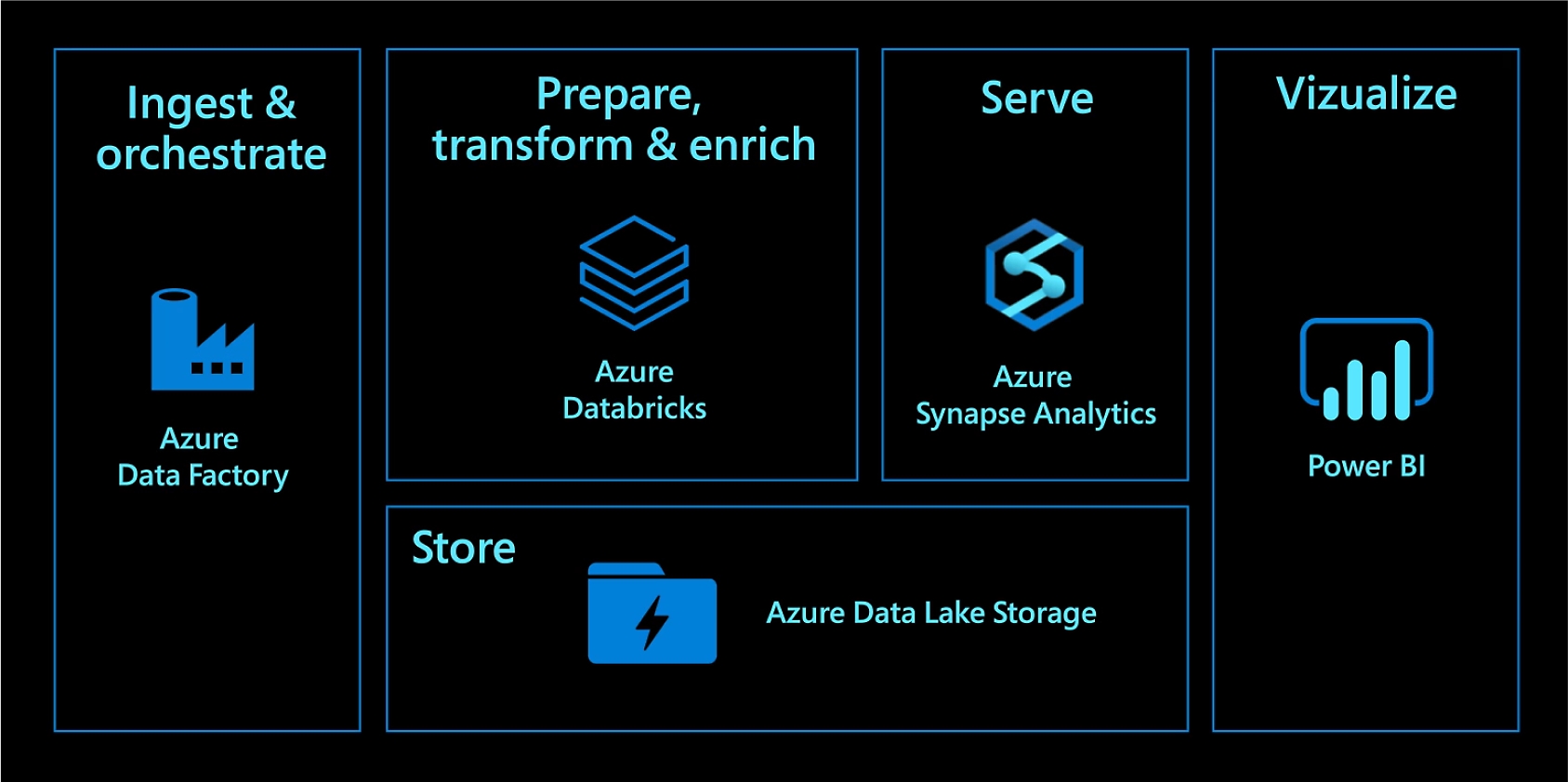
Krijg hoogpresterende moderne datawarehousing
Combineer gegevens op elke schaal en krijg inzicht door middel van analytische dashboards en operationele rapporten. Automatiseer gegevensverplaatsing met Azure Data Factory, laad vervolgens gegevens in Azure Data Lake Storage, transformeer en schoon deze gegevens op met Azure Databricks en maak ze beschikbaar voor analyse met behulp van Azure Synapse Analytics. Moderniseer je datawarehouse in de cloud voor ongeëvenaarde prestatie- en schaalbaarheidsniveaus.
Belangrijkste servicemogelijkheden
-
Geoptimaliseerde Spark-engine
Eenvoudige gegevensverwerking op een infrastructuur waarvan de schaal zich automatisch aanpast, en die werkt met een maximaal geoptimaliseerde Apache Spark™ voor tot wel 50x betere prestaties.
-
Uitvoeringstijd van machine learning
Met één klik heb je toegang tot vooraf geconfigureerde machine learning-omgevingen voor uitgebreidere machine learning met hoogwaardige en populaire frameworks zoals PyTorch, TensorFlow en scikit-learn.


-
MLflow
Je kunt experimenten volgen en delen, de uitvoering ervan reproduceren en modellen gezamenlijk beheren vanuit een centrale opslagplaats.
-
Keuze uit talen
Gebruik je voorkeurstaal, zoals Python, Scala, R, Spark SQL of .NET, ongeacht of je serverloze of ingerichte rekenresources gebruikt.


-
Notebooks voor samenwerking
Krijg snel toegang tot en verken gegevens, kom tot nieuwe inzichten en deel deze, en bouw samen met anderen aan modellen in de programmeertalen en hulpprogramma's van je keuze.
-
Delta Lake
Breng de betrouwbaarheid van gegevens en schaalbaarheid over naar je bestaande data lake via een open source transactionele opslaglaag, ontworpen voor de volledige levenscyclus van gegevens.


-
Systeemeigen integratie met Azure-services
Maak je oplossing voor end-to-end analyse en machine learning compleet door een diepgaande integratie uit te voeren met Azure-services, zoals Azure Data Factory, Azure Data Lake Storage, Azure Machine Learning en Power BI.
-
Interactieve werkruimten
Maakt naadloze samenwerking tussen datawetenschappers, data-engineers en bedrijfsanalisten mogelijk.


-
Beveiliging van ondernemingsniveau
De soepel werkende systeemeigen beveiliging beschermt je gegevens op de locatie waar deze zich bevinden, en voorziet in compatibele, persoonlijke en geïsoleerde analysewerkruimten voor duizenden gebruikers en gegevenssets.
-
Productieklaar
Voer vol vertrouwen je meest bedrijfskritieke gegevensworkloads uit op een vertrouwd gegevensplatform, met ecosysteemintegraties voor CI/CD en bewaking.


Leer meer van voorbeelden van oplossingsarchitectuur

Datawetenschap en machine learning met Azure Databricks
Verkrijg eenvoudig inzichten uit live-streaminggegevens. Leg continu gegevens vast vanuit een IoT-apparaat of in logboeken vanuit klikgedrag op websites en verwerk deze in bijna realtime.

Moderne analysearchitectuur met Azure Databricks
Transformeer je gegevens in bruikbare inzichten met behulp van eersteklas hulpprogramma's voor machine learning. Met deze architectuur kun je elk soort gegevens op elke schaal combineren, en aangepaste machine learning-modellen op schaal bouwen en implementeren.

Opname-, ETL- en stroomverwerkingspijplijnen met Azure Databricks
Versnel en beheer de levenscyclus van machine learning van begin tot eind met Azure Databricks, MLflow en Azure Machine Learning om machine learning-toepassingen te ontwikkelen, delen, implementeren en beheren.
Uitgebreide ingebouwde beveiliging en compliance
-
Microsoft investeert jaarlijks meer dan USD 1 miljard in onderzoek en ontwikkeling van cyberbeveiliging.


-
Er werken meer dan 3500 beveiligingsexperts bij ons die allemaal zijn toegewijd aan de beveiliging en privacy van je gegevens.

-
Azure heeft meer certificeringen dan welke cloudprovider ook. Bekijk de uitgebreide lijst.
Meer informatie over Azure Databricks-producten en -services

Azure Data Factory
Hybride gegevensintegratieservice voor vereenvoudigde ETL op schaal.

Azure Data Lake Storage Gen 2
Sterk schaalbare, veilige Data Lake-functionaliteit op basis van Azure Blob Storage.

Azure Machine Learning
Machine learning-service van ondernemingsniveau om modellen sneller te bouwen en implementeren.

Power BI
Voeg analyse en interactieve rapportage toe aan je toepassingen.
-
Prijzen van Azure Databricks
Creëer snel clusters en pas de schaal automatisch omhoog of omlaag aan op basis van je gebruiksbehoeften. Verken alle Azure Databricks-prijsopties.

Aan de slag met een gratis Azure-account
1

2

Stap na je tegoed over naar betalen per gebruik om te blijven gebruikmaken van deze services. Betaal alleen als je meer dan de gratis maandelijkse bedragen gebruikt.
3

Community en ondersteuning voor Azure
Stel vragen en krijg ondersteuning van Microsoft-engineers en experts uit de Azure-community op MSDN Forum en Stack Overflow of neem contact op met de ondersteuning voor Azure.
Populaire labs en sjablonen
Ontdek labs die je in eigen tempo kunt uitvoeren en populaire snelstartsjablonen voor algemene configuraties gemaakt door Microsoft en de community.
Azure Databricks-resources verkennen
Veelgestelde vragen over Azure Databricks
-
Gegarandeerde beschikbaarheid van 99,95% met de Azure Databricks-SLA.
-
Een Databricks-eenheid (DBU) is een verwerkingscapaciteit (berekend per uur). Kosten worden doorberekend op basis van het aantal gebruikte seconden.
-
Een Data Engineering-workload is een taak waarbij het cluster waarop het wordt uitgevoerd automatisch wordt gestart en beëindigd. Een workload kan bijvoorbeeld worden geactiveerd door de Azure Databricks-taakplanner. Er wordt dan speciaal voor de taak een Apache Spark-cluster gemaakt. Wanneer de taak is voltooid, wordt het cluster automatisch weer beëindigd.
De Data Analytics-workload is niet geautomatiseerd. Opdrachten in Azure Databricks-notebooks worden bijvoorbeeld op Apache Spark-clusters uitgevoerd totdat ze handmatig worden beëindigd. Meerdere gebruikers kunnen een cluster delen om deze gezamenlijk te analyseren.