
Si vous êtes confronté à des problèmes d'accès aux données qui vous empêchent d'exécuter des tâches de calcul haute performance (HPC) dans Azure, nous avons une excellente nouvelle à vous annoncer. Le service Microsoft Azure HPC Cache, désormais disponible, vous permet d'exécuter vos charges de travail les plus exigeantes dans Azure sans avoir à réécrire vos applications (ce qui se traduit par un gain de temps et d'argent), et en stockant les données là où vous le souhaitez (dans Azure ou sur votre espace de stockage local). En réduisant la latence entre le calcul et le stockage, le service HPC Cache vous permet d'accéder en toute transparence aux données à haut débit nécessaires à l'exécution de vos applications HPC dans Azure.
Utilisez Azure pour accroître votre capacité d'analyse, sans vous soucier de l'accès aux données.
La plupart des équipes HPC sont conscientes du potentiel de l'expansion dans le cloud en matière d'accroissement de la capacité d'analyse. Tandis que de nombreuses organisations profitent des avantages qu'offre l'exécution des travaux de calcul dans le cloud en termes de capacité et d'évolutivité, les utilisateurs sont freinés par la taille de leurs jeux de données et la complexité de l'accès à ceux-ci, qui sont généralement stockés sur des périphériques de stockage NAS déployés depuis longtemps. Ces environnements NAS contiennent souvent des pétaoctets de données collectées sur une longue période et représentent un investissement important en termes d'infrastructure.
C'est là que le service HPC Cache peut vous aider. Considérez ce service comme un cache de périmètre qui fournit un accès à faible latence aux données des fichiers POSIX provenant d'un ou plusieurs emplacements, comme des périphériques de stockage NAS locaux et des données archivées dans Stockage Blob Azure. Le service HPC Cache facilite l'utilisation d'Azure pour accroître le débit d'analyse, même lorsque la taille et l'étendue de vos données exploitables augmentent.
Suivre l'accroissement de la taille et de l'étendue des données exploitables
Dans certains secteurs, comme les sciences du vivant, le rythme d'acquisition de nouvelles données continue d'accroître la taille et l'étendue des données exploitables. Dans ce cas, les données exploitables peuvent être des jeux de données qui nécessitent une analyse et une interprétation postérieures à la collecte et qui, à leur tour, stimulent l'activité en amont. Un génome séquencé peut atteindre des centaines de gigaoctets, par exemple. À mesure que le rythme des activités de séquençage augmente et devient plus parallèle, la quantité de données à stocker et à interpréter augmente également - et votre infrastructure doit suivre le rythme. Votre capacité à collecter, traiter et interpréter des données exploitables (votre capacité d'analyse) a un impact direct sur la capacité de votre organisation à répondre aux besoins de ses clients et à tirer parti des nouvelles opportunités commerciales.
Pour répondre à l'évolution de leurs besoins en matière de débit d'analyse, certaines organisations continuent à déployer un environnement HPC local toujours plus robuste, avec une mise en réseau à haute vitesse et un stockage performant. Mais pour de nombreuses entreprises, l'expansion des environnements locaux génère des défis de plus en plus complexes et coûteux. Par exemple, comment prévoir avec précision les nouveaux besoins en capacité et y répondre de façon plus économique ? Comment jongler au mieux avec les cycles de vie des équipements lorsque la demande explose ? Comment s'assurer que le stockage répond (en termes de latence et de débit) aux demandes de calcul ? Et comment gérer tout cela avec un budget et des ressources humaines limités ?
Les services Azure peuvent vous aider à étendre plus facilement et à moindre coût votre débit d'analyse au-delà de la capacité de l'infrastructure HPC existante. Vous pouvez utiliser des outils tels qu'Azure CycleCloud et Azure Batch pour orchestrer et planifier les travaux de calcul sur des machines virtuelles Azure. Gérez plus efficacement vos coûts et procédez aux mises à l'échelle à l'aide de machines virtuelles basse priorité et de groupes de machines virtuelles identiques Azure. Utilisez les dernières machines virtuelles des séries H et N d'Azure pour répondre aux exigences de performances de vos charges de travail les plus complexes.
Alors, par où commencer ? C'est très simple. Connectez votre réseau à Azure via ExpressRoute, déterminez les machines virtuelles à utiliser et coordonnez les processus à l'aide de CycleCloud ou de Batch. Voilà, votre environnement HPC expansible est prêt. Il ne vous reste plus qu'à l'alimenter en données. Et c'est à ce moment-là que vous avez besoin du service HPC Cache.
Utiliser HPC Cache pour un accès rapide et cohérent aux données
La plupart des organisations reconnaissent les avantages de l'utilisation du cloud : un environnement HPC expansible peut accroître votre capacité d'analyse sans nécessiter de nouveaux investissements en capital. Et Azure offre des avantages supplémentaires en vous permettant de tirer parti de vos planificateurs actuels ainsi que d'autres outils pour assurer la cohérence du déploiement avec votre environnement local.
Cela dit, vos bibliothèques, vos applications et l'emplacement des données peuvent nécessiter la même cohérence. Dans certaines circonstances, un pipeline d'analyse local peut s'appuyer sur des chemins POSIX qui doivent être identiques, qu'ils soient exécutés dans Azure ou localement. Certaines données situées dans des répertoires différents peuvent être liées les unes aux autres, et il peut être nécessaire de déployer ces liens de la même manière dans le cloud. Les données proprement dites peuvent être situées à différents emplacements, et il peut être nécessaire de les regrouper. Mais surtout, la latence d'accès doit être cohérente avec ce qui peut être réalisé dans l'environnement HPC local.
Pour comprendre comment le service HPC Cache répond à ces exigences, considérez-le comme un cache de périmètre qui fournit un accès à faible latence aux données de fichiers POSIX provenant d'un ou de plusieurs emplacements. Par exemple, un environnement local peut contenir un grand cluster HPC connecté à une solution NAS commerciale. HPC Cache permet l'accès depuis cette solution NAS aux machines virtuelles Azure, aux conteneurs ou aux routines d'apprentissage automatique exécutés sur une liaison WAN. Pour ce faire, le service met en cache les requêtes des clients (y compris des machines virtuelles) et veille à que les accès ultérieurs à ces données soient gérés par le cache plutôt que par un nouvel accès à l'environnement NAS local. Vous pouvez ainsi exécuter vos travaux HPC à un niveau de performances semblable à celui que vous obtiendriez dans votre propre centre de données. HPC Cache vous permet également de créer un espace de noms constitué de données issues de différentes exportations et de différentes sources, tout en affichant une structure de répertoires unique sur les ordinateurs clients.
HPC Cache fournit également dans Azure un cache basé sur des objets blob (Blob-as-POSIX) qui facilite la migration des pipelines basés sur des fichiers sans qu'il soit nécessaire de réécrire les applications. Par exemple, une équipe de recherche en génétique peut charger des données de génome de référence dans l'environnement Blob afin d'optimiser les performances des workflows d'analyse secondaires. Cela permet d'atténuer les problèmes de latence lorsque vous lancez de nouveaux travaux reposant sur un ensemble statique de bibliothèques ou d'outils de référence.
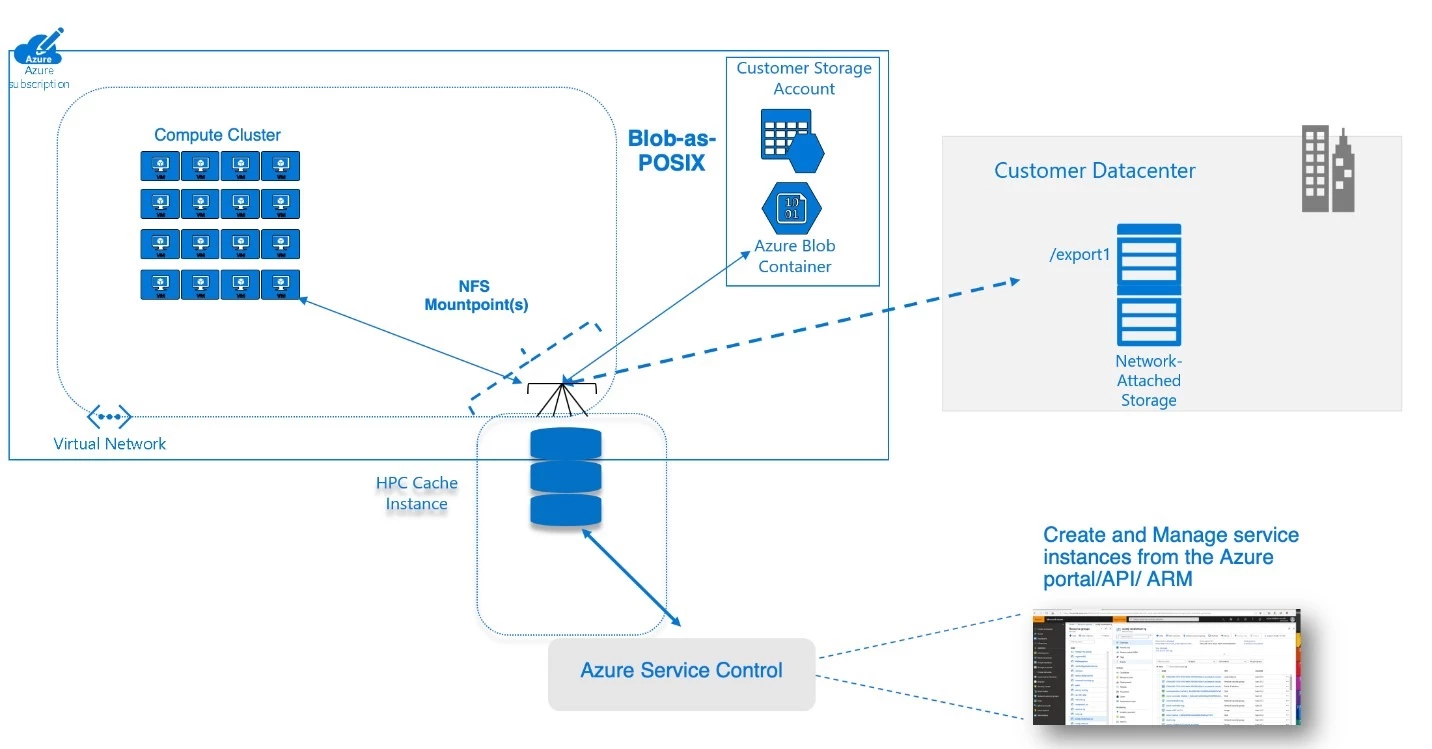
Architecture Azure HPC Cache
Avantages du service HPC Cache
Débit de mise en cache pour répondre aux exigences des charges de travail
HPC Cache propose trois références SKU : jusqu'à 2 gigaoctets par seconde (Go/s), jusqu'à 4 Go/s et jusqu'à 8 Go/s. Chacune de ces références SKU peut traiter des demandes allant de plusieurs dizaines à plusieurs milliers de machines virtuelles, conteneurs, etc. De plus, vous choisissez la taille de vos disques de cache pour contrôler vos coûts tout en veillant à ce que la capacité adéquate soit disponible pour la mise en cache.
Expansion des données à partir de votre centre de données
HPC Cache récupère les données de votre solution NAS, où qu'elles se trouvent. Exécutez votre charge de travail HPC aujourd'hui et déterminez vos stratégies de stockage de données à long terme.
Connectivité haute disponibilité
HPC Cache fournit aux clients une connectivité haute disponibilité (HA), condition essentielle à l'exécution de travaux de calcul à plus grande échelle.
Espace de noms agrégé
La fonctionnalité d'espace de noms agrégé du service HPC Cache vous permet de créer un espace de noms à partir de diverses sources de données. Cette abstraction des sources permet d'exécuter plusieurs environnements HPC Cache avec une vue cohérente des données.
Stockage à moindre coût, compatibilité POSIX totale avec Blob-as-POSIX
HPC Cache prend en charge le stockage basé sur les objets blob et entièrement compatible POSIX. Avec le format Blob-as-POSIX, HPC Cache offre une prise en charge complète de POSIX, y compris des liens physiques. Si vous avez besoin de ce niveau de conformité, vous pourrez bénéficier d'une prise en charge complète de POSIX aux prix Blob.
Démarrer ici
Le service Azure HPC Cache est accessible dès maintenant. Pour des résultats optimaux, contactez votre équipe Microsoft ou ses partenaires. Ils vous aideront à créer une architecture complète qui répondra au mieux aux objectifs stratégiques et aux résultats attendus par votre organisation.
Nos experts seront présents au salon SC19, le sommet mondial du HPC, qui se tiendra à Denver, dans le Colorado, pour vous aider à accélérer vos charges de travail basées sur des fichiers dans Azure.