
This blog post has been co-authored by Jeffrey He, Product Manager, AIOps Platform and Experiences Team.
In Microsoft Azure, we invest tremendous efforts in ensuring our services are reliable by predicting and mitigating failures as quickly as we can. In large-scale cloud systems, however, we may still experience unexpected issues simply due to the massive scale of the system. Given this, using AIOps to continuously monitor health metrics is fundamental to running a cloud system successfully, as we have shared in our earlier posts. First, we shared more about this in Advancing Azure service quality with artificial intelligence: AIOps. We also shared an example deep dive of how we use AIOps to help Azure in the safe deployment space in Advancing safe deployment with AIOps. Today, we share another example, this time about how AI is used in the field of anomaly detection. Specifically, we introduce AiDice, a novel anomaly detection algorithm developed jointly by Microsoft Research and Microsoft Azure that identifies anomalies in large-scale, multi-dimensional time series data. AiDice not only captures incidents quickly, it also provides engineers with important context that helps them diagnose issues more effectively, providing the best experience possible for end customers.
Why are AIOps needed for anomaly detection?
We need AIOps for anomaly detection because the data volume is simply too large to analyze without AI. In large-scale cloud environments, we monitor an innumerable number of cloud components, and each component logs countless rows of data. In addition, each row of data for any given cloud component might contain dozens of columns such as the timestamp, the hardware type of the virtual machine, the generation number, the OS version, the datacenter where the nodes hosting the virtual machine stay in, or the country. The structure of the data we have is essentially multi-dimensional time series data, which contains an exponential number of individual time series due to the various combinations of dimensions. This means that iterating through and monitoring every single time series is simply not practical—applying AIOps is necessary.
How did we approach this, before AiDice?
Before AiDice, the way we handled anomaly detection in large-scale, high-dimensional time series data was to conduct anomaly detection on a selected set of dimensions that were the most important. By focusing on a scoped subset, we would be able to detect anomalies within those combinations quickly. Once these anomalies were detected, engineers would then dive deeper into the issues, using pivot tables to drill down into the other dimensions not included to better diagnose the issue. Although this approach worked, we saw two key opportunities to improve the process. First, the old approach required a lot of manual effort by engineers to determine the exact pivot of anomalies. Second, the approach also limited the scope of direct monitoring by only allowing us to input a limited number of dimensions into our anomaly detection algorithms. Given these reasons, Microsoft Research and Azure worked together to develop AiDice, which improves both of these areas.
How do we approach this now with AiDice, and how does it work?
Now with AiDice, we can automatically localize pivots on time series data even if looking at dozens of dimensions at the same time. This allows us to add a lot more attributes, whether that be the hardware generation or hardware microcode, the OS version, or the networking agent version. Though this makes the search space much larger, AiDice encodes the problem as a combinatorial optimization problem, allowing it to search through the space more efficiently than traditional approaches. Brief details of AiDice are described below, but to see a full explanation of the algorithm, please see the paper published at the ESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2020).
Part 1: AiDice algorithm—formulation as a search problem
The AiDice algorithm works by first turning the data into a search problem. Search nodes are formed by starting at a given pivot and building the relationships out to the neighbors. For example, if we take a node, “Country=USA, Datacenter=DC1, DiskType=SSD”, we can form out the neighboring nodes by swapping, adding, or removing a dimension-value pair, as shown in the diagram below.

Part 2: AiDice algorithm—objective function
Next, the AiDice algorithm searches through the search space in a smart manner by maximizing an objective function that emphasizes two key components. First, the bigger the sudden burst or change in errors, the higher AiDice scores the objective function. Second, the higher the proportion of the errors that occur in this pivot in relation to the total number of errors, the higher AiDice scores the objective function. For example, if there are 5,000 total errors that occurred, it is more important to alert the user about the pivot that went from 3000 errors to 4000 errors than the pivot that went from 10 to 20 errors.
Part 3: Customization of alerts to reduce noise
Next, the alerts that AiDice produces need to be filtered and customized to be less noisy and more actionable since the results so far are optimized from a mathematical perspective but have not yet incorporated domain knowledge around the meaning of the input data. This step can vary widely depending on the nature of the input data, but an example could be that consecutive alerts that share the same error code may be grouped together to reduce the number of total alerts.
AiDice in action—an example
The following is a real example in which AiDice helped detect a real issue early on. The details are altered for confidentiality reasons.
- We applied AiDice to monitor low memory error events in a certain type of virtual machine with more than a dozen dimensions of attribute information alongside the fault count, including the region, the datacenter location, the cluster, the build, the RAM, or the event type.
- AiDice identified an increase in the number of low memory events on distinct nodes in a particular pivot, which indicated a memory leak.
- Build=11.11111, Ram=00.0, ProviderName=Xxxxx-x-Xxxxxx, EventType=8888 (details have been altered for privacy).
- When looking at the aggregate trend, this issue is hidden and without AiDice it would take manual effort to detect the exact location of the issue (see graphs below, data normalized for privacy).
- The engineer responsible for the ticket looked at the alert and some example cases shown in the alerts to quickly able figure out what was going on.
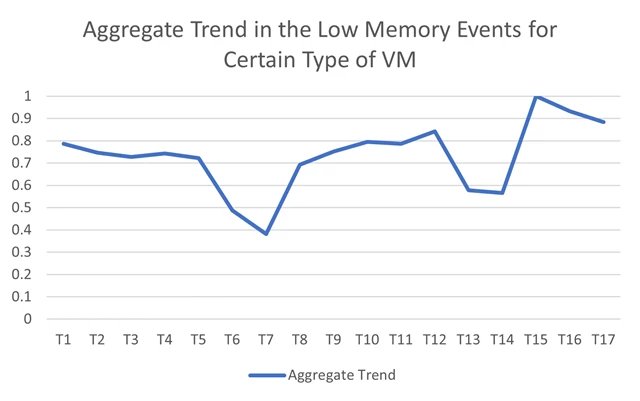
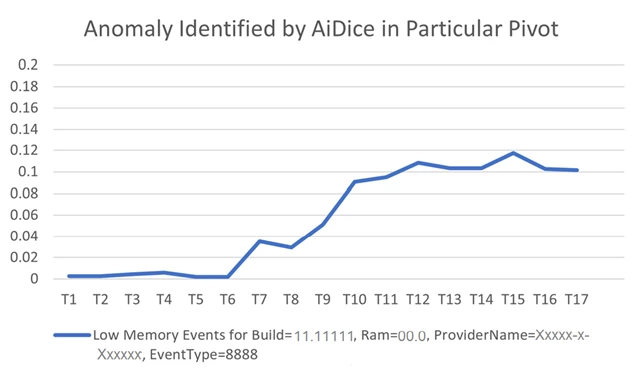
In this real-world example, AiDice was able to detect an issue in a dimension combination that was causing a particular error type in an automatic fashion, quickly and efficiently. Soon after, the memory leak was discovered and Azure engineers were able to mitigate the issue.
Looking forward
Looking ahead, we hope to improve AiDice to make Azure even more resilient and reliable. Specifically, we plan to:
- Support additional scenarios in Azure: AiDice is being applied to many scenarios in Azure already, but the algorithm has room to improve with respect to the types of metrics it can operate on. Microsoft Azure and the Microsoft Research team are working together to support more metric scenarios.
- Prepare additional data feeds in Azure for AiDice: In addition to upgrading the AiDice algorithm itself to support more scenarios, we are also working to add supporting attributes to certain data sources to fully leverage the power of AiDice.
Learn more
- Sign up for Microsoft Azure today.
- Visit the Advancing Reliability Series.