Azure AI Vision
Discover computer vision insights from image and video analysis with OCR and AI.
Elevate your computer vision projects
Azure AI Vision is a unified service that offers innovative computer vision capabilities. Give your apps the ability to analyze images, read text, and detect faces with prebuilt image tagging, text extraction with optical character recognition (OCR), and responsible facial recognition. Incorporate vision features into your projects with no machine learning experience required.
Boost content discoverability with image analysis
Automatically caption images with natural language, use smart crop, and classify images (in preview).


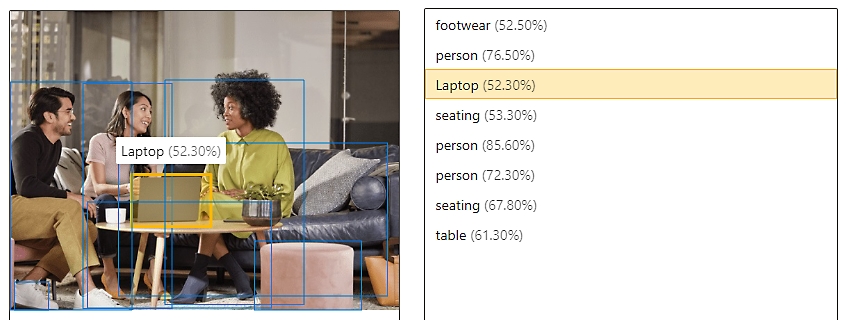

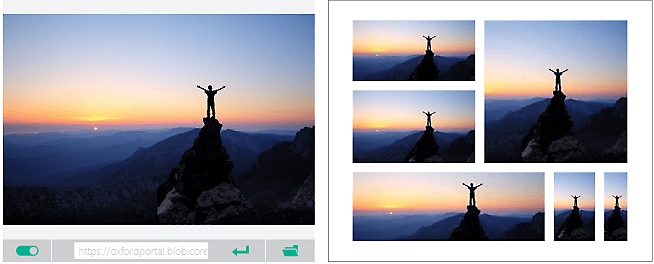

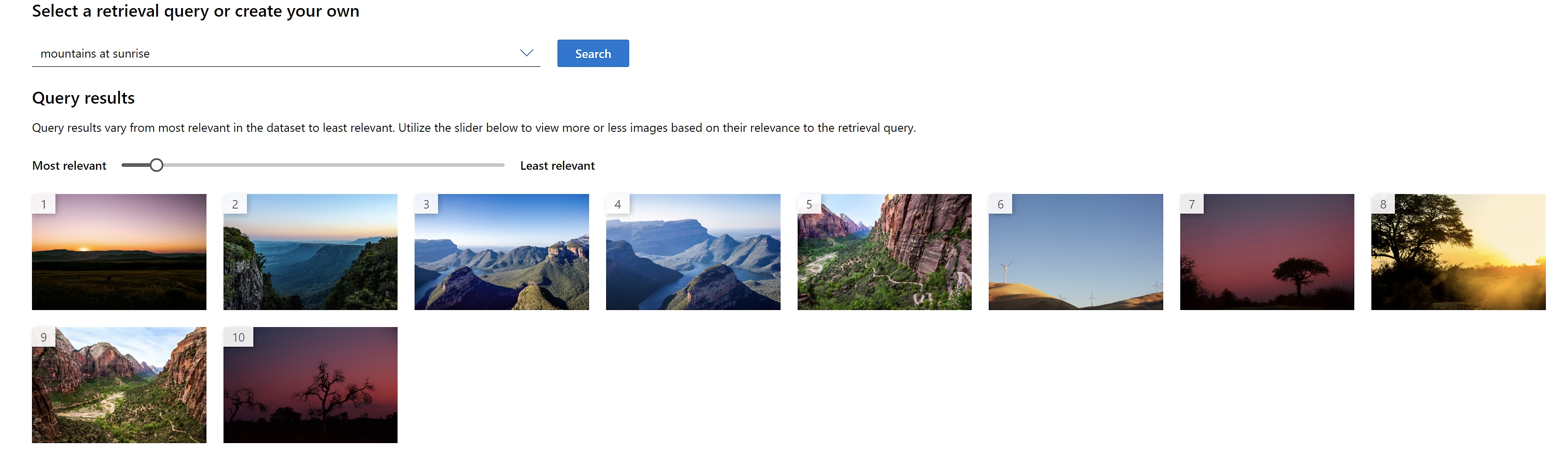
Stream video in real time with spatial analysis
Track movement and analyze environments in real time using computer vision with image analysis and object detection.
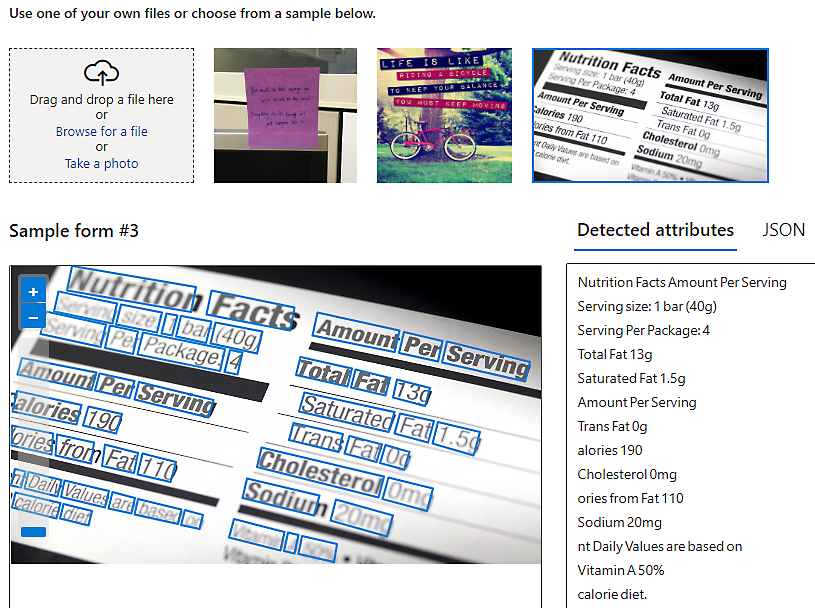
Read text from images with optical character recognition (OCR)
Extract printed and handwritten text from images with mixed languages and writing styles using OCR technology.
Verify identities with facial recognition
Create apps with facial recognition for a seamless and highly secure user experience.
Train custom computer vision models
Customize image classification and object detection to fit your needs with just a handful of images and without compromising accuracy (in preview).


Apply AI responsibly
Get clear guidance on how to use computer AI Vision responsibly to meet your goals and achieve accurate results.
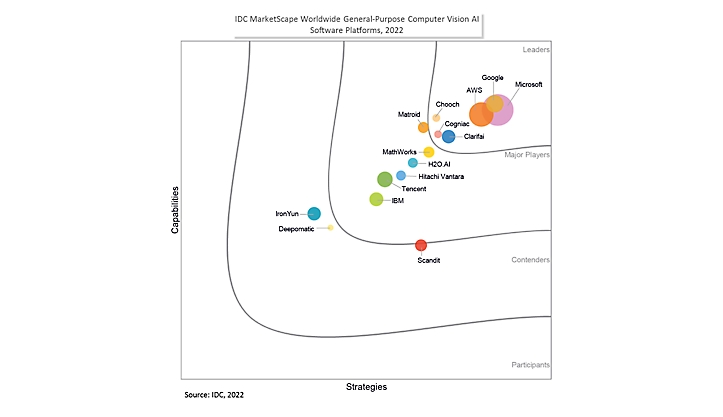
Microsoft is named a Leader in the IDC MarketScape: Worldwide General-Purpose Computer Vision AI Software Platform 2022 Vendor Assessment
The IDC MarketScape report evaluated Microsoft’s strategies and capabilities and positioned Microsoft in the Leaders category. We believe this recognition underscores Microsoft’s commitment to deliver cutting-edge, responsible, and customer-centric AI products to organizations of all sizes and across all verticals.

Fuel App Innovation with Cloud AI Services
Read this 2022 commissioned study conducted by Forrester Consulting to learn how to help developers of any skill level at your organization deploy AI solutions quickly using prebuilt, production-ready cloud AI services.
Comprehensive security and compliance, built in
-
Microsoft invests more than USD 1 billion annually on cybersecurity research and development.

-
We employ more than 3,500 security experts who are dedicated to data security and privacy.

-
Azure has more certifications than any other cloud provider. View the comprehensive list.
-
ISO/IEC
-
CSA/CCM
-
ITAR
-
CJIS
-
HIPAA
-
IRS 1075






-
Azure AI Vision pricing
Pay for only what you use with no upfront costs. Azure AI Vision uses a pay-as-you-go consumption model based on number of transactions. Learn more about pricing for Computer Vision and Face API.

Get started with an Azure free account
1

2

After your credit, move to pay as you go to keep building with the same free services. Pay only if you use more than your free monthly amounts.
3

Trusted across industries, by companies of all sizes




USA Surfing Joins the AI Wave
“Coaches look at these elements. They look at the compression of the body. They look at various dynamic factors. These machine learning models, by measuring angles between the joints of the body while performing surf manuevers, can actually help coaches to provide feedback,” — Kevin Schulz, Aerial Phenom and Surfer, Team USA

KPMG helps banking customers identify financial risk
With AI Vision, KPMG finds and analyzes images and videos and uses optical character recognition (OCR) APIs to identify risk.

H&R Block uses Azure AI to transform tax returns
“Give us a shoebox of tax documents, and we’ll use AI and machine learning to put the data in the right places.”
Sameer Agarwal: IT Director, H&R Block

Reddit improves accessibility and SEO with image and caption generation
"The newly created image captions make Reddit more accessible and give redditors more opportunities to explore our images, engage in conversations, and ultimately build connections and community."
Tiffany Ong: Product Manager of Guest Experience & SEO, Reddit

Documentation and resources
Get started
Read the documentation
Take the Microsoft Learn courses
Explore samples
Read the quickstart guide
Browse code samples
Guidance
Read the facial recognition transparency note
Frequently asked questions about Azure AI Vision
-
-
Azure AI Vision and other Azure AI Services offerings guarantee 99.9 percent availability. No SLA is provided for the Free pricing tier. See SLA details.
-
No. Microsoft automatically deletes your images and videos after processing and does not train on your data to enhance the underlying models. Video data does not leave your premises, and video data is not stored on the edge where the container runs. Learn more about privacy and terms of usage.
-
No, spatial analysis detects and locates human presence in video footage and outputs a bounding box around each person detected. The AI models do not detect faces nor determine individuals’ identities nor demographics.
-
The spatial analysis AI models detect and track movements in the video feed based on algorithms that identify the presence of one or more humans by a body bounding box. For each person and bounding box detected in a zone in the camera field of view, the AI models output event data including bounding box coordinates of a person’s body, event type (for example, zone entry or exit, or directional line crossing), pseudonymous identifiers to track the bounding box, and a detection confidence score. This event data is sent to your own instance of Azure IoT Hub.
-
Yes. Because model customization is designed to be fine-tuned for your scenario, you need to provide the labeled data to train your model.
-
The model customization feature of the service is optimized to quickly recognize major differences between images, so you can start prototyping your model with a small amount of data. You may start with as little as one image per label. If you have more labeled images, you may add more. Depending on the complexity of the problem and degree of accuracy required, you can continue adding additional images per label to improve your model.
-
It’s both. You can use the site to access a graphical interface for managing datasets, training, and evaluation of models for a no-code experience, or, as an alternative, you can use the Computer Vision APIs.
-
You can label the images in Azure Machine Learning Studio, which is integrated with Vision Studio for easy export of labeled data. You can also label the data in the COCO file format and import the COCO file directly in Vision Studio. See documentation for details.
-
The model customization feature for Azure AI Vision is the next generation of Custom Vision, with improved accuracy and few-shot learning capabilities. You may continue to use Custom Vision, or you can migrate your training data to retrain your model with model customization from Azure AI Vision. See documentation for details.
-
After using Azure AI Vision to extract insights and text from images and video, you can use text analytics to analyze sentiment, Translator to translate text into your desired language, or Immersive Reader to read the text aloud, making it more accessible. Related services and capabilities include Azure Form Recognizer to extract key-value pairs and tables from documents, Azure AI Video Indexer for extracting advanced metadata from audio and video files, and Content Moderator to detect unwanted text or images.