
Da containerisierte Umgebungen immer komplexer werden, kann es immer schwieriger werden, die Ursache von Netzwerkproblemen innerhalb eines Kubernetes-Clusters zu identifizieren. Zeitweilige Fehler und Leistungsengpässe können besonders frustrierend sein, und eine umfassende Sichtbarkeit der Netzwerkinfrastruktur kann oft wie eine entmutigende Aufgabe erscheinen. Viele Organisationen greifen sich mit diesen Herausforderungen auseinander und haben schwierigkeiten, effektive Lösungen zu finden, um sie zu beheben.
Um dies zu beheben, freuen wir uns, die Verfügbarkeit von Azure Kubernetes Service (AKS) – Network Observability – bekanntzugeben. Dieses Feature bietet Kunden leistungsstarke Funktionen, um einen verbesserten Einblick in ihren Containernetzwerkdatenverkehr zu erhalten. Durch die Bereitstellung von Echtzeiteinblicken und umfassenden Netzwerkmetriken ermöglicht dieses Feature Administratoren und Entwicklern, Netzwerkprobleme effektiv zu beheben und die Leistung ihrer containerisierten Anwendungen zu optimieren.
In diesem Blogbeitrag werden wir uns in AKS mit den Details dieses spannenden neuen Features der Netzwerk-Observability befassen. Wir werden die Funktionen, Anwendungsfälle und die Vorteile dieses Features untersuchen.
Was ist Network Observability für AKS?
Die Netzwerküberwachungsfunktion in AKS ist eine verteilte Überwachungslösung, die sowohl für Linux- als auch für Windows-Hostingumgebungen funktioniert. Dieses Add-On erhält Einblicke in die Netzwerkinfrastruktur, indem sie Echtzeitdatenpunkte sammeln, die eBPF in Linux, Virtual Filtering Platform (VFP) und Host Networking Service (HNS) in Windows nutzen und diese in Prometheus und Grafana nutzen können.
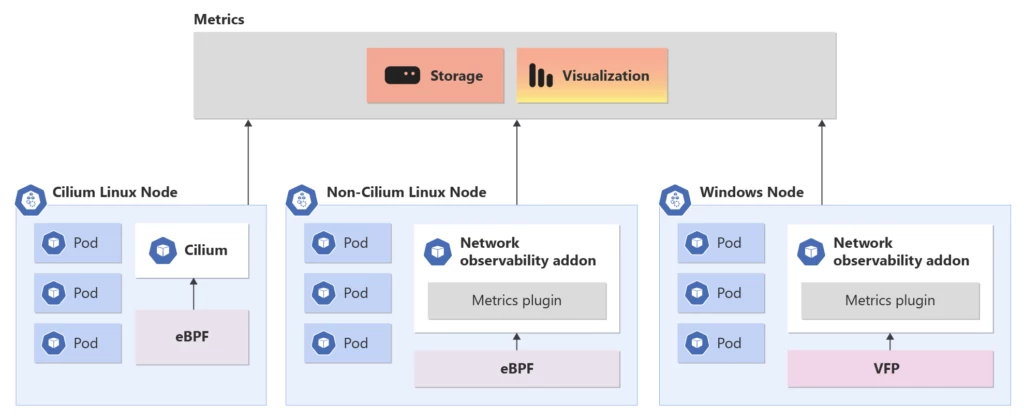
Visualisieren von Daten zur Netzwerkbeobachtung
Azure Managed Prometheus und Grafana:
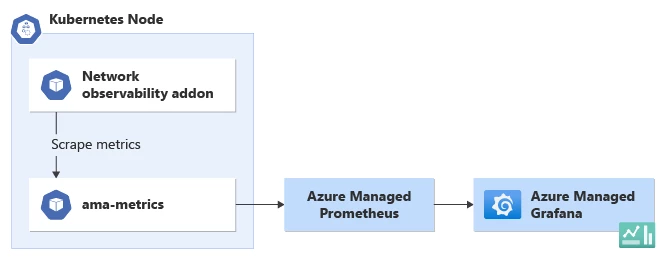
Mit dem von Azure verwalteten Prometheus - und Grafana-Ansatz bietet Microsoft Azure integrierte Dienste, die das Einrichten und Verwalten von Überwachung und Visualisierung vereinfachen. Azure Monitor stellt eine verwaltete Instanz von Prometheus bereit, die Metriken aus verschiedenen Quellen sammelt und speichert, einschließlich des Addon zur Netzwerk observability. Grafana, eine beliebte Open-Source-Plattform für die Datenvisualisierung, ist nahtlos in Azure Monitor integriert. Benutzer können vorkonfigurierte Dashboards und Vorlagen nutzen, die speziell für AKS und das Netzwerk-Observability-Addon entwickelt wurden. Diese Dashboards bieten eine umfassende Ansicht der Netzwerkmetriken, sodass Benutzer die Daten visuell ansprechend und intuitiv überwachen und analysieren können.
Um die Netzwerkbeobachtbarkeit mit azureverwaltetem Prometheus- und Grafana-Ansatz einzurichten, können Die Benutzer der Azure-Dokumentation folgen. Nach der Konfiguration können sie auf die Grafana-Schnittstelle zugreifen, um die vordefinierten Dashboards zu erkunden oder benutzerdefinierte Visualisierungen zu erstellen, die auf ihre spezifischen Anforderungen zugeschnitten sind. Die Integration zwischen Azure Monitor, Prometheus und Grafana optimiert den Prozess der Visualisierung von Daten zur Netzwerkbeobachtbarkeit, sodass Benutzer wertvolle Einblicke in die Netzwerkleistung ihres AKS-Clusters erhalten können.
Bring your own (BYO) Prometheus and Grafana:
(Für erweiterte Benutzer mit erhöhtem Verwaltungsaufwand)
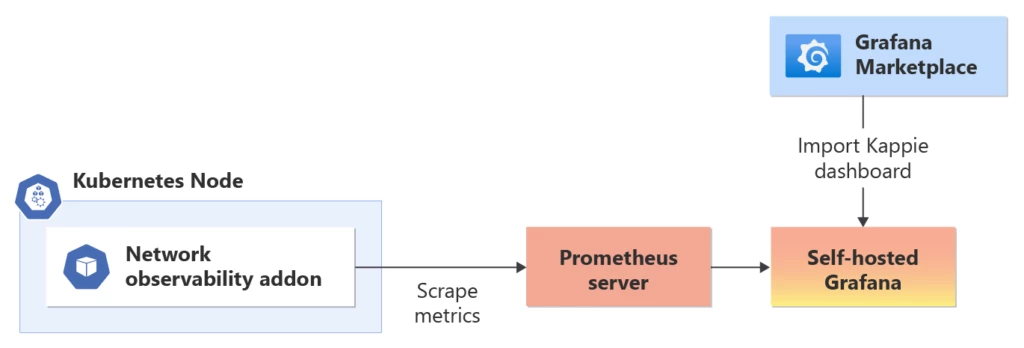
Alternativ können Benutzer ihre eigenen Prometheus- und Grafana-Instanzen einrichten und verwalten. Dieser Ansatz bietet mehr Flexibilität und Kontrolle über die Konfiguration und Anpassung des Überwachungs- und Visualisierungsstapels. Benutzer können Prometheus und Grafana als separate Komponenten in ihrer Infrastruktur bereitstellen oder containerisierte Versionen verwenden, die zusammen mit ihrem AKS-Cluster ausgeführt werden.
Das Einrichten eines BYO Prometheus umfasst das Konfigurieren von Prometheus, um die Metriken zu verwischen, die vom Addon für die Netzwerkbeobachtbarkeit verfügbar gemacht werden. Benutzer können Scrape-Konfigurationen definieren, um die relevanten Metriken zu sammeln und in der Zeitreihendatenbank von Prometheus zu speichern. Grafana kann dann mit Prometheus verbunden werden, um benutzerdefinierte Dashboards und Visualisierungen zu erstellen. Benutzer können ihre eigenen Grafana-Dashboards entwerfen oder von der Community bereitgestellte Vorlagen importieren, um die Metriken der Netzwerkbeobachtbarkeit basierend auf ihren spezifischen Überwachungsanforderungen und -einstellungen zu visualisieren. Benutzer können der Azure-Dokumentation folgen, um das Add-On "Netzwerk observability" mithilfe von BYO Prometheus und Grafana zu aktivieren und zu visualisieren.
Durch die Verwendung von BYO Prometheus und Grafana haben Benutzer die vollständige Kontrolle über die Bereitstellung, Konfiguration und Anpassung ihres Überwachungs- und Visualisierungsstapels. Dieser Ansatz ermöglicht erweiterte und maßgeschneiderte Visualisierungen von Netzwerk-Observability-Daten, sodass Benutzer fundierte Dashboards entwerfen können, die ihren einzigartigen Überwachungsanforderungen entsprechen.
Anwendungsfälle
Kundenszenario 1: Netzwerkrichtlinien fallen ab
Das Debuggen von Netzwerkrichtlinien in großen, komplizierten Clustern mit mehreren Namespaces kann eine entmutigende Aufgabe sein, insbesondere wenn es zahlreiche Netzwerkrichtlinien pro Namespace gibt. Um diese Herausforderung zu bewältigen, nutzt das Netzwerkrichtlinien-Addon eBPF in Linux, um wichtige Informationen über verworfene Pakete zu sammeln. Durch das Anfügen von Kprobes an verschiedenen kritischen Stellen im Linux-Kernel, z. B. der Netfilter-Drop-Funktion und der Netfilter-NAT-Funktion, bestimmt das Netzwerkrichtlinien-Addon effektiv, ob ein Paket verworfen wird.
Wenn ein verworfenes Paket erkannt wird, generieren die zugehörigen eBPF-Programme ein Ereignis, das Paketmetadaten enthält, sowie den Drop-Grund und den Speicherort. Dieses Ereignis wird dann von einem Userspace-Programm verarbeitet, das die Daten analysiert und in Prometheus-Metriken konvertiert. Diese Metriken bieten wertvolle Einblicke in die verworfenen Pakete, die die Identifizierung und Lösung von Netzwerkrichtlinienkonfigurationsproblemen unterstützen.
In Windows stellen VFP und HNS Zähler für Zugriffssteuerungslisten (Access Control List, ACL) oder Endpunktregelabbrüche bereit. Unser Netzwerk-Observability-Addon verschrottet diese Leistungsindikatoren und wandelt die Daten in Prometheus-Metriken um und stellt eine konsistente und umfassende Überwachung auf verschiedenen Plattformen sicher.
Um die Funktionen unserer Lösung zu veranschaulichen, betrachten Sie das folgende Beispiel, in dem verworfene Pakete aus verschiedenen Gründen dargestellt werden, z. B. IPTables oder ACL:
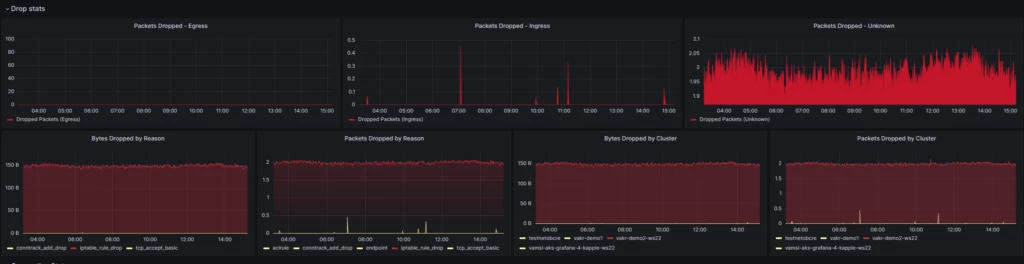
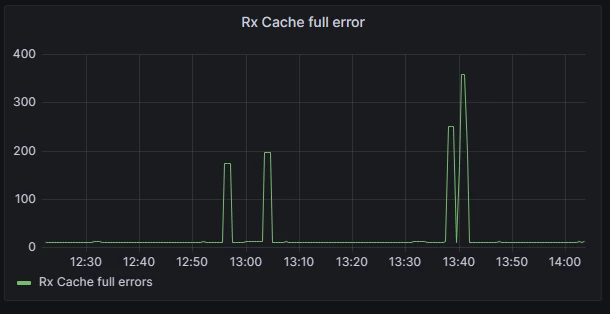
Kundenszenario 2: Vollständiges Empfangen des Caches
In Azure ist das beschleunigte Netzwerk standardmäßig für fast alle virtuellen Linux-Computer (VMs) aktiviert. Mit der Einführung von Accelerated Networking wird jeder Netzwerkschnittstelle ein dedizierter Speicherplatz für den Empfang von Paketen zugewiesen. Das Netzwerk-Observability-Addon spielt eine wichtige Rolle bei der Überwachung dieser Speicherzuordnung, indem die vollständige Rx-Cache-Statistik auf jeder Schnittstelle untersucht und in Prometheus-Metriken konvertiert wird. Dabei erhalten Benutzer wertvolle Einblicke in die Leistung ihrer Netzwerkschnittstellen.
Das folgende Diagramm veranschaulicht ein bestimmtes Szenario, in dem ein virtueller Computer mit seiner maximalen Kapazität arbeitet und Pakete mit der Zeilenrate empfängt. In solchen Fällen können Benutzer zeitweilige Latenzspitzen oder Paketabbrüche erleben. Durch schnelles Korrelieren dieser Informationen mit dem bereitgestellten Diagramm wird deutlich, dass der Empfangspuffer der Netzwerkschnittstelle gesättigt wird, wenn die Metrik "Rx-Puffer vollständig" gesättigt wird, was potenziell zu Paketabbrüchen oder einer Erhöhung der Latenz für Pakete führt, die auf die Verarbeitung warten.
Vorteile
Verbesserte Netzwerksichtbarkeit: Mit dem Addon "Netzwerkbeobachtbarkeit" können Benutzer tiefe Einblicke in ihre Netzwerkinfrastruktur gewinnen, sodass sie Probleme im Zusammenhang mit Netzwerkrichtlinien, Paketabbrüchen, Latenzspitzen und anderen leistungsbezogenen Problemen identifizieren und beheben können.
Verbesserte Debugfunktionen: Durch die Nutzung von eBPF und anderen Überwachungsmechanismen bietet das Addon wertvolle Einblicke in Netzwerkrichtlinienkonfigurationen, wodurch effizientes Debuggen und Problembehandlung ermöglicht werden. Benutzer können schnell falsch konfigurierte Netzwerkrichtlinien erkennen und sie umgehend beheben.
Echtzeitüberwachung und Warnung: Mit der Konvertierung von Metriken der Netzwerkbeobachtbarkeit in Prometheus-Metriken können Benutzer ihre Netzwerkleistung in Echtzeit überwachen. Sie können Warnungen und Benachrichtigungen einrichten, um anomalien proaktiv zu adressieren, um eine hohe Verfügbarkeit und optimale Leistung ihrer Netzwerkinfrastruktur sicherzustellen.
Plattformkompatibilität: Das Netzwerk-Observability-Addon wurde entwickelt, um nahtlos auf verschiedenen Plattformen, einschließlich Linux und Windows, zu arbeiten. Diese Kompatibilität ermöglicht es Benutzern, unabhängig vom zugrunde liegenden Betriebssystem eine konsistente Überwachungserfahrung in ihrer Infrastruktur zu Standard.
Historische Multicluster-Ansicht: Die Aktivierung mehrerer Cluster mit Netzwerkbeobachtbarkeits-Addon und die Verbindung mit demselben von Azure verwalteten Prametheus und Grafana wird in einem einzigen Glasbereich erleichtert, um die Netzwerkleistung aller Cluster im Laufe der Zeit zu visualisieren.
Weitere Informationen
Lesen Sie mehr in der Dokumentation zur Netzwerkbeobachtbarkeit, und Sie können auch eine Demo im Azure YouTube-Kanal von Microsoft ansehen.
- Erfahren Sie mehr über Azure Kubernete Service.
- Erkunden Sie Azure Linux , um mehr Einblicke zu erhalten.
- Erfahren Sie mehr über Azure Monitor.