This post was co-authored by Hugo Affaticati, Technical Program Manager, Microsoft Azure HPC + AI, and Jon Shelley, Principal TPM Manager, Microsoft Azure HPC + AI.
Natural language processing (NLP), automated speech recognition (ASR), and text-to-speech (TTS) applications are becoming increasingly common in today’s world. Most companies have leveraged these technologies to create chatbots for managing customer questions and complaints, streamlining operations, and removing some of the heavy cost burden that comes with headcount. But what you may not realize is they’re also being used internally to reduce risk and identify fraudulent behavior, reduce customer complaints, increase automation, and analyze customer sentiment. It’s prevalent in most places, but especially in industries such as healthcare, finance, retail, and telecommunications.
NVIDIA recently released the latest version of the NVIDIA NeMo Megatron framework, which is now in open beta. This framework can be used to build and deploy large language models (LLMs) with natural language understanding (NLU).
Combining NVIDIA NeMo Megatron with our Azure AI infrastructure offers a powerful platform that anyone can spin up in minutes without having to incur the costs and burden of managing their own on-premises infrastructure. And of course, we have taken our benchmarking of the new framework to a new level, to truly show the power of the Azure infrastructure.
Reaching new milestones with 530B parameters
We used Azure NDm A100 v4-series virtual machines to run the GPT-3 model’s new NVIDIA NeMo Megatron framework and test the limits of this series. NDm A100 v4 virtual machines are Azure’s flagship GPU offerings for AI and deep learning powered by NVIDIA A100 80GB Tensor Core GPUs. These instances have the most GPU memory capacity and bandwidth, backed by NVIDIA InfiniBand HDR connections to support scaling up and out. Ultimately, we ran a 530B-parameter benchmark on 175 virtual machines, resulting in a training time per step of as low as 55.7 seconds (figure1). This benchmark measures the compute efficiency and how it scales by measuring the time taken per step to train the model after steady state is reached, with a mini-batch size of one. Such outstanding speed would not have been possible without InfiniBand HDR providing excellent communication between nodes without increased latency.
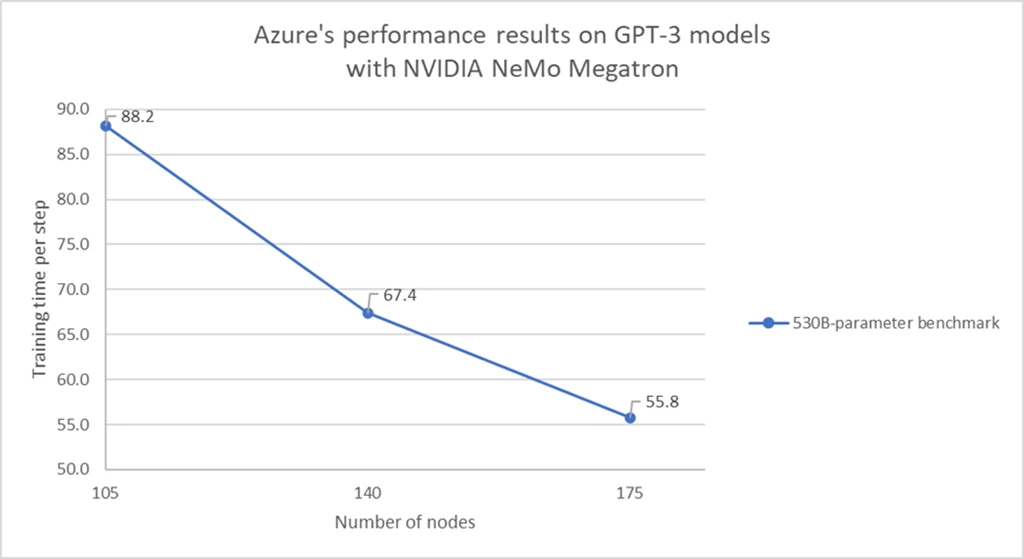
These results highlight an almost linear speed increase, guaranteeing better performance for a higher number of nodes—paramount for heavy or time-sensitive workloads. As shown by these runs with billions of parameters, customers can rest assured that Azure’s infrastructure can handle even the most difficult and complex workloads, on demand.
“Speed and scale are both key to developing large language models, and the latest release of the NVIDIA NeMo Megatron framework introduces new techniques to deliver 30 percent faster training for LLMs,” said Paresh Kharya, senior director of accelerated computing at NVIDIA. “Microsoft’s testing with NeMo Megatron 530B also shows that Azure NDm A100 v4 instances powered by NVIDIA A100 Tensor Core GPUs and NVIDIA InfiniBand networking provide a compelling option for achieving linear training speedups at massive scale.”
Showcasing Azure AI capabilities—now and in the future
Azure’s commitment is to make AI and HPC accessible to everyone. It includes, but is not limited to, providing the best AI infrastructure that scales from the smallest use cases to the heaviest workloads. As we continue to innovate to build the best platform for your AI workloads, our promise to you is to use the latest benchmarks to test our AI capabilities. These results help drive our own innovation and showcase that there is no limit to what you can do. For all your AI computing needs, Azure has you covered.
Learn more
To learn more about the results or how to recreate them, please see the following links.
- A quick start guide to benchmarking LLM models in Azure: NVIDIA NeMo Megatron—Results.
- A quick start guide to benchmarking LLM models in Azure: NVIDIA NeMo Megatron—Steps.