“When I first kicked off this Advancing Reliability blog series in my post last July, I highlighted several initiatives underway to keep improving platform availability, as part of our commitment to provide a trusted set of cloud services. One area I mentioned was fault injection, through which we’re increasingly validating that systems will perform as designed in the face of failures. Today I’ve asked our Principal Program Manager in this space, Chris Ashton, to shed some light on these broader ‘chaos engineering’ concepts, and to outline Azure examples of how we’re already applying these, together with stress testing and synthetic workloads, to improve application and service resilience.” – Mark Russinovich, CTO, Azure
Developing large-scale, distributed applications has never been easier, but there is a catch. Yes, infrastructure is provided in minutes thanks to your public cloud, there are many language options to choose from, swaths of open source code available to leverage, and abundant components and services in the marketplace to build upon. Yes, there are good reference guides that help give a leg up on your solution architecture and design, such as the Azure Well-Architected Framework and other resources in the Azure Architecture Center. But while application development is easier, there’s also an increased risk of impact from dependency disruptions. However rare, outages beyond your control could occur at any time, your dependencies could have incidents, or your key services/systems could become slow to respond. Minor disruptions in one area can be magnified or have longstanding side effects in another. These service disruptions can rob developer productivity, negatively affect customer trust, cause lost business, and even impact an organization’s bottom line.
Modern applications, and the cloud platforms upon which they are built, need to be designed and continuously validated for failure. Developers need to account for known and unknown failure conditions, applications and services must be architected for redundancy, algorithms need retry and back-off mechanisms. Systems need to be resilient to the scenarios and conditions caused by infrequent but inevitable production outages and disruptions. This post is designed to get you thinking about how best to validate typical failure conditions, including examples of how we at Microsoft validate our own systems.
Resilience
Resilience is the ability of a system to fail gracefully in the face of—and eventually recover from—disruptive events. Validating that an application, service, or platform is resilient is equally as important as building for failure. It is easy and tempting to validate the reliability of individual components in isolation and infer that the entire system will be just as reliable, but that could be a mistake. Resilience is a property of an entire system, not just its components. To understand if a system is truly resilient, it is best to measure and understand the resilience of the entire system in the environment where it will run. But how do you do this, and where do you start?
Chaos engineering and fault injection
Chaos engineering is the practice of subjecting a system to the real-world failures and dependency disruptions it will face in production. Fault injection is the deliberate introduction of failure into a system in order to validate its robustness and error handling.
Through the use of fault injection and the application of chaos engineering practices generally, architects can build confidence in their designs – and developers can measure, understand, and improve the resilience of their applications. Similarly, Site Reliability Engineers (SREs) and in fact anyone who holds their wider teams accountable in this space can ensure that their service level objectives are within target, and monitor system health in production. Likewise, operations teams can validate new hardware and datacenters before rolling out for customer use. Incorporation of chaos techniques in release validation gives everyone, including management, confidence in the systems that their organization is building.
Throughout the development process, as you are hopefully doing already, test early and test often. As you prepare to take your application or service to production, follow normal testing practices by adding and running unit, functional, stress, and integration tests. Where it makes sense, add test coverage for failure cases, and use fault injection to confirm error handling and algorithm behavior. For even greater impact, and this is where chaos engineering really comes into play, augment end-to-end workloads (such as stress tests, performance benchmarks, or a synthetic workload) with fault injection. Start in a pre-production test environment before performing experiments in production, and understand how your solution behaves in a safe environment with a synthetic workload before introducing potential impact to real customer traffic.
Healthy use of fault injection in a validation process might include one or more of the following:
- Ad hoc validation of new features in a test environment:
A developer could stand up a test virtual machine (VM) and run new code in isolation. While executing existing functional or stress tests, faults could be injected to block network access to a remote dependency (such as SQL Server) to prove that the new code handles the scenario correctly. - Automated fault injection coverage in a CI/CD pipeline, including deployment or resiliency gates:
Existing end-to-end scenario tests (such as integration or stress tests) can be augmented with fault injection. Simply insert a new step after normal execution to continue running or run again with some faults applied. The addition of faults can find issues that would normally not be found by the tests or to accelerate discovery of issues that might be found eventually. - Incident fix validation and incident regression testing:
Fault injection can be used in conjunction with a workload or manual execution to induce the same conditions that caused an incident, enabling validation of a specific incident fix or regression testing of an incident scenario. - BCDR drills in a pre-production environment:
Faults that cause database failover or take storage offline can be used in BCDR drills, to validate that systems behave appropriately in the face of these faults and that data is not lost during any failover tests. - Game days in production:
A ‘game day’ is a coordinated simulation of an outage or incident, to validate that systems handle the event correctly. This typically includes validation of monitoring systems as well as human processes that come into play during an incident. Teams that perform game days can leverage fault injection tooling, to orchestrate faults that represent a hypothetical scenario in a controlled manner.
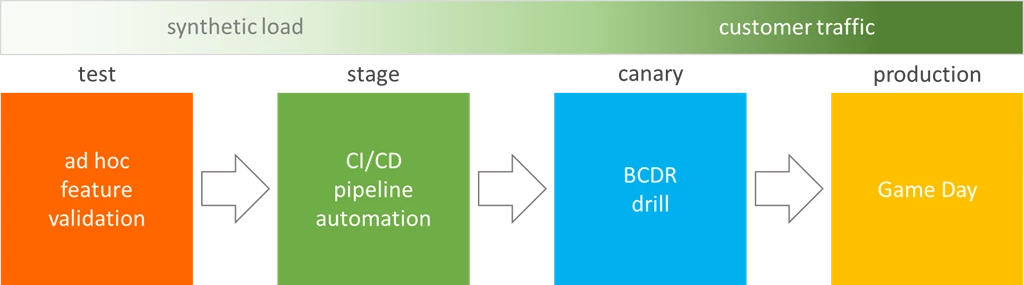
Typical release pipeline
This figure shows a typical release pipeline, and opportunities to include fault injection:
An investment in fault injection will be more successful if it is built upon a few foundational components:
- Coordinated deployment pipeline.
- Automated ARM deployments.
- Synthetic runners and synthetic end-to-end workloads.
- Monitoring, alerting, and livesite dashboards.
With these things in place, fault injection can be integrated in the deployment process with little to no additional overhead – and can be used to gate code flow on its way to production.
Localized rack power outages and equipment failures have been found as single points of failure in root cause analysis of past incidents. Learning that a service is impacted by, and not resilient to, one of these events in production is a timebound, painful, and expensive process for an on-call engineer. There are several opportunities to use fault injection to validate resilience to these failures throughout the release pipeline in a controlled environment and timeframe, which also gives more opportunity for the code author to lead an investigation of issues uncovered. A developer who has code changes or new code can create a test environment, deploy the code, and perform ad hoc experiments using functional tests and tools with faults that simulate taking dependencies offline – such as killing VMs, blocking access to services, or simply altering permissions. In a staging environment, injection of similar faults can be added to automated end-to-end and integration tests or other synthetic workloads. Test results and telemetry can then be used to determine impact of the faults and compared against baseline performance to block code flow if necessary.
In a pre-production or ‘Canary’ environment, automated runners can be used with faults that again block access to dependencies or take them offline. Monitoring, alerting, and livesite dashboards can then be used to validate that the outages were observed as well as that the system reacted and compensated for the issue—that it demonstrated resilience. In this same environment, SREs or operations teams may also perform business continuity/disaster recovery (BCDR) drills, using fault injection to take storage or databases offline and once again monitoring system metrics to validate resilience and data integrity. These same Canary activities can also be performed in production where there is real customer traffic, but doing so incurs a higher possibility of impact to customers so it is recommended only to do this after leveraging fault injection earlier in the pipeline. Establishing these practices and incorporating fault injection into a deployment pipeline allows systematic and controlled resilience validation which enables teams to mitigate issues, and improve application reliability, without impacting end customers.
Fault injection at Microsoft
At Microsoft, some teams incorporate fault injection early in their validation pipeline and automated test passes. Different teams run stress tests, performance benchmarks, or synthetic workloads in their automated validation gates as normal and a baseline is established. Then the workload is run again, this time with faults applied – such as CPU pressure, disk IO jitter, or network latency. Workload results are monitored, telemetry is scanned, crash dumps are checked, and Service Level Indicators (SLIs) are compared with Service Level Objectives (SLOs) to gauge the impact. If results are deemed a failure, code may not flow to the next stage in the pipeline.
Other Microsoft teams use fault injection in regular Business Continuity, Disaster Recovery (BCDR) drills, and Game Days. Some teams have monthly, quarterly, or half-yearly BCDR drills and use fault injection to induce a disaster and validate both the recovery process as well as the alerting, monitoring and live site processes. This is often done in a pre-production Canary environment before being used in production itself with real customer traffic. Some teams also carry out Game Days, where they come up with a hypothetical scenario, such as replication of a past incident, and use fault injection to help orchestrate it. Faults, in this case, might be more destructive—such as crashing VMs, turning off network access, causing database failover, or simulating an entire datacenter going offline. Again, normal live site monitoring and alerting are used, so your DevOps and incident management processes are also validated. To be kind to all involved, these activities are typically performed during business hours and not overnight or over a weekend.
Our operations teams also use fault injection to validate new hardware before it is deployed for customer use. Drills are performed where the power is shut off to a rack or datacenter, so the monitoring and backup systems can be observed to ensure they behave as expected.
At Microsoft, we use chaos engineering principles and fault injection techniques to increase resilience, and confidence, in the products we ship. They are used to validate the applications we deliver to customers, and the services we make available to developers. They are used to validate the underlying Azure platform itself, to test new hardware before it is deployed. Separately and together, these contribute to the overall reliability of the Azure platform—and improved quality in our services all up.
Unintended consequences
Remember, fault injection is a powerful tool and should be used with caution. Safeguards should be in place to ensure that faults introduced in a test or pre-production environment will not also affect production. The blast radius of a fault scenario should be contained to minimize impact to other components and to end customers. The ability to inject faults should have restricted access, to prevent accidents and prevent potential use by hackers with malicious intent. Fault injection can be used in production, but plan carefully, test first in pre-production, limit the blast radius, and have a failsafe to ensure that an experiment can be ended abruptly if needed. The 1986 Chernobyl nuclear accident is a sobering example of a fault injection drill gone wrong. Be careful to insulate your system from unintended consequences.
Chaos as a service?
As Mark Russinovich mentioned in this earlier blog post, our goal is to make native fault injection services available to customers and partners so they can perform the same validation on their own applications and services. This is an exciting space with so much potential to improve cloud service reliability and reduce the impact of rare but inevitable disruptions. There are many teams doing lots of interesting things in this space, and we’re exploring how best to bring all these disparate tools and faults together to make our lives easier—for our internal developers building Azure services, for built-on-Azure services like Microsoft 365, Microsoft Teams, and Dynamics, and eventually for our customers and partners to use the same tooling to wreak havoc on (and ultimately improve the resilience of) their own applications and solutions.