教學課程: 使用 Batch Explorer、儲存體總管和 Python,透過 Data Factory 執行 Batch 作業
本教學課程將逐步引導您建立和執行 Azure Data Factory 管道,該管道可執行 Azure Batch 工作負載。 Batch 節點上會執行 Python 指令碼,以取得來自 Azure Blob 儲存體容器的逗號分隔值 (CSV) 輸入、操作資料,並將輸出寫入不同的儲存體容器。 您可以使用 Batch Explorer 來建立 Batch 集區和節點,並使用 Azure 儲存體總管來處理儲存體容器和檔案。
在本教學課程中,您會了解如何:
- 使用 Batch Explorer 建立 Batch 集區和節點。
- 使用儲存體總管建立儲存體容器,並上傳輸入檔案。
- 開發 Python 指令碼以操作輸入資料,並產生輸出。
- 建立執行 Batch 工作負載的 Data Factory 管道。
- 使用 Batch Explorer 查看輸出記錄檔。
必要條件
- 具有有效訂用帳戶的 Azure 帳戶。 如果您沒有訂用帳戶,請建立免費帳戶。
- Batch 帳戶和連結的 Azure 儲存體帳戶。 您可以使用下列其中一種方法建立帳戶: Azure 入口網站 | Azure CLI | Bicep | ARM 範本 | Terraform。
- Azure Data Factory 執行個體。 若要建立 Data Factory,請遵循建立 Data Factory 中的指示。
- 已下載並安裝 Batch Explorer。
- 已下載並安裝儲存體總管。
- Python 3.7 以上版本,並使用
pip安裝 azure-storage-blob 套件。 - 從 GitHub 下載的 iris.csv 輸入資料集。
使用 Batch Explorer 建立 Batch 集區和節點
請使用 Batch Explorer 建立計算節點集區,以執行您的工作負載。
使用您的 Azure 認證登入 Batch Explorer。
選取您的 Batch 帳戶。
選取左側側邊欄上的集區,然後選取 + 圖示以新增集區。
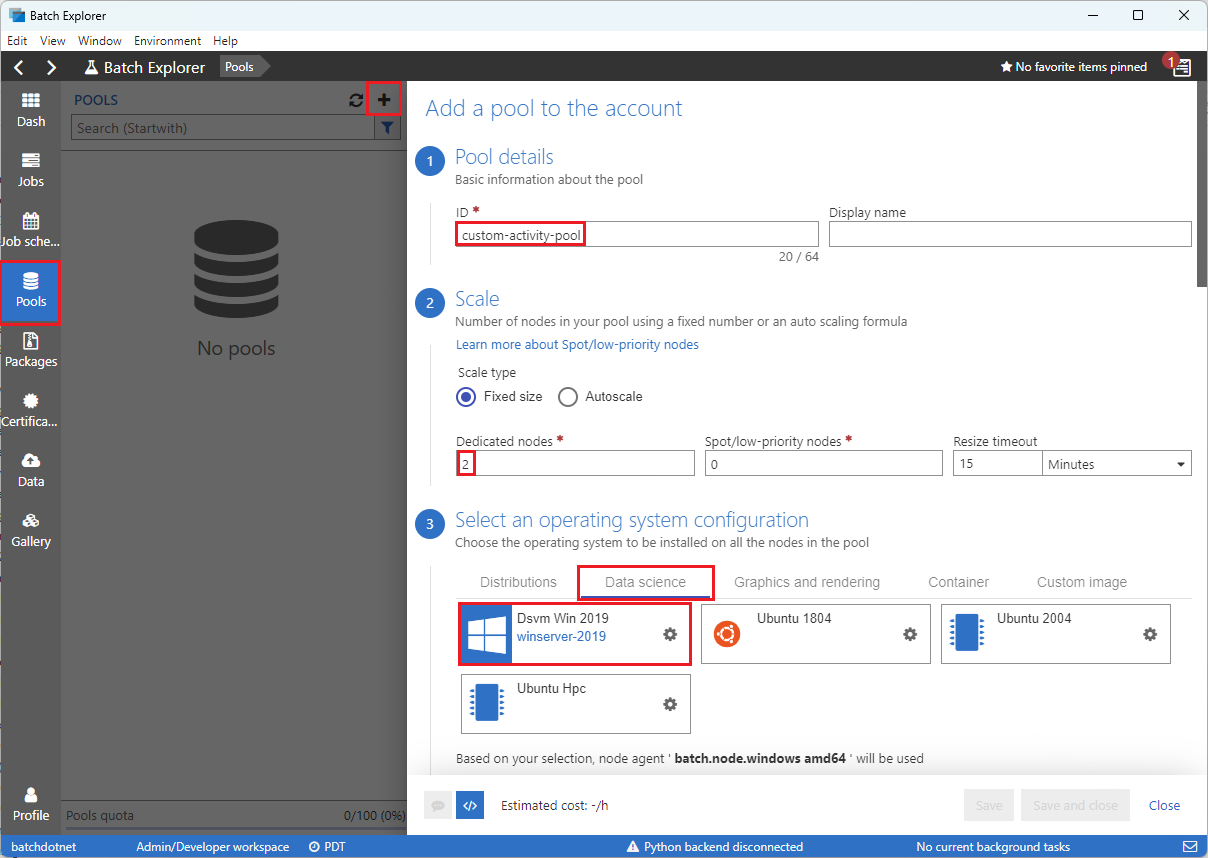
填寫 [Add a pool to the account] 表單,如下所示:
- 在 [識別碼] 下輸入 custom-activity-pool。
- 在 [專用節點] 下,輸入 2。
- 針對 [Select an operating system configuration] 選取 [資料科學] 索引標籤,然後選取 [Dsvm Win 2019]。
- 針對 [選擇虛擬機器大小]選取 [Standard_F2s_v2]。
- 針對 [啟動工作] 選取 [Add a start task]。
在 [啟動工作] 畫面的 [命令列] 下,輸入
cmd /c "pip install azure-storage-blob pandas",然後選取 [選取]。 此命令會在每個節點啟動時,在每個節點上安裝azure-storage-blob套件。
選取儲存後關閉。

使用儲存體總管建立 Blob 容器
請使用儲存體總管建立 Blob 容器來儲存輸入和輸出檔案,然後上傳您的輸入檔案。
- 使用您的 Azure 認證登入儲存體總管。
- 在左側側邊欄中,找出並展開連結至 Batch 帳戶的儲存體帳戶。
- 以滑鼠右鍵按一下 [Blob 容器],然後選取 [建立 Blob 容器],或從側邊欄底部的 [動作] 選取 [建立 Blob 容器]。
- 在輸入欄位中輸入 input。
- 建立名為 output 的另一個 Blob 容器。
- 選取 [輸入] 容器,然後在右窗格中選取 [上傳]>[上傳檔案]。
- 在 [上傳檔案] 畫面的 [選取的檔案] 底下,選取輸入欄位旁的省略符號 ...。
- 流覽至下載 iris.csv 檔案的位置,然後依序選取 [開啟] 和 [上傳]。

開發 Python 指令碼
下列 Python 指令碼會從儲存體總管輸入容器載入 iris.csv 資料集檔案和操作資料,並將結果儲存至輸出容器。
指令碼必須使用 Azure 記憶體帳戶 (連結至您的 Batch 帳戶) 的連接字串。 若要取得連接字串:
- 在 Azure 入口網站中,搜尋並選取連結至 Batch 帳戶的儲存體帳戶名稱。
- 在儲存體帳戶的頁面上,從左側導覽的 [安全性 + 網路] 下選取 [存取金鑰]。
- 在 [key1] 底下,選取連接字串旁的 [顯示],然後選取複製圖示來複製連接字符串。
將連接字串貼入下列指令碼,並取代 <storage-account-connection-string> 預留位置。 將指令碼儲存為名為 main.py 的檔案。
重要
不建議您在應用程式來源中公開帳戶金鑰,以供實際執行使用。 您應該限制認證的存取,並使用變數或組態檔在程式碼中參考認證。 最好將 Batch 和儲存體帳戶金鑰儲存在 Azure Key Vault 中。
# Load libraries
from azure.storage.blob import BlobClient
import pandas as pd
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Load iris dataset from the task node
df = pd.read_csv("iris.csv")
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
在本機執行指令碼,以測試及驗證功能。
python main.py
指令碼應該會產生名為 iris_setosa.csv 的輸出檔案,其中僅包含具有 Species = setosa 的資料記錄。 確認其運作正常之後,請將 main.py 指令檔檔案上傳至儲存體總管輸入容器。
建立 Data Factory 管道
建立及驗證使用 Python 指令碼的 Data Factory 管道。
取得帳戶資訊
Data Factory 管道會使用您的 Batch 和儲存體帳戶名稱、帳戶金鑰值和 Batch 帳戶端點。 若要從 Azure 入口網站中取得此資訊:
從 Azure 搜尋服務列中搜尋並選取您的 Batch 帳戶名稱。
在您的 Batch 帳戶頁面上,從左側導覽中選取 [金鑰]。
在 [金鑰] 頁面上,複製下列值:
- Batch 帳戶
- 帳戶端點
- 主要存取金鑰
- 儲存體帳戶名稱
- Key1
建立並執行管線
如果 Azure Data Factory Studio 尚未執行,請在 Azure 入口網站的 [Data Factory] 頁面上選取 [啟動工作室]。
在 Data Factory Studio 中,選取左側導覽中的撰寫鉛筆圖示。
在 [Factory 資源] 下選取 + 圖示,然後選取 [管道]。
在右側的 [屬性] 窗格中,將管道的名稱變更為Run Python。
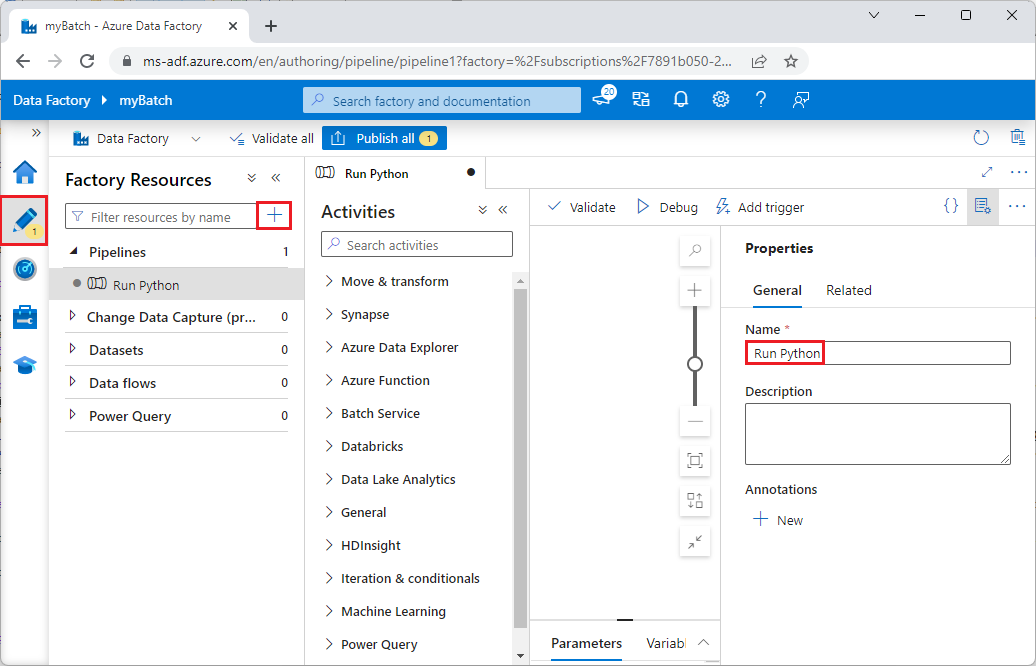
在 [活動] 窗格中展開 [Batch 服務],並將 [自訂] 活動拖曳至管道設計工具介面。
在設計工具畫布下方 [一般] 索引標籤的 [名稱] 底下,輸入 testPipeline。
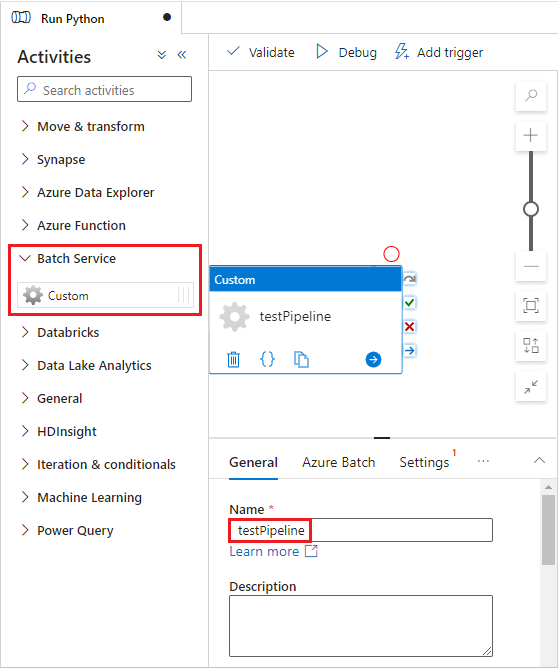
依序選取 [Azure Batch] 索引標籤和 [新增]。
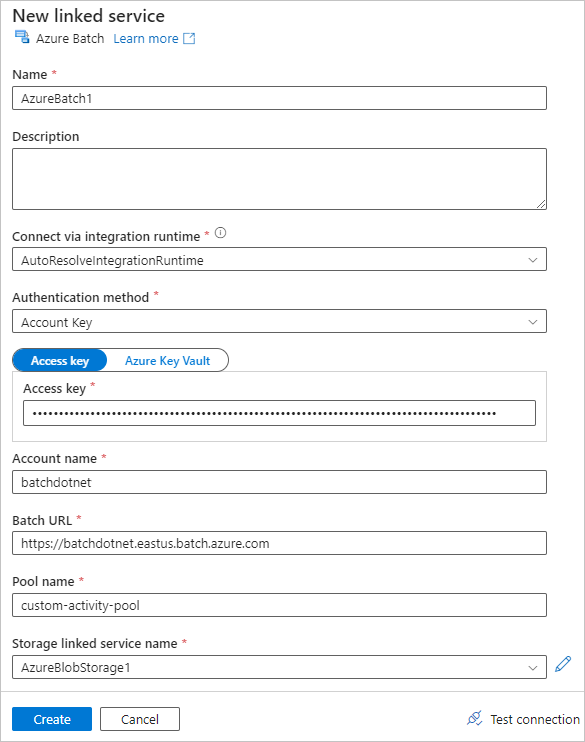
填寫 [新增連結服務] 表單,如下所示:
- 名稱: 為連結服務輸入名稱,例如 AzureBatch1。
- 存取金鑰: 輸入您從 Batch 帳戶複製的主要存取金鑰。
- 帳戶名稱: 輸入 Batch 帳戶的名稱。
- Batch URL: 輸入您從 Batch 帳戶複製的帳戶端點,例如
https://batchdotnet.eastus.batch.azure.com。 - 集區名稱: 輸入 custom-activity-pool,這是您在 Batch Explorer 中建立的集區。
- 記憶體帳戶連結服務名稱: 選取 [新增]。 在下一個畫面上輸入連結儲存體服務的名稱,例如 AzureBlobStorage1,選取您的 Azure 訂用帳戶和連結的儲存體帳戶,然後選取 [建立]。
在 Batch [新增連結服務] 畫面底部,選取 [測試連接]。 在連接成功後,請選取 [建立]。
選取 [設定] 索引標籤,然後輸入或選取下列設定:
- 命令: 輸入
cmd /C python main.py。 - 資源連結服務: 選取您所建立的連結儲存體服務,例如 AzureBlobStorage1,並測試連結以確定連結成功。
- 資料夾路徑: 選取資料夾圖示,然後依序選取輸入容器和 [確定]。 此資料夾的檔案會在執行 Python 指令碼之前,從容器下載到集區節點。
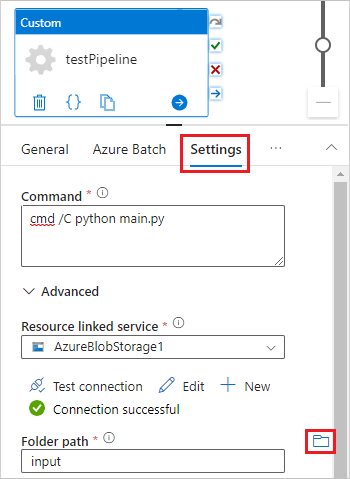
- 命令: 輸入
選取管道工具列上的 [驗證] 以驗證管道。
選取 [偵錯] 來測試管道,並確定其運作正常。
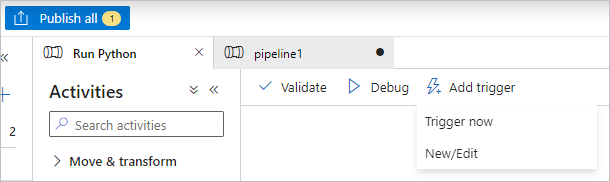
選取 [全部發佈] 以發佈管道。
選取 [新增觸發程序],然後選取 [立即觸發] 以執行管道,或選取 [新增/編輯] 以排程管道。

使用 Batch Explorer 檢視記錄檔
如果執行管道會產生警告或錯誤,您可以使用 Batch Explorer 來查看 stdout.txt 和 stderr.txt 輸出檔案以取得詳細資訊。
- 從 Batch Explorer 的左側側邊欄選取 [作業]。
- 選取 [adfv2-custom-activity-pool] 作業。
- 選取有失敗結束代碼的工作。
- 檢視 stdout.txt 和 stderr.txt 檔案,以調查和診斷問題。
清除資源
Batch 帳戶、作業和工作為免費提供,但計算節點即使未執行作業,依然會產生費用。 最好只視需要配置節點集區,並在使用完成後刪除集區。 刪除集區時,也會刪除節點上的所有工作輸出和節點本身。
輸入和輸出檔案會保留在儲存體帳戶中,而且可能會產生費用。 當您不再需要檔案時,即可刪除檔案或容器。 當您不再需要 Batch 帳戶和連結的儲存體帳戶時,您可以加以刪除。
下一步
在本教學課程中,您已了解如何搭配 Batch Explorer、儲存體總管和 Data Factory 使用 Python 指令碼,以執行 Batch 工作負載。 如需 Data Factory 的詳細資訊,請參閱什麼是 Azure Data Factory?