Секционирование выходных данных пользовательского большого двоичного объекта Azure Stream Analytics
Azure Stream Analytics поддерживает секционирование выходных данных пользовательского большого двоичного объекта с использованием настраиваемых полей или атрибутов и пользовательских шаблонов пути даты и времени.
Настраиваемое поле или атрибуты
Настраиваемое поле или входные атрибуты улучшают рабочие нисходящие процессы обработки данных и отчетность, позволяя больше управлять выходными данными.
Параметры ключа раздела
Ключ секции или имя столбца, используемые для секционирования входных данных, могут содержать любые символы, допустимые в именах больших двоичных объектов. Вложенные поля нельзя использовать в качестве ключа секции, если они не используются в сочетании с псевдонимами, но для создания иерархии файлов можно использовать определенные символы. Например, следующий запрос позволяет создать столбец, который объединяет данные из двух других столбцов в уникальный ключ секции.
SELECT name, id, CONCAT(name, "/", id) AS nameid
Ключ секции должен иметь тип NVARCHAR(MAX), BIGINT, FLOAT или BIT (уровень совместимости 1.2 или выше). Типы DateTime, Array и Records не поддерживаются, но могут использоваться в качестве ключей секций, если они преобразуются в строки. Дополнительные сведения см. в статье Типы данных Azure Stream Analytics.
Пример
Предположим, что задание берет входные данные из сеансов пользователя в реальном времени, подключенного к службе внешних компьютерных игр, где полученные данные содержат столбец client_id для идентификации сеансов. Чтобы разделить данные по client_id, установите в поле шаблона пути BLOB-объекта {client_id} маркера раздела в свойствах выходных данных большого двоичного объекта при создании задания. Поскольку данные с различными значениями client_id проходят через задание Stream Analytics, данные сохраняются в отдельных папках, в зависимости от единого значения client_id, предназначенного папке.

Аналогично если входные данные задания были данными из миллионов датчиков, где каждый из них содержал свой sensor_id, шаблон пути был равен значению {sensor_id} , чтобы разделить данные каждого датчика в разные папки.
При использовании REST API выходной раздел JSON-файла, используемого для этого запроса, может выглядеть следующим образом:
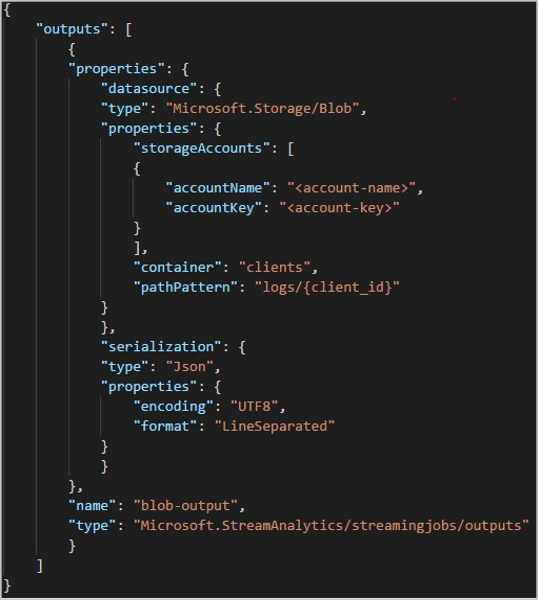
После запуска clients задания контейнер может выглядеть следующим образом:
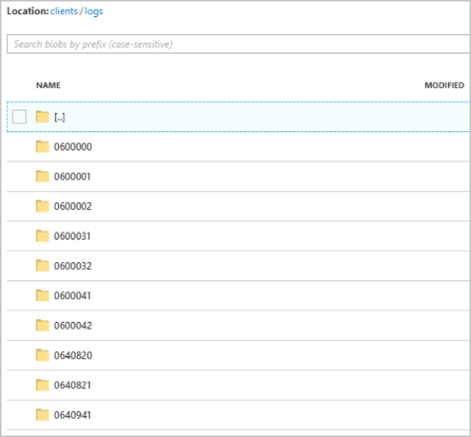
Каждая папка может содержать несколько больших двоичных объектов, где каждый из них содержит одну или несколько записей. В приведенном выше примере в папке есть один большой двоичный объект с меткой "06000000" со следующим содержимым:
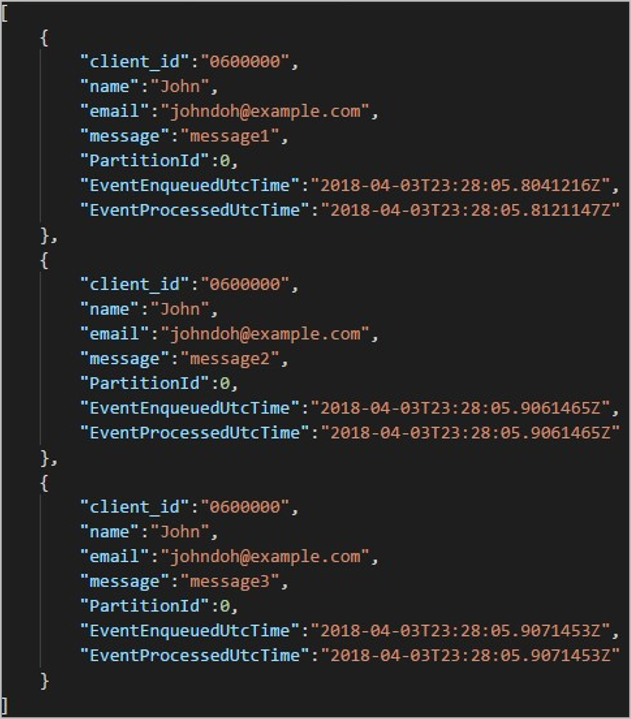
Обратите внимание, что каждая запись в большом двоичном объекте содержит столбец client_id, который соответствует названию папки, так как столбец, используемый для разделения выходных данных в выходном пути, был обозначен как client_id.
Ограничения
В свойстве выходных данных большого двоичного объекта шаблона пути допускается только один пользовательский ключ раздела. Следующие шаблоны пути являются допустимыми:
- cluster1/{date}/{aFieldInMyData}
- cluster1/{time}/{aFieldInMyData}
- cluster1/{aFieldInMyData}
- cluster1/{date}/{time}/{aFieldInMyData}
Если клиенты хотят использовать несколько полей ввода, они могут создать составной ключ в запросе для пользовательского раздела пути, содержащегося в выходных данных BLOB-объекта, с помощью операции CONCAT. Например: выберите concat (col1, col2) в качестве compositeColumn в blobOutput из входных данных. Затем можно указать compositeColumn в качестве пользовательского пути в хранилище BLOB-объектов.
Ключи секций не учитывают регистр, поэтому ключи секций, такие как
Johnиjohn, эквивалентны. Кроме того, выражения нельзя использовать в качестве ключей секций. Например, {columnA + columnB} не работает.Если входной поток состоит из записей с кратностью ключа секции ниже 8000, записи добавляются к существующим BLOB-объектам и создаются только при необходимости. Если кратность превышает 8000, нет никакой гарантии, что существующие blob-объекты будут записаны в, а новые большие двоичные объекты не будут созданы для произвольного количества записей с тем же ключом секции.
Если выходные данные большого двоичного объекта настроены как неизменяемые, Stream Analytics создает новый BLOB-объект при каждой отправке данных.
Пользовательские шаблоны пути даты и времени
Пользовательские шаблоны даты и времени в пути позволяют указать формат выходных данных, который соответствует соглашениям о потоковой передаче Hive, предоставляя Azure Stream Analytics возможность отправлять данные в Azure HDInsight и Azure Databricks для последующей обработки. Пользовательские шаблоны даты и времени в пути легко реализуются, если ввести в поле "Префикс пути" выходных данных хранилища BLOB-объектов ключевое слово datetime вместе со спецификатором формата. Например, {datetime:yyyy}.
Поддерживаемые токены
Следующие токены спецификатора формата могут использоваться отдельно или в комбинациях для настройки пользовательских форматов даты и времени:
| Спецификатор формата | Описание | Результаты для примера 2018-01-02T10:06:08 |
|---|---|---|
| {datetime:yyyy} | Год как четырехзначное число | 2018 |
| {datetime:MM} | Месяц от 01 до 12 | 01 |
| {datetime:M} | Месяц от 1 до 12 | 1 |
| {datetime:dd} | День от 01 до 31 | 02 |
| {datetime:d} | День от 1 до 31 | 2 |
| {datetime:HH} | Часы в 24-часовом формате, от 00 до 23 | 10 |
| {datetime:mm} | Минуты от 00 до 60 | 06 |
| {datetime:m} | Минуты от 0 до 60 | 6 |
| {datetime:ss} | Секунды от 00 до 60 | 08 |
Если вы не хотите использовать настраиваемые шаблоны DateTime, можно добавить маркер {date} и (или) {time} в префикс пути, чтобы создать раскрывающийся список со встроенными форматами DateTime.
Расширяемость и ограничения
Вы можете использовать столько токенов {datetime:<specifier>} в шаблоне пути, сколько нужно, пока не достигнете предельного числа знаков в префиксе пути. Спецификаторы формата не могут быть объединены в один токен, за исключением комбинаций, уже перечисленных в раскрывающемся списке даты и времени.
Для раздела пути logs/MM/dd:
| Допустимое выражение | Недопустимое выражение |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Вы можете использовать один и тот же спецификатор формата несколько раз в префиксе пути. Токен должен повторяться каждый раз.
Соглашения для потоковой передачи Hive
Пользовательские шаблоны пути для хранилища BLOB-объектов могут использоваться с соглашением для потоковой передачи Hive, в которой ожидается, что в имени папки будет пометка column=.
Например, year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Пользовательский тип выходных данных устраняет проблему изменения таблиц и добавления разделов для передачи данных между Azure Stream Analytics и Hive вручную. Вместо этого многие папки можно добавлять автоматически, используя:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Пример
Создайте учетную запись хранения, группу ресурсов, задание Stream Analytics и источник входных данных, следуя инструкциям из краткого руководства Создание задания Stream Analytics с помощью портала Azure. Используйте те же примеры данных, которые используются в кратком руководстве, также доступном на сайте GitHub.
Создайте приемник выходных данных больших двоичных объектов со следующей конфигурацией:
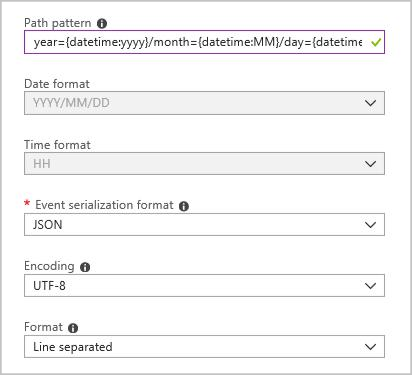
Шаблон полного пути выглядит следующим образом:
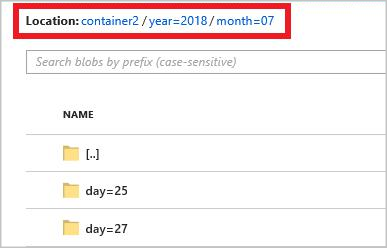
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
Когда вы запускаете задание, в контейнере больших двоичных объектов создается структура папок, основанная на шаблоне пути. Вы можете детализировать до уровня дня.